Dabin Min, Kwang Nam Jin, SangHeum Bang, Moon Young Kim, Hack-Lyoung Kim, Won Gi Jeong, Hye-Jeong Lee, Kyongmin Sarah Beck, Sung Ho Hwang, Eun Young Kim, Chang Min Park
{"title":"从半结构化冠状动脉CT血管造影报告中提取CAD-RADS 2.0的大型语言模型:一项多机构研究。","authors":"Dabin Min, Kwang Nam Jin, SangHeum Bang, Moon Young Kim, Hack-Lyoung Kim, Won Gi Jeong, Hye-Jeong Lee, Kyongmin Sarah Beck, Sung Ho Hwang, Eun Young Kim, Chang Min Park","doi":"10.3348/kjr.2025.0293","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To evaluate the accuracy of large language models (LLMs) in extracting Coronary Artery Disease-Reporting and Data System (CAD-RADS) 2.0 components from coronary CT angiography (CCTA) reports, and assess the impact of prompting strategies.</p><p><strong>Materials and methods: </strong>In this multi-institutional study, we collected 319 synthetic, semi-structured CCTA reports from six institutions to protect patient privacy while maintaining clinical relevance. The dataset included 150 reports from a primary institution (100 for instruction development and 50 for internal testing) and 169 reports from five external institutions for external testing. Board-certified radiologists established reference standards following the CAD-RADS 2.0 guidelines for all three components: stenosis severity, plaque burden, and modifiers. Six LLMs (GPT-4, GPT-4o, Claude-3.5-Sonnet, o1-mini, Gemini-1.5-Pro, and DeepSeek-R1-Distill-Qwen-14B) were evaluated using an optimized instruction with prompting strategies, including zero-shot or few-shot with or without chain-of-thought (CoT) prompting. The accuracy was assessed and compared using McNemar's test.</p><p><strong>Results: </strong>LLMs demonstrated robust accuracy across all CAD-RADS 2.0 components. Peak stenosis severity accuracies reached 0.980 (48/49, Claude-3.5-Sonnet and o1-mini) in internal testing and 0.946 (158/167, GPT-4o and o1-mini) in external testing. Plaque burden extraction showed exceptional accuracy, with multiple models achieving perfect accuracy (43/43) in internal testing and 0.993 (137/138, GPT-4o, and o1-mini) in external testing. Modifier detection demonstrated consistently high accuracy (≥0.990) across most models. One open-source model, DeepSeek-R1-Distill-Qwen-14B, showed a relatively low accuracy for stenosis severity: 0.898 (44/49, internal) and 0.820 (137/167, external). CoT prompting significantly enhanced the accuracy of several models, with GPT-4 showing the most substantial improvements: stenosis severity accuracy increased by 0.192 (<i>P</i> < 0.001) and plaque burden accuracy by 0.152 (<i>P</i> < 0.001) in external testing.</p><p><strong>Conclusion: </strong>LLMs demonstrated high accuracy in automated extraction of CAD-RADS 2.0 components from semi-structured CCTA reports, particularly when used with CoT prompting.</p>","PeriodicalId":17881,"journal":{"name":"Korean Journal of Radiology","volume":"26 9","pages":"817-831"},"PeriodicalIF":5.3000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12394816/pdf/","citationCount":"0","resultStr":"{\"title\":\"Large Language Models for CAD-RADS 2.0 Extraction From Semi-Structured Coronary CT Angiography Reports: A Multi-Institutional Study.\",\"authors\":\"Dabin Min, Kwang Nam Jin, SangHeum Bang, Moon Young Kim, Hack-Lyoung Kim, Won Gi Jeong, Hye-Jeong Lee, Kyongmin Sarah Beck, Sung Ho Hwang, Eun Young Kim, Chang Min Park\",\"doi\":\"10.3348/kjr.2025.0293\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>To evaluate the accuracy of large language models (LLMs) in extracting Coronary Artery Disease-Reporting and Data System (CAD-RADS) 2.0 components from coronary CT angiography (CCTA) reports, and assess the impact of prompting strategies.