Nitin Chetla, Sai S Samayamanthula, Joseph He Chang, Arnold Y Leigh, Sinan Akosman, Mihir Tandon, Tamer R Hage, Michael Cusick
{"title":"利用彩色眼底照片评估ChatGPT-4 Omni在糖尿病视网膜病变眼底镜分级中的诊断能力。","authors":"Nitin Chetla, Sai S Samayamanthula, Joseph He Chang, Arnold Y Leigh, Sinan Akosman, Mihir Tandon, Tamer R Hage, Michael Cusick","doi":"10.2147/OPTH.S517238","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Diabetic retinopathy (DR) is a leading cause of vision loss in working-age adults. Despite the importance of early DR detection, only 60% of patients with diabetes receive recommended annual screenings due to limited eye care provider capacity. FDA-approved AI systems were developed to meet the growing demand for DR screening; however, high costs and specialized equipment limit accessibility. More accessible and equally as accurate AI systems need to be evaluated to combat this disparity. This study evaluated the diagnostic accuracy of ChatGPT-4 Omni (GPT-4o) in classifying DR from color fundus photographs (CFPs) to assess its potential as a low-cost alternative screening tool.</p><p><strong>Methods: </strong>We utilized the publicly available EyePACS DR detection competition dataset from Kaggle, which includes 2,500 CFPs representing no DR, mild DR, moderate DR, severe DR, and proliferative DR. Each image was presented to GPT-4o with 1 of 8 prompts designed to enhance the model's accuracy. The results were analyzed through confusion matrices, and metrics such as accuracy, precision, sensitivity, specificity, and F1 scores were calculated to evaluate performance.</p><p><strong>Results: </strong>In prompts 1-3, GPT-4o showed a strong bias towards classifying images as no DR, with an average accuracy of 51.0%, while accuracy for other stages ranged from 70% to 80%. GPT-4o struggled with misclassifications, particularly between adjacent DR levels. It performed best in detecting proliferative DR (Level 4), achieving an F1 score above 0.3 and accuracy exceeding 80%. In binary classification tasks (Prompts 4.1-4.4), GPT-4o's performance improved, though it still had difficulty distinguishing mild DR (49.8% accuracy). When compared to FDA-approved AI systems, GPT-4o's sensitivity (47.7%) and specificity (73.8%) were significantly lower.</p><p><strong>Conclusion: </strong>While GPT-4o shows promise identifying severe DR, limitations in distinguishing early stages exist and highlight the need for further refinement before clinical usage in DR screening. Unlike traditional CNN-based tools like IDx-DR, GPT-4o is a multimodal foundation model with a fundamentally different architecture and training process, which may contribute to its diagnostic limitations. GPT-4o and other LLMs are not designed to learn about important DR features like microaneurysms or hemorrhages using pixel data which is why they may struggle to detect DR compared to CNN models.</p>","PeriodicalId":93945,"journal":{"name":"Clinical ophthalmology (Auckland, N.Z.)","volume":"19 ","pages":"3103-3112"},"PeriodicalIF":0.0000,"publicationDate":"2025-08-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411675/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing the Diagnostic Capabilities of ChatGPT-4 Omni in Grading Diabetic Retinopathy Fundoscopy Using Color Fundus Photographs.