Cem Simsek, Mete Ucdal, Enrique de-Madaria, Alanna Ebigbo, Petr Vanek, Omar Elshaarawy, Theodor Alexandru Voiosu, Giulio Antonelli, Román Turró, Javier P Gisbert, Olga P Nyssen, Cesare Hassan, Helmut Messmann, Rajiv Jalan
{"title":"GastroGPT:开发和控制概念验证定制临床语言模型的测试。","authors":"Cem Simsek, Mete Ucdal, Enrique de-Madaria, Alanna Ebigbo, Petr Vanek, Omar Elshaarawy, Theodor Alexandru Voiosu, Giulio Antonelli, Román Turró, Javier P Gisbert, Olga P Nyssen, Cesare Hassan, Helmut Messmann, Rajiv Jalan","doi":"10.1055/a-2637-2163","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and study aims: </strong>Current general-purpose artificial intelligence (AI) large language models (LLMs) demonstrate limited efficacy in clinical medicine, often constrained to question-answering, documentation, and literature summarization roles. We developed GastroGPT, a proof-of-concept specialty-specific, multi-task, clinical LLM, and evaluated its performance against leading general-purpose LLMs across key gastroenterology tasks and diverse case scenarios.</p><p><strong>Methods: </strong>In this structured analysis, GastroGPT was compared with three state-of-the-art general-purpose LLMs (LLM-A: GPT-4, LLM-B: Bard, LLM-C: Claude). Models were assessed on seven clinical tasks and overall performance across 10 simulated gastroenterology cases varying in complexity, frequency, and patient demographics. Standardized prompts facilitated structured comparisons. A blinded expert panel rated model outputs per task on a 10-point Likert scale, judging clinical utility. Comprehensive statistical analyses were conducted.</p><p><strong>Results: </strong>A total of 2,240 expert ratings were obtained. GastroGPT achieved significantly higher mean overall scores (8.1 ± 1.8) compared with GPT-4 (5.2 ± 3.0), Bard (5.7 ± 3.3), and Claude (7.0 ± 2.7) (all <i>P</i> < 0.001). It outperformed comparators in six of seven tasks ( <i>P</i> < 0.05), except follow-up planning. GastroGPT demonstrated superior score consistency (variance 34.95) versus general models (97.4-260.35) ( <i>P</i> < 0.001). Its performance remained consistent across case complexities and frequencies, unlike the comparators ( <i>P</i> < 0.001). Multivariate analysis revealed that model type significantly predicted performance ( <i>P</i> < 0.001).</p><p><strong>Conclusions: </strong>This study pioneered development and comparison of a specialty-specific, clinically-oriented AI model to general-purpose LLMs. GastroGPT demonstrated superior utility overall and on key gastroenterology tasks, highlighting the potential for tailored, task-focused AI models in medicine.</p>","PeriodicalId":11671,"journal":{"name":"Endoscopy International Open","volume":"13 ","pages":"a26372163"},"PeriodicalIF":2.3000,"publicationDate":"2025-08-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12371664/pdf/","citationCount":"0","resultStr":"{\"title\":\"GastroGPT: Development and controlled testing of a proof-of-concept customized clinical language model.\",\"authors\":\"Cem Simsek, Mete Ucdal, Enrique de-Madaria, Alanna Ebigbo, Petr Vanek, Omar Elshaarawy, Theodor Alexandru Voiosu, Giulio Antonelli, Román Turró, Javier P Gisbert, Olga P Nyssen, Cesare Hassan, Helmut Messmann, Rajiv Jalan\",\"doi\":\"10.1055/a-2637-2163\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background and study aims: </strong>Current general-purpose artificial intelligence (AI) large language models (LLMs) demonstrate limited efficacy in clinical medicine, often constrained to question-answering, documentation, and literature summarization roles. We developed GastroGPT, a proof-of-concept specialty-specific, multi-task, clinical LLM, and evaluated its performance against leading general-purpose LLMs across key gastroenterology tasks and diverse case scenarios.</p><p><strong>Methods: </strong>In this structured analysis, GastroGPT was compared with three state-of-the-art general-purpose LLMs (LLM-A: GPT-4, LLM-B: Bard, LLM-C: Claude). Models were assessed on seven clinical tasks and overall performance across 10 simulated gastroenterology cases varying in complexity, frequency, and patient demographics. Standardized prompts facilitated structured comparisons. A blinded expert panel rated model outputs per task on a 10-point Likert scale, judging clinical utility. Comprehensive statistical analyses were conducted.</p><p><strong>Results: </strong>A total of 2,240 expert ratings were obtained. GastroGPT achieved significantly higher mean overall scores (8.1 ± 1.8) compared with GPT-4 (5.2 ± 3.0), Bard (5.7 ± 3.3), and Claude (7.0 ± 2.7) (all <i>P</i> < 0.001). It outperformed comparators in six of seven tasks ( <i>P</i> < 0.05), except follow-up planning. GastroGPT demonstrated superior score consistency (variance 34.95) versus general models (97.4-260.35) ( <i>P</i> < 0.001). Its performance remained consistent across case complexities and frequencies, unlike the comparators ( <i>P</i> < 0.001). Multivariate analysis revealed that model type significantly predicted performance ( <i>P</i> < 0.001).</p><p><strong>Conclusions: </strong>This study pioneered development and comparison of a specialty-specific, clinically-oriented AI model to general-purpose LLMs. GastroGPT demonstrated superior utility overall and on key gastroenterology tasks, highlighting the potential for tailored, task-focused AI models in medicine.</p>\",\"PeriodicalId\":11671,\"journal\":{\"name\":\"Endoscopy International Open\",\"volume\":\"13 \",\"pages\":\"a26372163\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2025-08-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12371664/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Endoscopy International Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1055/a-2637-2163\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"GASTROENTEROLOGY & HEPATOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Endoscopy International Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1055/a-2637-2163","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"GASTROENTEROLOGY & HEPATOLOGY","Score":null,"Total":0}
GastroGPT: Development and controlled testing of a proof-of-concept customized clinical language model.