</p><p><strong>Materials and methods: </strong>In this multi-institutional study, we collected 319 synthetic, semi-structured CCTA reports from six institutions to protect patient privacy while maintaining clinical relevance. The dataset included 150 reports from a primary institution (100 for instruction development and 50 for internal testing) and 169 reports from five external institutions for external testing. Board-certified radiologists established reference standards following the CAD-RADS 2.0 guidelines for all three components: stenosis severity, plaque burden, and modifiers. Six LLMs (GPT-4, GPT-4o, Claude-3.5-Sonnet, o1-mini, Gemini-1.5-Pro, and DeepSeek-R1-Distill-Qwen-14B) were evaluated using an optimized instruction with prompting strategies, including zero-shot or few-shot with or without chain-of-thought (CoT) prompting. The accuracy was assessed and compared using McNemar's test.</p><p><strong>Results: </strong>LLMs demonstrated robust accuracy across all CAD-RADS 2.0 components. Peak stenosis severity accuracies reached 0.980 (48/49, Claude-3.5-Sonnet and o1-mini) in internal testing and 0.946 (158/167, GPT-4o and o1-mini) in external testing. Plaque burden extraction showed exceptional accuracy, with multiple models achieving perfect accuracy (43/43) in internal testing and 0.993 (137/138, GPT-4o, and o1-mini) in external testing. Modifier detection demonstrated consistently high accuracy (≥0.990) across most models. One open-source model, DeepSeek-R1-Distill-Qwen-14B, showed a relatively low accuracy for stenosis severity: 0.898 (44/49, internal) and 0.820 (137/167, external). CoT prompting significantly enhanced the accuracy of several models, with GPT-4 showing the most substantial improvements: stenosis severity accuracy increased by 0.192 (<i>P</i> < 0.001) and plaque burden accuracy by 0.152 (<i>P</i> < 0.001) in external testing.</p><p><strong>Conclusion: </strong>LLMs demonstrated high accuracy in automated extraction of CAD-RADS 2.0 components from semi-structured CCTA reports, particularly when used with CoT prompting.</p>\",\"PeriodicalId\":17881,\"journal\":{\"name\":\"Korean Journal of Radiology\",\"volume\":\"26 9\",\"pages\":\"817-831\"},\"PeriodicalIF\":5.3000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12394816/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Korean Journal of Radiology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3348/kjr.2025.0293\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Korean Journal of Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3348/kjr.2025.0293","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
Large Language Models for CAD-RADS 2.0 Extraction From Semi-Structured Coronary CT Angiography Reports: A Multi-Institutional Study.
Objective: To evaluate the accuracy of large language models (LLMs) in extracting Coronary Artery Disease-Reporting and Data System (CAD-RADS) 2.0 components from coronary CT angiography (CCTA) reports, and assess the impact of prompting strategies.
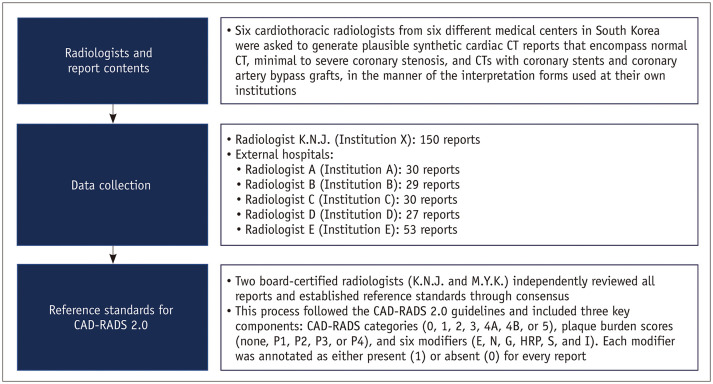
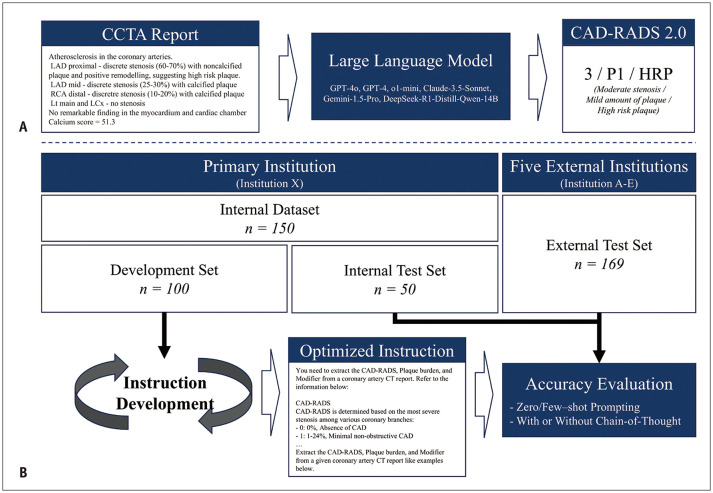
Materials and methods: In this multi-institutional study, we collected 319 synthetic, semi-structured CCTA reports from six institutions to protect patient privacy while maintaining clinical relevance. The dataset included 150 reports from a primary institution (100 for instruction development and 50 for internal testing) and 169 reports from five external institutions for external testing. Board-certified radiologists established reference standards following the CAD-RADS 2.0 guidelines for all three components: stenosis severity, plaque burden, and modifiers. Six LLMs (GPT-4, GPT-4o, Claude-3.5-Sonnet, o1-mini, Gemini-1.5-Pro, and DeepSeek-R1-Distill-Qwen-14B) were evaluated using an optimized instruction with prompting strategies, including zero-shot or few-shot with or without chain-of-thought (CoT) prompting. The accuracy was assessed and compared using McNemar's test.
