{"title":"基于大型语言模型的聊天机器人与临床医生作为正畸信息来源的可靠性:比较分析。","authors":"Stefano Martina, Davide Cannatà, Teresa Paduano, Valentina Schettino, Francesco Giordano, Marzio Galdi","doi":"10.3390/dj13080343","DOIUrl":null,"url":null,"abstract":"<p><p><b>Objectives</b>: The present cross-sectional analysis aimed to investigate whether Large Language Model-based chatbots can be used as reliable sources of information in orthodontics by evaluating chatbot responses and comparing them to those of dental practitioners with different levels of knowledge. <b>Methods</b>: Eight true and false frequently asked orthodontic questions were submitted to five leading chatbots (ChatGPT-4, Claude-3-Opus, Gemini 2.0 Flash Experimental, Microsoft Copilot, and DeepSeek). The consistency of the answers given by chatbots at four different times was assessed using Cronbach's α. Chi-squared test was used to compare chatbot responses with those given by two groups of clinicians, i.e., general dental practitioners (GDPs) and orthodontic specialists (Os) recruited in an online survey via social media, and differences were considered significant when <i>p</i> < 0.05. Additionally, chatbots were asked to provide a justification for their dichotomous responses using a chain-of-through prompting approach and rating the educational value according to the Global Quality Scale (GQS). <b>Results</b>: A high degree of consistency in answering was found for all analyzed chatbots (α > 0.80). When comparing chatbot answers with GDP and O ones, statistically significant differences were found for almost all the questions (<i>p</i> < 0.05). When evaluating the educational value of chatbot responses, DeepSeek achieved the highest GQS score (median 4.00; interquartile range 0.00), whereas CoPilot had the lowest one (median 2.00; interquartile range 2.00). <b>Conclusions</b>: Although chatbots yield somewhat useful information about orthodontics, they can provide misleading information when dealing with controversial topics.</p>","PeriodicalId":11269,"journal":{"name":"Dentistry Journal","volume":"13 8","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12385111/pdf/","citationCount":"0","resultStr":"{\"title\":\"Reliability of Large Language Model-Based Chatbots Versus Clinicians as Sources of Information on Orthodontics: A Comparative Analysis.\",\"authors\":\"Stefano Martina, Davide Cannatà, Teresa Paduano, Valentina Schettino, Francesco Giordano, Marzio Galdi\",\"doi\":\"10.3390/dj13080343\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Objectives</b>: The present cross-sectional analysis aimed to investigate whether Large Language Model-based chatbots can be used as reliable sources of information in orthodontics by evaluating chatbot responses and comparing them to those of dental practitioners with different levels of knowledge. <b>Methods</b>: Eight true and false frequently asked orthodontic questions were submitted to five leading chatbots (ChatGPT-4, Claude-3-Opus, Gemini 2.0 Flash Experimental, Microsoft Copilot, and DeepSeek). The consistency of the answers given by chatbots at four different times was assessed using Cronbach's α. Chi-squared test was used to compare chatbot responses with those given by two groups of clinicians, i.e., general dental practitioners (GDPs) and orthodontic specialists (Os) recruited in an online survey via social media, and differences were considered significant when <i>p</i> < 0.05. Additionally, chatbots were asked to provide a justification for their dichotomous responses using a chain-of-through prompting approach and rating the educational value according to the Global Quality Scale (GQS). <b>Results</b>: A high degree of consistency in answering was found for all analyzed chatbots (α > 0.80). When comparing chatbot answers with GDP and O ones, statistically significant differences were found for almost all the questions (<i>p</i> < 0.05). When evaluating the educational value of chatbot responses, DeepSeek achieved the highest GQS score (median 4.00; interquartile range 0.00), whereas CoPilot had the lowest one (median 2.00; interquartile range 2.00). <b>Conclusions</b>: Although chatbots yield somewhat useful information about orthodontics, they can provide misleading information when dealing with controversial topics.</p>\",\"PeriodicalId\":11269,\"journal\":{\"name\":\"Dentistry Journal\",\"volume\":\"13 8\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2025-07-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12385111/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Dentistry Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/dj13080343\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"DENTISTRY, ORAL SURGERY & MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Dentistry Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/dj13080343","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"DENTISTRY, ORAL SURGERY & MEDICINE","Score":null,"Total":0}
Reliability of Large Language Model-Based Chatbots Versus Clinicians as Sources of Information on Orthodontics: A Comparative Analysis.
