Kelvin Zhenghao Li, Tuyet Thao Nguyen, Heather E Moss
{"title":"眼底照片视盘肿胀识别的视觉语言模型性能。","authors":"Kelvin Zhenghao Li, Tuyet Thao Nguyen, Heather E Moss","doi":"10.3389/fdgth.2025.1660887","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Vision language models (VLMs) combine image analysis capabilities with large language models (LLMs). Because of their multimodal capabilities, VLMs offer a clinical advantage over image classification models for the diagnosis of optic disc swelling by allowing a consideration of clinical context. In this study, we compare the performance of non-specialty-trained VLMs with different prompts in the classification of optic disc swelling on fundus photographs.</p><p><strong>Methods: </strong>A diagnostic test accuracy study was conducted utilizing an open-sourced dataset. Five different prompts (increasing in context) were used with each of five different VLMs (Llama 3.2-vision, LLaVA-Med, LLaVA, GPT-4o, and DeepSeek-4V), resulting in 25 prompt-model pairs. The performance of VLMs in classifying photographs with and without optic disc swelling was measured using Youden's index (YI), F1 score, and accuracy rate.</p><p><strong>Results: </strong>A total of 779 images of normal optic discs and 295 images of swollen discs were obtained from an open-source image database. Among the 25 prompt-model pairs, valid response rates ranged from 7.8% to 100% (median 93.6%). Diagnostic performance ranged from YI: 0.00 to 0.231 (median 0.042), F1 score: 0.00 to 0.716 (median 0.401), and accuracy rate: 27.5 to 70.5% (median 58.8%). The best-performing prompt-model pair was GPT-4o with role-playing with Chain-of-Thought and few-shot prompting. On average, Llama 3.2-vision performed the best (average YI across prompts 0.181). There was no consistent relationship between the amount of information given in the prompt and the model performance.</p><p><strong>Conclusions: </strong>Non-specialty-trained VLMs could classify photographs of swollen and normal optic discs better than chance, with performance varying by model. Increasing prompt complexity did not consistently improve performance. Specialty-specific VLMs may be necessary to improve ophthalmic image analysis performance.</p>","PeriodicalId":73078,"journal":{"name":"Frontiers in digital health","volume":"7 ","pages":"1660887"},"PeriodicalIF":3.2000,"publicationDate":"2025-08-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12415036/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of vision language models for optic disc swelling identification on fundus photographs.\",\"authors\":\"Kelvin Zhenghao Li, Tuyet Thao Nguyen, Heather E Moss\",\"doi\":\"10.3389/fdgth.2025.1660887\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Vision language models (VLMs) combine image analysis capabilities with large language models (LLMs). Because of their multimodal capabilities, VLMs offer a clinical advantage over image classification models for the diagnosis of optic disc swelling by allowing a consideration of clinical context. In this study, we compare the performance of non-specialty-trained VLMs with different prompts in the classification of optic disc swelling on fundus photographs.</p><p><strong>Methods: </strong>A diagnostic test accuracy study was conducted utilizing an open-sourced dataset. Five different prompts (increasing in context) were used with each of five different VLMs (Llama 3.2-vision, LLaVA-Med, LLaVA, GPT-4o, and DeepSeek-4V), resulting in 25 prompt-model pairs. The performance of VLMs in classifying photographs with and without optic disc swelling was measured using Youden's index (YI), F1 score, and accuracy rate.</p><p><strong>Results: </strong>A total of 779 images of normal optic discs and 295 images of swollen discs were obtained from an open-source image database. Among the 25 prompt-model pairs, valid response rates ranged from 7.8% to 100% (median 93.6%). Diagnostic performance ranged from YI: 0.00 to 0.231 (median 0.042), F1 score: 0.00 to 0.716 (median 0.401), and accuracy rate: 27.5 to 70.5% (median 58.8%). The best-performing prompt-model pair was GPT-4o with role-playing with Chain-of-Thought and few-shot prompting. On average, Llama 3.2-vision performed the best (average YI across prompts 0.181). There was no consistent relationship between the amount of information given in the prompt and the model performance.</p><p><strong>Conclusions: </strong>Non-specialty-trained VLMs could classify photographs of swollen and normal optic discs better than chance, with performance varying by model. Increasing prompt complexity did not consistently improve performance. Specialty-specific VLMs may be necessary to improve ophthalmic image analysis performance.</p>\",\"PeriodicalId\":73078,\"journal\":{\"name\":\"Frontiers in digital health\",\"volume\":\"7 \",\"pages\":\"1660887\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2025-08-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12415036/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fdgth.2025.1660887\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdgth.2025.1660887","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Performance of vision language models for optic disc swelling identification on fundus photographs.
Introduction: Vision language models (VLMs) combine image analysis capabilities with large language models (LLMs). Because of their multimodal capabilities, VLMs offer a clinical advantage over image classification models for the diagnosis of optic disc swelling by allowing a consideration of clinical context. In this study, we compare the performance of non-specialty-trained VLMs with different prompts in the classification of optic disc swelling on fundus photographs.
Methods: A diagnostic test accuracy study was conducted utilizing an open-sourced dataset. Five different prompts (increasing in context) were used with each of five different VLMs (Llama 3.2-vision, LLaVA-Med, LLaVA, GPT-4o, and DeepSeek-4V), resulting in 25 prompt-model pairs. The performance of VLMs in classifying photographs with and without optic disc swelling was measured using Youden's index (YI), F1 score, and accuracy rate.
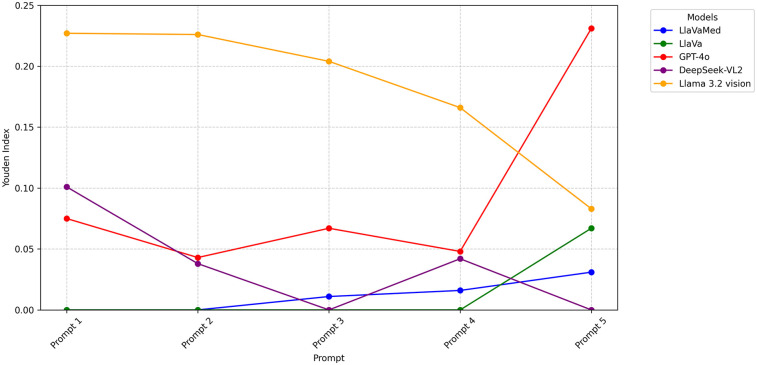
Results: A total of 779 images of normal optic discs and 295 images of swollen discs were obtained from an open-source image database. Among the 25 prompt-model pairs, valid response rates ranged from 7.8% to 100% (median 93.6%). Diagnostic performance ranged from YI: 0.00 to 0.231 (median 0.042), F1 score: 0.00 to 0.716 (median 0.401), and accuracy rate: 27.5 to 70.5% (median 58.8%). The best-performing prompt-model pair was GPT-4o with role-playing with Chain-of-Thought and few-shot prompting. On average, Llama 3.2-vision performed the best (average YI across prompts 0.181). There was no consistent relationship between the amount of information given in the prompt and the model performance.
Conclusions: Non-specialty-trained VLMs could classify photographs of swollen and normal optic discs better than chance, with performance varying by model. Increasing prompt complexity did not consistently improve performance. Specialty-specific VLMs may be necessary to improve ophthalmic image analysis performance.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