\",\"authors\":\"Nitin Chetla, Sai S Samayamanthula, Joseph He Chang, Arnold Y Leigh, Sinan Akosman, Mihir Tandon, Tamer R Hage, Michael Cusick\",\"doi\":\"10.2147/OPTH.S517238\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Diabetic retinopathy (DR) is a leading cause of vision loss in working-age adults. Despite the importance of early DR detection, only 60% of patients with diabetes receive recommended annual screenings due to limited eye care provider capacity. FDA-approved AI systems were developed to meet the growing demand for DR screening; however, high costs and specialized equipment limit accessibility. More accessible and equally as accurate AI systems need to be evaluated to combat this disparity. This study evaluated the diagnostic accuracy of ChatGPT-4 Omni (GPT-4o) in classifying DR from color fundus photographs (CFPs) to assess its potential as a low-cost alternative screening tool.</p><p><strong>Methods: </strong>We utilized the publicly available EyePACS DR detection competition dataset from Kaggle, which includes 2,500 CFPs representing no DR, mild DR, moderate DR, severe DR, and proliferative DR. Each image was presented to GPT-4o with 1 of 8 prompts designed to enhance the model's accuracy. The results were analyzed through confusion matrices, and metrics such as accuracy, precision, sensitivity, specificity, and F1 scores were calculated to evaluate performance.</p><p><strong>Results: </strong>In prompts 1-3, GPT-4o showed a strong bias towards classifying images as no DR, with an average accuracy of 51.0%, while accuracy for other stages ranged from 70% to 80%. GPT-4o struggled with misclassifications, particularly between adjacent DR levels. It performed best in detecting proliferative DR (Level 4), achieving an F1 score above 0.3 and accuracy exceeding 80%. In binary classification tasks (Prompts 4.1-4.4), GPT-4o's performance improved, though it still had difficulty distinguishing mild DR (49.8% accuracy). When compared to FDA-approved AI systems, GPT-4o's sensitivity (47.7%) and specificity (73.8%) were significantly lower.</p><p><strong>Conclusion: </strong>While GPT-4o shows promise identifying severe DR, limitations in distinguishing early stages exist and highlight the need for further refinement before clinical usage in DR screening. Unlike traditional CNN-based tools like IDx-DR, GPT-4o is a multimodal foundation model with a fundamentally different architecture and training process, which may contribute to its diagnostic limitations. GPT-4o and other LLMs are not designed to learn about important DR features like microaneurysms or hemorrhages using pixel data which is why they may struggle to detect DR compared to CNN models.</p>\",\"PeriodicalId\":93945,\"journal\":{\"name\":\"Clinical ophthalmology (Auckland, N.Z.)\",\"volume\":\"19 \",\"pages\":\"3103-3112\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-08-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411675/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Clinical ophthalmology (Auckland, N.Z.)\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2147/OPTH.S517238\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Clinical ophthalmology (Auckland, N.Z.)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2147/OPTH.S517238","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