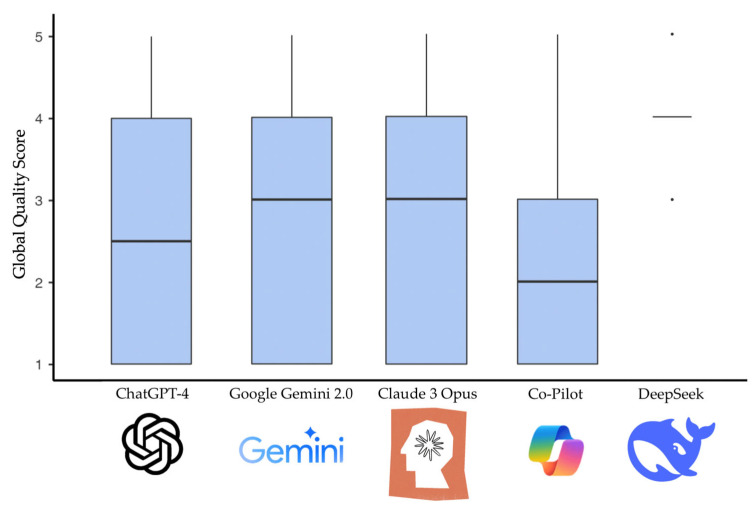
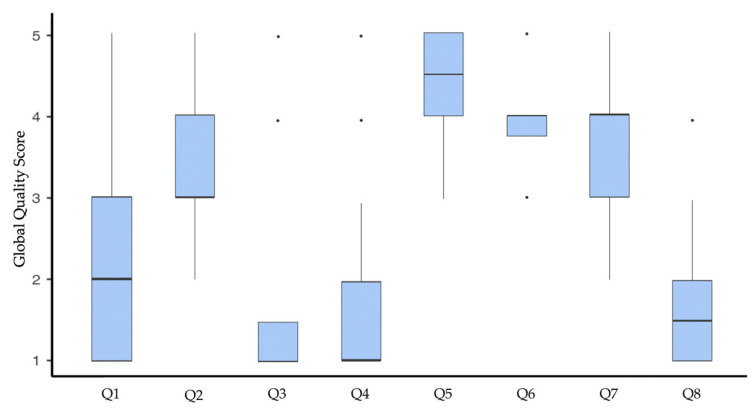
Objectives: The present cross-sectional analysis aimed to investigate whether Large Language Model-based chatbots can be used as reliable sources of information in orthodontics by evaluating chatbot responses and comparing them to those of dental practitioners with different levels of knowledge. Methods: Eight true and false frequently asked orthodontic questions were submitted to five leading chatbots (ChatGPT-4, Claude-3-Opus, Gemini 2.0 Flash Experimental, Microsoft Copilot, and DeepSeek). The consistency of the answers given by chatbots at four different times was assessed using Cronbach's α. Chi-squared test was used to compare chatbot responses with those given by two groups of clinicians, i.e., general dental practitioners (GDPs) and orthodontic specialists (Os) recruited in an online survey via social media, and differences were considered significant when p < 0.05. Additionally, chatbots were asked to provide a justification for their dichotomous responses using a chain-of-through prompting approach and rating the educational value according to the Global Quality Scale (GQS). Results: A high degree of consistency in answering was found for all analyzed chatbots (α > 0.80). When comparing chatbot answers with GDP and O ones, statistically significant differences were found for almost all the questions (p < 0.05). When evaluating the educational value of chatbot responses, DeepSeek achieved the highest GQS score (median 4.00; interquartile range 0.00), whereas CoPilot had the lowest one (median 2.00; interquartile range 2.00). Conclusions: Although chatbots yield somewhat useful information about orthodontics, they can provide misleading information when dealing with controversial topics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


