Mohamed Abdelmoaty Ahmed, Ahmed AbdelMoety, Asmaa Mohamed Ahmed Soliman
{"title":"利用机器学习的生活方式和基因数据预测癌症风险。","authors":"Mohamed Abdelmoaty Ahmed, Ahmed AbdelMoety, Asmaa Mohamed Ahmed Soliman","doi":"10.1038/s41598-025-15656-8","DOIUrl":null,"url":null,"abstract":"<p><p>Cancer remains one of the leading causes of mortality worldwide, where early detection significantly improves patient outcomes and reduces treatment burden. This study investigates the application of Machine Learning (ML) techniques to predict cancer risk based on a combination of genetic and lifestyle factors. A structured dataset of 1,200 patient records was used, comprising features such as age, gender, Body Mass Index (BMI), smoking status, alcohol intake, physical activity, genetic risk level, and personal history of cancer. A full end-to-end ML pipeline was implemented, encompassing data exploration, preprocessing, feature scaling, model training, and evaluation using stratified cross-validation and a separate test set. Nine supervised learning algorithms were evaluated and compared, including Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Support Vector Machines (SVMs), and several ensemble methods. Among these, Categorical Boosting (CatBoost) achieved the highest predictive performance, with a test accuracy of 98.75% and an F1-score of 0.9820, outperforming both traditional and other advanced models. Feature importance analysis confirmed the strong influence of cancer history, genetic risk, and smoking status on prediction outcomes. The findings highlight the effectiveness of boosting-based ensemble models in capturing complex interactions within health data and support their potential use in personalized cancer risk assessment. This research underscores the value of integrating genetic and modifiable lifestyle variables into predictive modeling to enhance early detection and preventive healthcare strategies.</p>","PeriodicalId":21811,"journal":{"name":"Scientific Reports","volume":"15 1","pages":"30458"},"PeriodicalIF":3.9000,"publicationDate":"2025-08-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12365227/pdf/","citationCount":"0","resultStr":"{\"title\":\"Predicting cancer risk using machine learning on lifestyle and genetic data.\",\"authors\":\"Mohamed Abdelmoaty Ahmed, Ahmed AbdelMoety, Asmaa Mohamed Ahmed Soliman\",\"doi\":\"10.1038/s41598-025-15656-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Cancer remains one of the leading causes of mortality worldwide, where early detection significantly improves patient outcomes and reduces treatment burden. This study investigates the application of Machine Learning (ML) techniques to predict cancer risk based on a combination of genetic and lifestyle factors. A structured dataset of 1,200 patient records was used, comprising features such as age, gender, Body Mass Index (BMI), smoking status, alcohol intake, physical activity, genetic risk level, and personal history of cancer. A full end-to-end ML pipeline was implemented, encompassing data exploration, preprocessing, feature scaling, model training, and evaluation using stratified cross-validation and a separate test set. Nine supervised learning algorithms were evaluated and compared, including Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Support Vector Machines (SVMs), and several ensemble methods. Among these, Categorical Boosting (CatBoost) achieved the highest predictive performance, with a test accuracy of 98.75% and an F1-score of 0.9820, outperforming both traditional and other advanced models. Feature importance analysis confirmed the strong influence of cancer history, genetic risk, and smoking status on prediction outcomes. The findings highlight the effectiveness of boosting-based ensemble models in capturing complex interactions within health data and support their potential use in personalized cancer risk assessment. This research underscores the value of integrating genetic and modifiable lifestyle variables into predictive modeling to enhance early detection and preventive healthcare strategies.</p>\",\"PeriodicalId\":21811,\"journal\":{\"name\":\"Scientific Reports\",\"volume\":\"15 1\",\"pages\":\"30458\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-08-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12365227/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Reports\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41598-025-15656-8\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Reports","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41598-025-15656-8","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Predicting cancer risk using machine learning on lifestyle and genetic data.
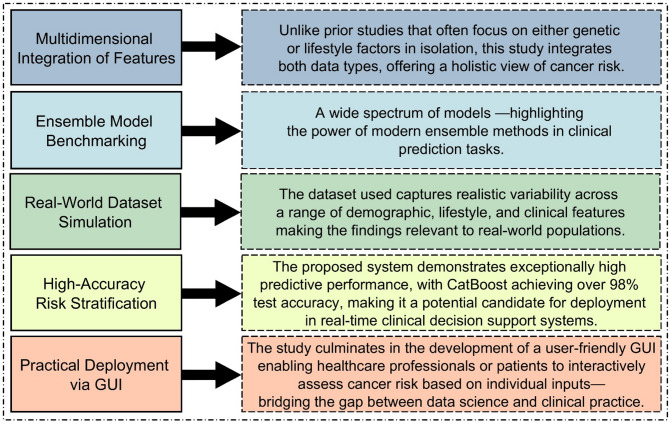
Cancer remains one of the leading causes of mortality worldwide, where early detection significantly improves patient outcomes and reduces treatment burden. This study investigates the application of Machine Learning (ML) techniques to predict cancer risk based on a combination of genetic and lifestyle factors. A structured dataset of 1,200 patient records was used, comprising features such as age, gender, Body Mass Index (BMI), smoking status, alcohol intake, physical activity, genetic risk level, and personal history of cancer. A full end-to-end ML pipeline was implemented, encompassing data exploration, preprocessing, feature scaling, model training, and evaluation using stratified cross-validation and a separate test set. Nine supervised learning algorithms were evaluated and compared, including Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Support Vector Machines (SVMs), and several ensemble methods. Among these, Categorical Boosting (CatBoost) achieved the highest predictive performance, with a test accuracy of 98.75% and an F1-score of 0.9820, outperforming both traditional and other advanced models. Feature importance analysis confirmed the strong influence of cancer history, genetic risk, and smoking status on prediction outcomes. The findings highlight the effectiveness of boosting-based ensemble models in capturing complex interactions within health data and support their potential use in personalized cancer risk assessment. This research underscores the value of integrating genetic and modifiable lifestyle variables into predictive modeling to enhance early detection and preventive healthcare strategies.
期刊介绍:
We publish original research from all areas of the natural sciences, psychology, medicine and engineering. You can learn more about what we publish by browsing our specific scientific subject areas below or explore Scientific Reports by browsing all articles and collections.
Scientific Reports has a 2-year impact factor: 4.380 (2021), and is the 6th most-cited journal in the world, with more than 540,000 citations in 2020 (Clarivate Analytics, 2021).
•Engineering
Engineering covers all aspects of engineering, technology, and applied science. It plays a crucial role in the development of technologies to address some of the world''s biggest challenges, helping to save lives and improve the way we live.
•Physical sciences
Physical sciences are those academic disciplines that aim to uncover the underlying laws of nature — often written in the language of mathematics. It is a collective term for areas of study including astronomy, chemistry, materials science and physics.
•Earth and environmental sciences
Earth and environmental sciences cover all aspects of Earth and planetary science and broadly encompass solid Earth processes, surface and atmospheric dynamics, Earth system history, climate and climate change, marine and freshwater systems, and ecology. It also considers the interactions between humans and these systems.
•Biological sciences
Biological sciences encompass all the divisions of natural sciences examining various aspects of vital processes. The concept includes anatomy, physiology, cell biology, biochemistry and biophysics, and covers all organisms from microorganisms, animals to plants.
•Health sciences
The health sciences study health, disease and healthcare. This field of study aims to develop knowledge, interventions and technology for use in healthcare to improve the treatment of patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


