Maram Elzayyat, Janatul Naeim Mohammad, Sami Zaqout
{"title":"评估法学硕士生成与专家创建的临床解剖学mcq:医学教育中基于学生感知的比较研究。","authors":"Maram Elzayyat, Janatul Naeim Mohammad, Sami Zaqout","doi":"10.1080/10872981.2025.2554678","DOIUrl":null,"url":null,"abstract":"<p><p>Large language models (LLMs) such as ChatGPT and Gemini are increasingly used to generate educational content in medical education, including multiple-choice questions (MCQs), but their effectiveness compared to expert-written questions remains underexplored, particularly in anatomy. We conducted a cross-sectional, mixed-methods study involving Year 2-4 medical students at Qatar University, where participants completed and evaluated three anonymized MCQ sets-authored by ChatGPT, Google-Gemini, and a clinical anatomist-across 17 quality criteria. Descriptive and chi-square analyses were performed, and optional feedback was reviewed thematically. Among 48 participants, most rated the three MCQ sources as equally effective, although ChatGPT was more often preferred for helping students identify and confront their knowledge gaps through challenging distractors and diagnostic insight, while expert-written questions were rated highest for deeper analytical thinking. A significant variation in preferences was observed across sources (χ² (64) = 688.79, <i>p</i> < .001). Qualitative feedback emphasized the need for better difficulty calibration and clearer distractors in some AI-generated items. Overall, LLM-generated anatomy MCQs can closely match expert-authored ones in learner-perceived value and may support deeper engagement, but expert review remains critical to ensure clarity and alignment with curricular goals. A hybrid AI-human workflow may provide a promising path for scalable, high-quality assessment design in medical education.</p>","PeriodicalId":47656,"journal":{"name":"Medical Education Online","volume":"30 1","pages":"2554678"},"PeriodicalIF":3.8000,"publicationDate":"2025-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12404065/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing LLM-generated vs. expert-created clinical anatomy MCQs: a student perception-based comparative study in medical education.\",\"authors\":\"Maram Elzayyat, Janatul Naeim Mohammad, Sami Zaqout\",\"doi\":\"10.1080/10872981.2025.2554678\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Large language models (LLMs) such as ChatGPT and Gemini are increasingly used to generate educational content in medical education, including multiple-choice questions (MCQs), but their effectiveness compared to expert-written questions remains underexplored, particularly in anatomy. We conducted a cross-sectional, mixed-methods study involving Year 2-4 medical students at Qatar University, where participants completed and evaluated three anonymized MCQ sets-authored by ChatGPT, Google-Gemini, and a clinical anatomist-across 17 quality criteria. Descriptive and chi-square analyses were performed, and optional feedback was reviewed thematically. Among 48 participants, most rated the three MCQ sources as equally effective, although ChatGPT was more often preferred for helping students identify and confront their knowledge gaps through challenging distractors and diagnostic insight, while expert-written questions were rated highest for deeper analytical thinking. A significant variation in preferences was observed across sources (χ² (64) = 688.79, <i>p</i> < .001). Qualitative feedback emphasized the need for better difficulty calibration and clearer distractors in some AI-generated items. Overall, LLM-generated anatomy MCQs can closely match expert-authored ones in learner-perceived value and may support deeper engagement, but expert review remains critical to ensure clarity and alignment with curricular goals. A hybrid AI-human workflow may provide a promising path for scalable, high-quality assessment design in medical education.