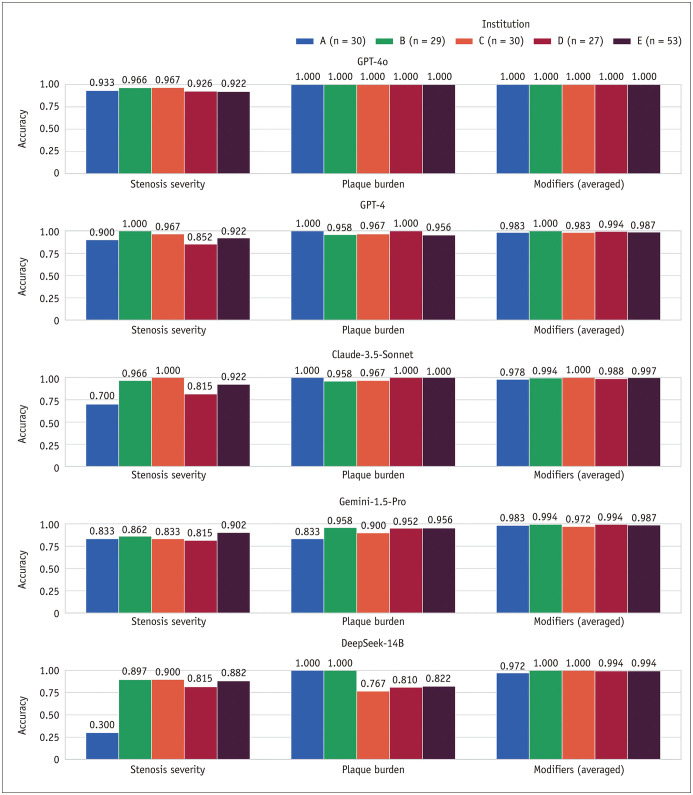
Results: LLMs demonstrated robust accuracy across all CAD-RADS 2.0 components. Peak stenosis severity accuracies reached 0.980 (48/49, Claude-3.5-Sonnet and o1-mini) in internal testing and 0.946 (158/167, GPT-4o and o1-mini) in external testing. Plaque burden extraction showed exceptional accuracy, with multiple models achieving perfect accuracy (43/43) in internal testing and 0.993 (137/138, GPT-4o, and o1-mini) in external testing. Modifier detection demonstrated consistently high accuracy (≥0.990) across most models. One open-source model, DeepSeek-R1-Distill-Qwen-14B, showed a relatively low accuracy for stenosis severity: 0.898 (44/49, internal) and 0.820 (137/167, external). CoT prompting significantly enhanced the accuracy of several models, with GPT-4 showing the most substantial improvements: stenosis severity accuracy increased by 0.192 (P < 0.001) and plaque burden accuracy by 0.152 (P < 0.001) in external testing.
Conclusion: LLMs demonstrated high accuracy in automated extraction of CAD-RADS 2.0 components from semi-structured CCTA reports, particularly when used with CoT prompting.
期刊介绍:
The inaugural issue of the Korean J Radiol came out in March 2000. Our journal aims to produce and propagate knowledge on radiologic imaging and related sciences.
A unique feature of the articles published in the Journal will be their reflection of global trends in radiology combined with an East-Asian perspective. Geographic differences in disease prevalence will be reflected in the contents of papers, and this will serve to enrich our body of knowledge.
World''s outstanding radiologists from many countries are serving as editorial board of our journal.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