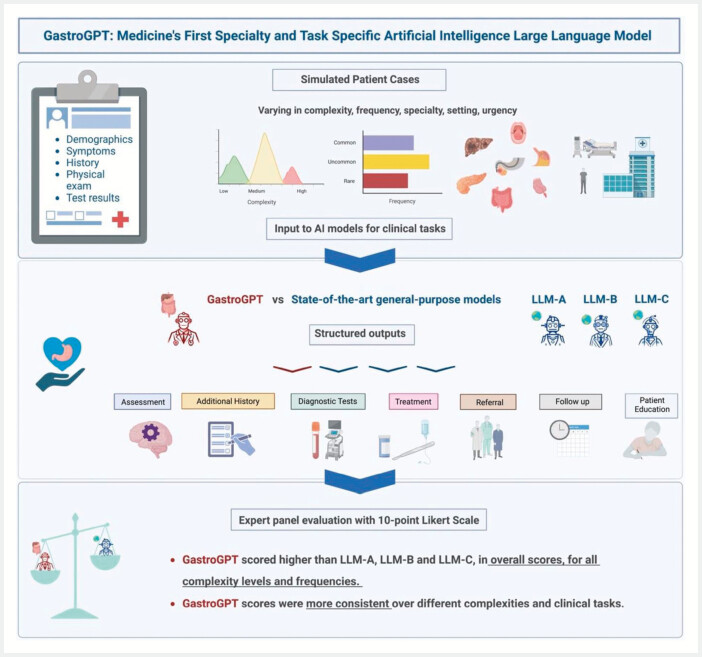
Background and study aims: Current general-purpose artificial intelligence (AI) large language models (LLMs) demonstrate limited efficacy in clinical medicine, often constrained to question-answering, documentation, and literature summarization roles. We developed GastroGPT, a proof-of-concept specialty-specific, multi-task, clinical LLM, and evaluated its performance against leading general-purpose LLMs across key gastroenterology tasks and diverse case scenarios.
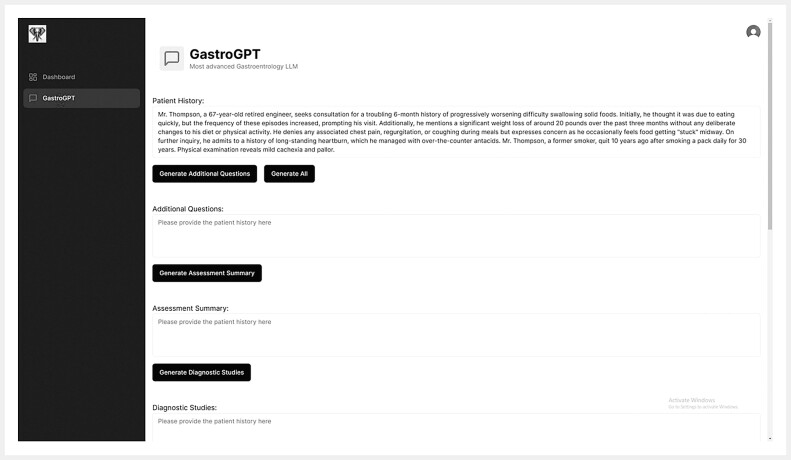
Methods: In this structured analysis, GastroGPT was compared with three state-of-the-art general-purpose LLMs (LLM-A: GPT-4, LLM-B: Bard, LLM-C: Claude). Models were assessed on seven clinical tasks and overall performance across 10 simulated gastroenterology cases varying in complexity, frequency, and patient demographics. Standardized prompts facilitated structured comparisons. A blinded expert panel rated model outputs per task on a 10-point Likert scale, judging clinical utility. Comprehensive statistical analyses were conducted.
Results: A total of 2,240 expert ratings were obtained. GastroGPT achieved significantly higher mean overall scores (8.1 ± 1.8) compared with GPT-4 (5.2 ± 3.0), Bard (5.7 ± 3.3), and Claude (7.0 ± 2.7) (all P < 0.001). It outperformed comparators in six of seven tasks ( P < 0.05), except follow-up planning. GastroGPT demonstrated superior score consistency (variance 34.95) versus general models (97.4-260.35) ( P < 0.001). Its performance remained consistent across case complexities and frequencies, unlike the comparators ( P < 0.001). Multivariate analysis revealed that model type significantly predicted performance ( P < 0.001).
Conclusions: This study pioneered development and comparison of a specialty-specific, clinically-oriented AI model to general-purpose LLMs. GastroGPT demonstrated superior utility overall and on key gastroenterology tasks, highlighting the potential for tailored, task-focused AI models in medicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