Assessing the Diagnostic Capabilities of ChatGPT-4 Omni in Grading Diabetic Retinopathy Fundoscopy Using Color Fundus Photographs.
Purpose: Diabetic retinopathy (DR) is a leading cause of vision loss in working-age adults. Despite the importance of early DR detection, only 60% of patients with diabetes receive recommended annual screenings due to limited eye care provider capacity. FDA-approved AI systems were developed to meet the growing demand for DR screening; however, high costs and specialized equipment limit accessibility. More accessible and equally as accurate AI systems need to be evaluated to combat this disparity. This study evaluated the diagnostic accuracy of ChatGPT-4 Omni (GPT-4o) in classifying DR from color fundus photographs (CFPs) to assess its potential as a low-cost alternative screening tool.
Methods: We utilized the publicly available EyePACS DR detection competition dataset from Kaggle, which includes 2,500 CFPs representing no DR, mild DR, moderate DR, severe DR, and proliferative DR. Each image was presented to GPT-4o with 1 of 8 prompts designed to enhance the model's accuracy. The results were analyzed through confusion matrices, and metrics such as accuracy, precision, sensitivity, specificity, and F1 scores were calculated to evaluate performance.
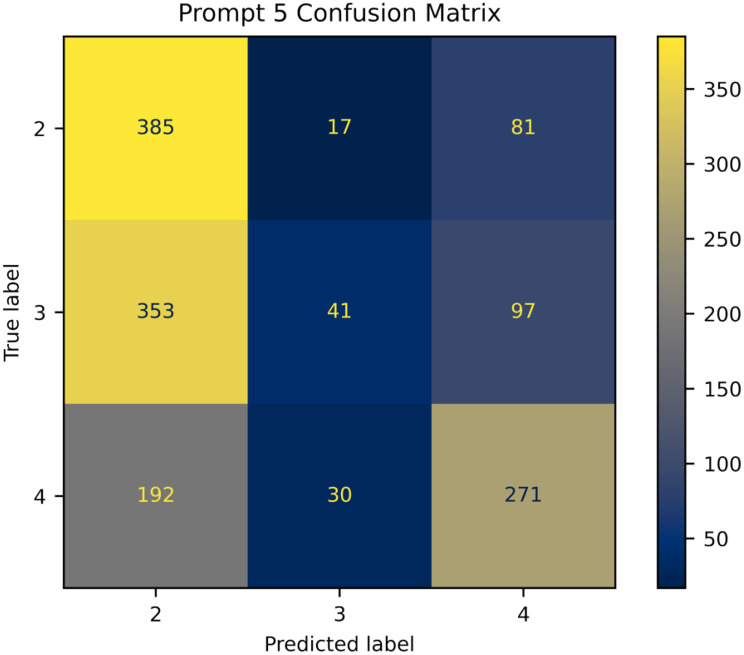
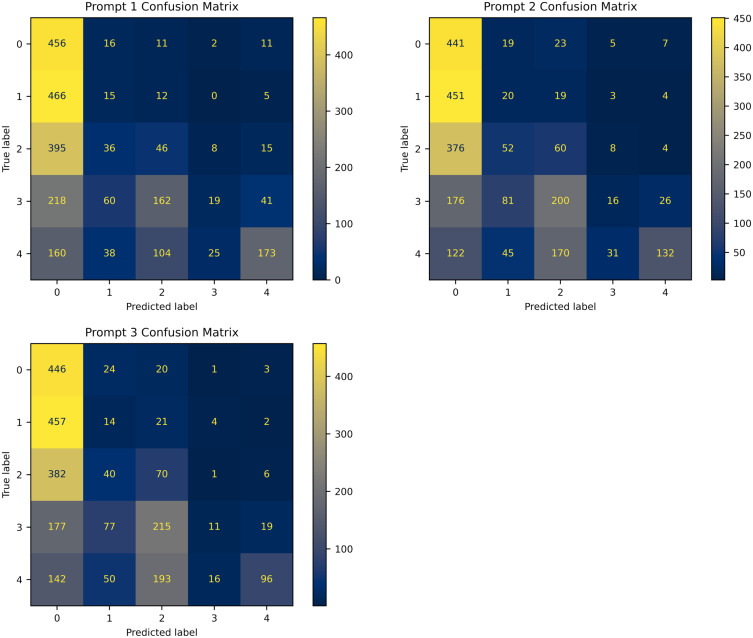
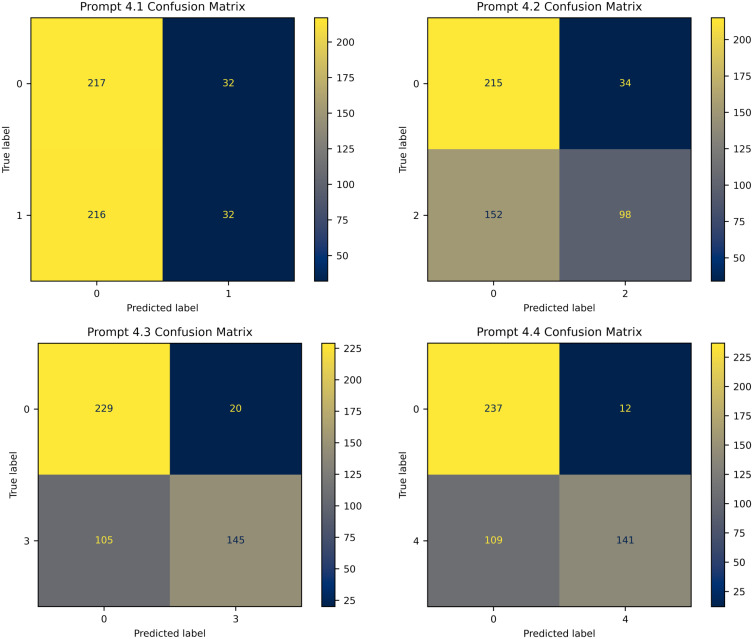
Results: In prompts 1-3, GPT-4o showed a strong bias towards classifying images as no DR, with an average accuracy of 51.0%, while accuracy for other stages ranged from 70% to 80%. GPT-4o struggled with misclassifications, particularly between adjacent DR levels. It performed best in detecting proliferative DR (Level 4), achieving an F1 score above 0.3 and accuracy exceeding 80%. In binary classification tasks (Prompts 4.1-4.4), GPT-4o's performance improved, though it still had difficulty distinguishing mild DR (49.8% accuracy). When compared to FDA-approved AI systems, GPT-4o's sensitivity (47.7%) and specificity (73.8%) were significantly lower.
Conclusion: While GPT-4o shows promise identifying severe DR, limitations in distinguishing early stages exist and highlight the need for further refinement before clinical usage in DR screening. Unlike traditional CNN-based tools like IDx-DR, GPT-4o is a multimodal foundation model with a fundamentally different architecture and training process, which may contribute to its diagnostic limitations. GPT-4o and other LLMs are not designed to learn about important DR features like microaneurysms or hemorrhages using pixel data which is why they may struggle to detect DR compared to CNN models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


