Onkar Gujral, Mihir Bafna, Eric Alm, Bonnie Berger
{"title":"稀疏自编码器揭示了蛋白质语言模型表示中的生物可解释特征。","authors":"Onkar Gujral, Mihir Bafna, Eric Alm, Bonnie Berger","doi":"10.1073/pnas.2506316122","DOIUrl":null,"url":null,"abstract":"<p><p>Foundation models in biology-particularly protein language models (PLMs)-have enabled ground-breaking predictions in protein structure, function, and beyond. However, the \"black-box\" nature of these representations limits transparency and explainability, posing challenges for human-AI collaboration and leaving open questions about their human-interpretable features. Here, we leverage sparse autoencoders (SAEs) and a variant, transcoders, from natural language processing to extract, in a completely unsupervised fashion, interpretable sparse features present in both protein-level and amino acid (AA)-level representations from ESM2, a popular PLM. Unlike other approaches such as training probes for features, the extraction of features by the SAE is performed without any supervision. We find that many sparse features extracted from SAEs trained on protein-level representations are tightly associated with Gene Ontology (GO) terms across all levels of the GO hierarchy. We also use Anthropic's Claude to automate the interpretation of sparse features for both protein-level and AA-level representations and find that many of these features correspond to specific protein families and functions such as the NAD Kinase, IUNH, and the PTH family, as well as proteins involved in methyltransferase activity and in olfactory and gustatory sensory perception. We show that sparse features are more interpretable than ESM2 neurons across all our trained SAEs and transcoders. These findings demonstrate that SAEs offer a promising unsupervised approach for disentangling biologically relevant information present in PLM representations, thus aiding interpretability. This work opens the door to safety, trust, and explainability of PLMs and their applications, and paves the way to extracting meaningful biological insights across increasingly powerful models in the life sciences.</p>","PeriodicalId":20548,"journal":{"name":"Proceedings of the National Academy of Sciences of the United States of America","volume":"122 34","pages":"e2506316122"},"PeriodicalIF":9.1000,"publicationDate":"2025-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12403088/pdf/","citationCount":"0","resultStr":"{\"title\":\"Sparse autoencoders uncover biologically interpretable features in protein language model representations.\",\"authors\":\"Onkar Gujral, Mihir Bafna, Eric Alm, Bonnie Berger\",\"doi\":\"10.1073/pnas.2506316122\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Foundation models in biology-particularly protein language models (PLMs)-have enabled ground-breaking predictions in protein structure, function, and beyond. However, the \\\"black-box\\\" nature of these representations limits transparency and explainability, posing challenges for human-AI collaboration and leaving open questions about their human-interpretable features. Here, we leverage sparse autoencoders (SAEs) and a variant, transcoders, from natural language processing to extract, in a completely unsupervised fashion, interpretable sparse features present in both protein-level and amino acid (AA)-level representations from ESM2, a popular PLM. Unlike other approaches such as training probes for features, the extraction of features by the SAE is performed without any supervision. We find that many sparse features extracted from SAEs trained on protein-level representations are tightly associated with Gene Ontology (GO) terms across all levels of the GO hierarchy. We also use Anthropic's Claude to automate the interpretation of sparse features for both protein-level and AA-level representations and find that many of these features correspond to specific protein families and functions such as the NAD Kinase, IUNH, and the PTH family, as well as proteins involved in methyltransferase activity and in olfactory and gustatory sensory perception. We show that sparse features are more interpretable than ESM2 neurons across all our trained SAEs and transcoders. These findings demonstrate that SAEs offer a promising unsupervised approach for disentangling biologically relevant information present in PLM representations, thus aiding interpretability. This work opens the door to safety, trust, and explainability of PLMs and their applications, and paves the way to extracting meaningful biological insights across increasingly powerful models in the life sciences.</p>\",\"PeriodicalId\":20548,\"journal\":{\"name\":\"Proceedings of the National Academy of Sciences of the United States of America\",\"volume\":\"122 34\",\"pages\":\"e2506316122\"},\"PeriodicalIF\":9.1000,\"publicationDate\":\"2025-08-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12403088/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Proceedings of the National Academy of Sciences of the United States of America\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1073/pnas.2506316122\",\"RegionNum\":1,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/19 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proceedings of the National Academy of Sciences of the United States of America","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1073/pnas.2506316122","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/19 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Sparse autoencoders uncover biologically interpretable features in protein language model representations.