</p>\",\"PeriodicalId\":47656,\"journal\":{\"name\":\"Medical Education Online\",\"volume\":\"30 1\",\"pages\":\"2554678\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12404065/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Medical Education Online\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1080/10872981.2025.2554678\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/30 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION & EDUCATIONAL RESEARCH\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical Education Online","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1080/10872981.2025.2554678","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/30 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"EDUCATION & EDUCATIONAL RESEARCH","Score":null,"Total":0}
Assessing LLM-generated vs. expert-created clinical anatomy MCQs: a student perception-based comparative study in medical education.
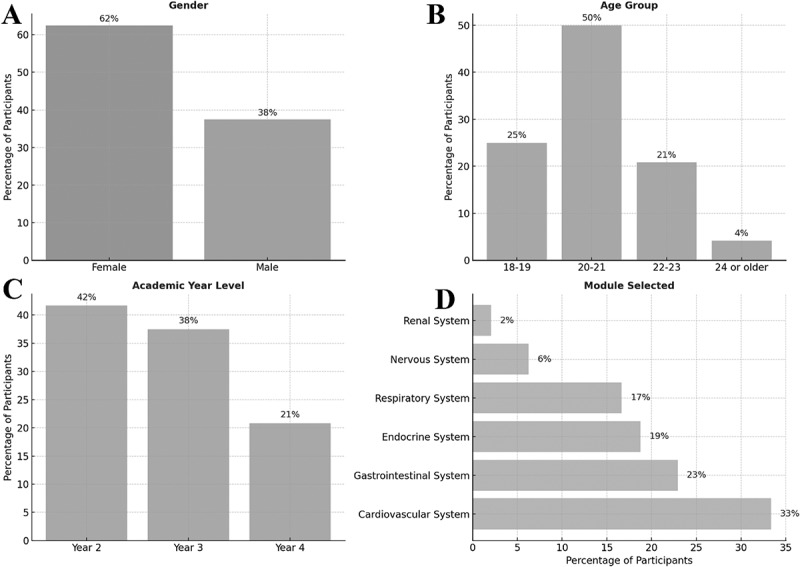
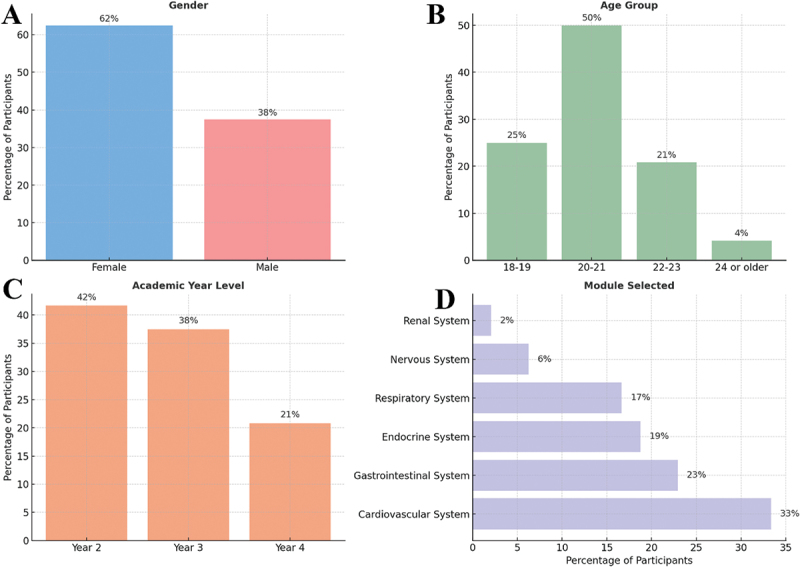
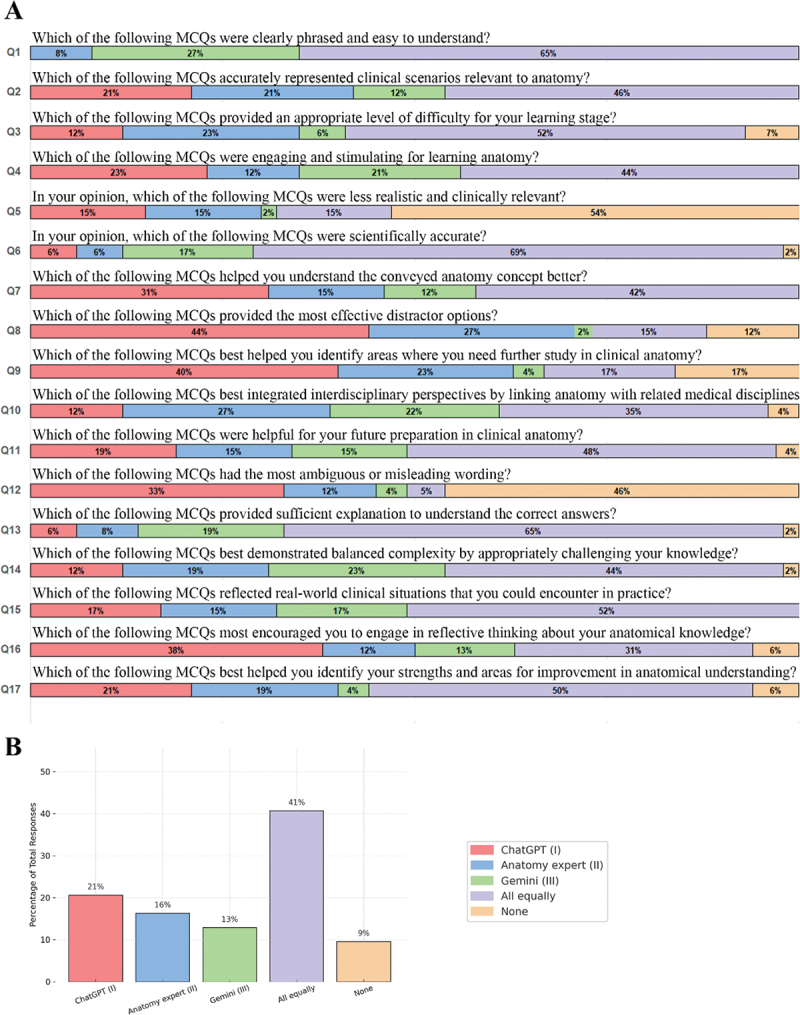
Large language models (LLMs) such as ChatGPT and Gemini are increasingly used to generate educational content in medical education, including multiple-choice questions (MCQs), but their effectiveness compared to expert-written questions remains underexplored, particularly in anatomy. We conducted a cross-sectional, mixed-methods study involving Year 2-4 medical students at Qatar University, where participants completed and evaluated three anonymized MCQ sets-authored by ChatGPT, Google-Gemini, and a clinical anatomist-across 17 quality criteria. Descriptive and chi-square analyses were performed, and optional feedback was reviewed thematically. Among 48 participants, most rated the three MCQ sources as equally effective, although ChatGPT was more often preferred for helping students identify and confront their knowledge gaps through challenging distractors and diagnostic insight, while expert-written questions were rated highest for deeper analytical thinking. A significant variation in preferences was observed across sources (χ² (64) = 688.79, p < .001). Qualitative feedback emphasized the need for better difficulty calibration and clearer distractors in some AI-generated items. Overall, LLM-generated anatomy MCQs can closely match expert-authored ones in learner-perceived value and may support deeper engagement, but expert review remains critical to ensure clarity and alignment with curricular goals. A hybrid AI-human workflow may provide a promising path for scalable, high-quality assessment design in medical education.
期刊介绍:
Medical Education Online is an open access journal of health care education, publishing peer-reviewed research, perspectives, reviews, and early documentation of new ideas and trends.
Medical Education Online aims to disseminate information on the education and training of physicians and other health care professionals. Manuscripts may address any aspect of health care education and training, including, but not limited to:
-Basic science education
-Clinical science education
-Residency education
-Learning theory
-Problem-based learning (PBL)
-Curriculum development
-Research design and statistics
-Measurement and evaluation
-Faculty development
-Informatics/web

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


