超越机器人:在护理教育中评估人工智能聊天机器人模拟的双阶段框架。
摘要
背景/目的:人工智能聊天机器人在护理教育中的整合,特别是在基于模拟的学习中,正在迅速发展。然而,缺乏结构化的评估模型,特别是评估人工智能生成的模拟。本文介绍了人工智能集成模拟方法(AIMS)评估框架,这是一个改编自FAITA模型的双阶段评估框架,旨在评估护理教育背景下的提示设计和聊天机器人性能。方法:以仿真为基础,探讨人工智能聊天机器人在应急预案课程中的应用。AIMS框架被开发和应用,包括六个提示级领域(第一阶段)和八个绩效标准(第二阶段)。这些领域是根据当前教学设计、模拟保真度和新兴人工智能评估文献的最佳实践选择的。为了评估聊天机器人的教育效用,该研究为每个阶段采用了评分标准,并结合了结构化的反馈循环,以完善提示设计和聊天盒交互。为了演示该框架的实际应用,研究人员配置了一个在本研究中被称为“Eval-Bot v1”的人工智能工具,该工具使用OpenAI的GPT-4.0构建,将第一阶段评分标准应用于真实的模拟提示。从这个分析中得出的见解随后被用于预测第二阶段的性能,并确定需要改进的领域。参与者(三个人)——都是经验丰富的医疗保健教育工作者和具有临床决策和模拟教学专业知识的高级执业护士——回顾了prompt和Eval-Bot的得分,以三角测量结果。结果:模拟评估显示了与课程目标迅速一致的明显优势及其促进互动学习的能力。与会者指出,人工智能聊天机器人支持参与并保持适当的节奏,特别是在涉及应急规划决策的情况下。然而,在个性化和包容性方面出现了挑战。虽然聊天机器人对一般问题的回答始终一致,但它很难调整语气、复杂性和内容,以反映不同学习者的需求或文化差异。为了支持复制和细化,提供了一个示例评分规则和模拟提示模板。当使用Eval-Bot工具进行评估时,对安全提示和包容性语言进行了适度的关注,特别是在聊天机器人如何导航敏感决策点方面。这些差距与阶段2领域中预测的性能问题有关,例如对话控制、公平性和用户保证。基于这些发现,我们修订了提示策略,以提高上下文敏感性,促进包容性,并加强聊天机器人主导的模拟中的道德指导。结论:AIMS评估框架为评估人工智能聊天机器人在模拟教育中的使用提供了一种实用且可复制的方法。通过提供提示设计和聊天机器人性能的结构化标准,该模型支持教学设计师、仿真专家和开发人员确定优势和改进的领域。研究结果强调了在将人工智能纳入护理和健康教育时,有意设计、安全监测和包容性语言的重要性。随着人工智能工具越来越多地嵌入到学习环境中,这个框架提供了一个深思熟虑的起点,以确保它们的应用合乎道德、有效,并考虑到学习者的多样性。
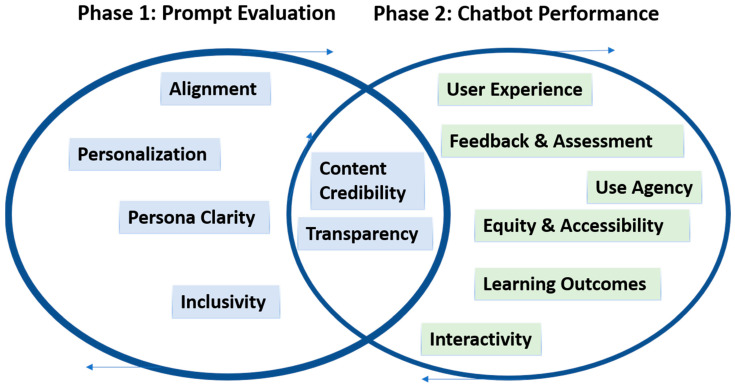
Background/Objectives: The integration of AI chatbots in nursing education, particularly in simulation-based learning, is advancing rapidly. However, there is a lack of structured evaluation models, especially to assess AI-generated simulations. This article introduces the AI-Integrated Method for Simulation (AIMS) evaluation framework, a dual-phase evaluation framework adapted from the FAITA model, designed to evaluate both prompt design and chatbot performance in the context of nursing education. Methods: This simulation-based study explored the application of an AI chatbot in an emergency planning course. The AIMS framework was developed and applied, consisting of six prompt-level domains (Phase 1) and eight performance criteria (Phase 2). These domains were selected based on current best practices in instructional design, simulation fidelity, and emerging AI evaluation literature. To assess the chatbots educational utility, the study employed a scoring rubric for each phase and incorporated a structured feedback loop to refine both prompt design and chatbox interaction. To demonstrate the framework's practical application, the researchers configured an AI tool referred to in this study as "Eval-Bot v1", built using OpenAI's GPT-4.0, to apply Phase 1 scoring criteria to a real simulation prompt. Insights from this analysis were then used to anticipate Phase 2 performance and identify areas for improvement. Participants (three individuals)-all experienced healthcare educators and advanced practice nurses with expertise in clinical decision-making and simulation-based teaching-reviewed the prompt and Eval-Bot's score to triangulate findings. Results: Simulated evaluations revealed clear strengths in the prompt alignment with course objectives and its capacity to foster interactive learning. Participants noted that the AI chatbot supported engagement and maintained appropriate pacing, particularly in scenarios involving emergency planning decision-making. However, challenges emerged in areas related to personalization and inclusivity. While the chatbot responded consistently to general queries, it struggled to adapt tone, complexity and content to reflect diverse learner needs or cultural nuances. To support replication and refinement, a sample scoring rubric and simulation prompt template are provided. When evaluated using the Eval-Bot tool, moderate concerns were flagged regarding safety prompts and inclusive language, particularly in how the chatbot navigated sensitive decision points. These gaps were linked to predicted performance issues in Phase 2 domains such as dialog control, equity, and user reassurance. Based on these findings, revised prompt strategies were developed to improve contextual sensitivity, promote inclusivity, and strengthen ethical guidance within chatbot-led simulations. Conclusions: The AIMS evaluation framework provides a practical and replicable approach for evaluating the use of AI chatbots in simulation-based education. By offering structured criteria for both prompt design and chatbot performance, the model supports instructional designers, simulation specialists, and developers in identifying areas of strength and improvement. The findings underscore the importance of intentional design, safety monitoring, and inclusive language when integrating AI into nursing and health education. As AI tools become more embedded in learning environments, this framework offers a thoughtful starting point for ensuring they are applied ethically, effectively, and with learner diversity in mind.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