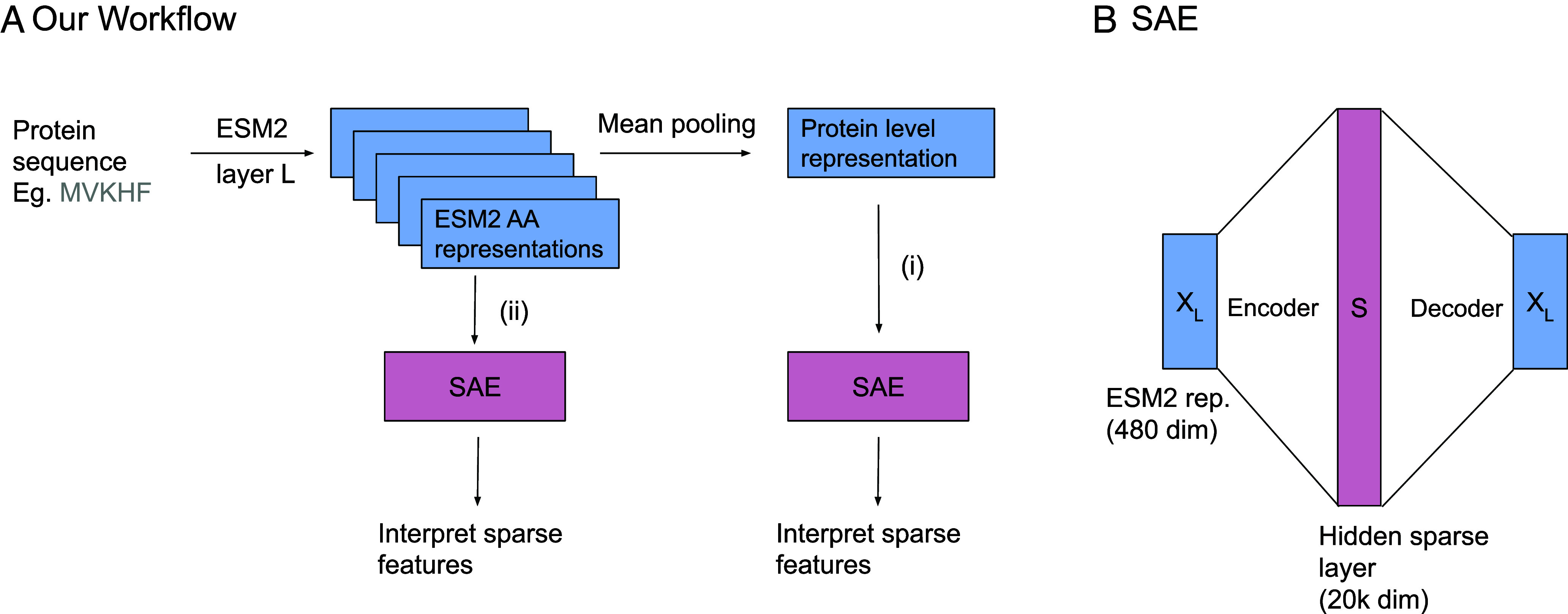
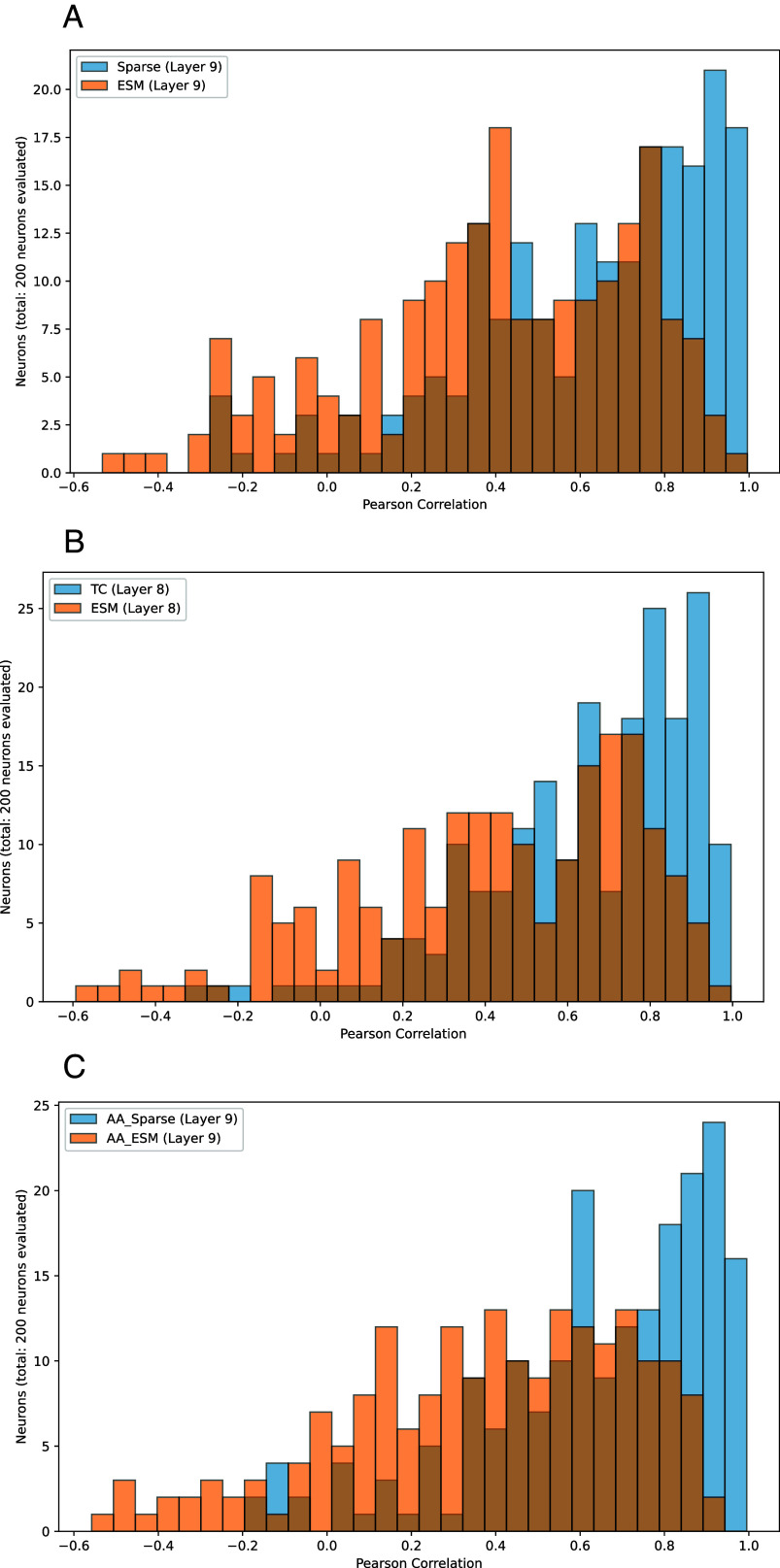
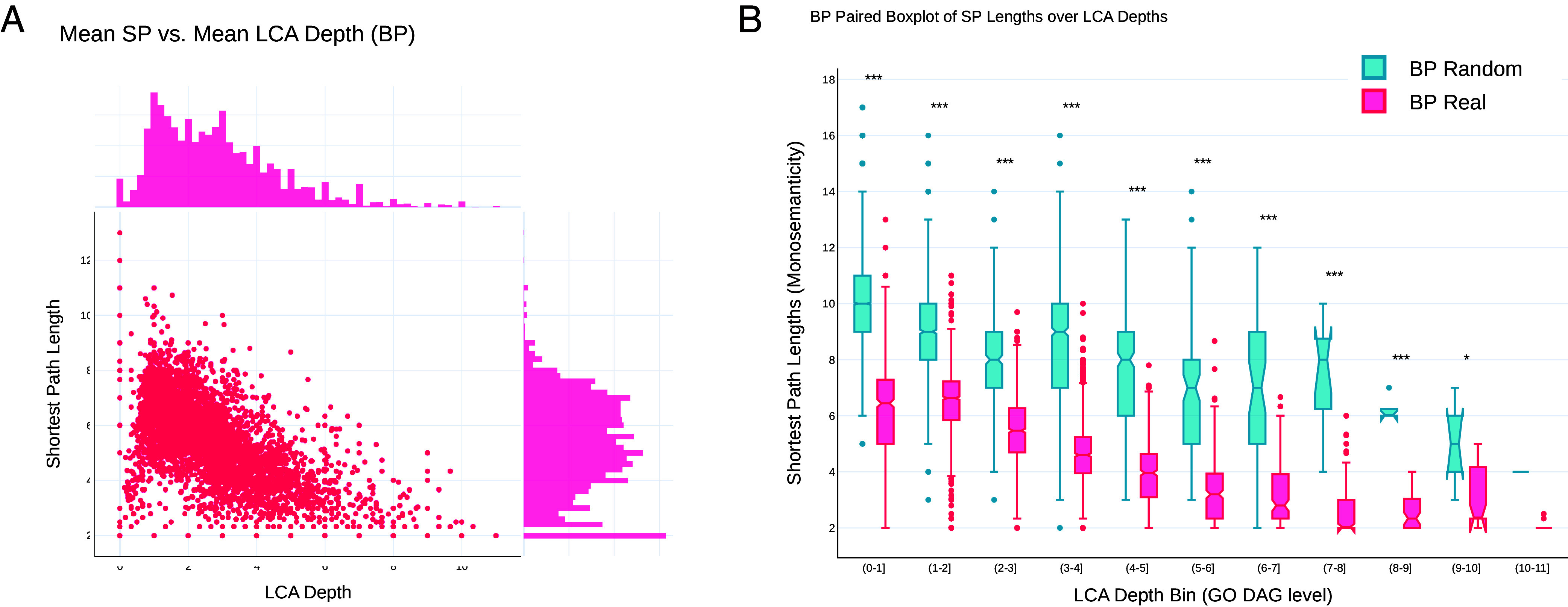
Foundation models in biology-particularly protein language models (PLMs)-have enabled ground-breaking predictions in protein structure, function, and beyond. However, the "black-box" nature of these representations limits transparency and explainability, posing challenges for human-AI collaboration and leaving open questions about their human-interpretable features. Here, we leverage sparse autoencoders (SAEs) and a variant, transcoders, from natural language processing to extract, in a completely unsupervised fashion, interpretable sparse features present in both protein-level and amino acid (AA)-level representations from ESM2, a popular PLM. Unlike other approaches such as training probes for features, the extraction of features by the SAE is performed without any supervision. We find that many sparse features extracted from SAEs trained on protein-level representations are tightly associated with Gene Ontology (GO) terms across all levels of the GO hierarchy. We also use Anthropic's Claude to automate the interpretation of sparse features for both protein-level and AA-level representations and find that many of these features correspond to specific protein families and functions such as the NAD Kinase, IUNH, and the PTH family, as well as proteins involved in methyltransferase activity and in olfactory and gustatory sensory perception. We show that sparse features are more interpretable than ESM2 neurons across all our trained SAEs and transcoders. These findings demonstrate that SAEs offer a promising unsupervised approach for disentangling biologically relevant information present in PLM representations, thus aiding interpretability. This work opens the door to safety, trust, and explainability of PLMs and their applications, and paves the way to extracting meaningful biological insights across increasingly powerful models in the life sciences.
期刊介绍:
The Proceedings of the National Academy of Sciences (PNAS), a peer-reviewed journal of the National Academy of Sciences (NAS), serves as an authoritative source for high-impact, original research across the biological, physical, and social sciences. With a global scope, the journal welcomes submissions from researchers worldwide, making it an inclusive platform for advancing scientific knowledge.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


