Robert Turnbull, Emily Fitzgerald, Karen M Thompson, Joanne L Birch
{"title":"Hespi:从植物标本室标本单中自动检测信息的管道。","authors":"Robert Turnbull, Emily Fitzgerald, Karen M Thompson, Joanne L Birch","doi":"10.1093/biosci/biaf042","DOIUrl":null,"url":null,"abstract":"<p><p>Specimen-associated biodiversity data are crucial for biological, environmental, and conservation sciences. A rate shift is needed to extract data from specimen images efficiently, moving beyond human-mediated transcription. We developed Hespi (for <i>herbarium specimen sheet pipeline</i>) using advanced computer vision techniques to extract authoritative data applicable for a range of research purposes from primary specimen labels on herbarium specimens. Hespi integrates two object detection models: one for detecting the components of the sheet and another for fields on the primary specimen label. It classifies labels as printed, typed, handwritten, or mixed and uses optical character recognition and handwritten text recognition for extraction. The text is then corrected against authoritative taxon databases and refined using a multimodal large language model. Hespi accurately detects and extracts text from specimen sheets across international herbaria, and its modular design allows users to train and integrate custom models.</p>","PeriodicalId":9003,"journal":{"name":"BioScience","volume":"75 8","pages":"637-648"},"PeriodicalIF":7.6000,"publicationDate":"2025-07-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12352312/pdf/","citationCount":"0","resultStr":"{\"title\":\"Hespi: a pipeline for automatically detecting information from herbarium specimen sheets.\",\"authors\":\"Robert Turnbull, Emily Fitzgerald, Karen M Thompson, Joanne L Birch\",\"doi\":\"10.1093/biosci/biaf042\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Specimen-associated biodiversity data are crucial for biological, environmental, and conservation sciences. A rate shift is needed to extract data from specimen images efficiently, moving beyond human-mediated transcription. We developed Hespi (for <i>herbarium specimen sheet pipeline</i>) using advanced computer vision techniques to extract authoritative data applicable for a range of research purposes from primary specimen labels on herbarium specimens. Hespi integrates two object detection models: one for detecting the components of the sheet and another for fields on the primary specimen label. It classifies labels as printed, typed, handwritten, or mixed and uses optical character recognition and handwritten text recognition for extraction. The text is then corrected against authoritative taxon databases and refined using a multimodal large language model. Hespi accurately detects and extracts text from specimen sheets across international herbaria, and its modular design allows users to train and integrate custom models.</p>\",\"PeriodicalId\":9003,\"journal\":{\"name\":\"BioScience\",\"volume\":\"75 8\",\"pages\":\"637-648\"},\"PeriodicalIF\":7.6000,\"publicationDate\":\"2025-07-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12352312/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BioScience\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/biosci/biaf042\",\"RegionNum\":1,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BioScience","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/biosci/biaf042","RegionNum":1,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"BIOLOGY","Score":null,"Total":0}
Hespi: a pipeline for automatically detecting information from herbarium specimen sheets.
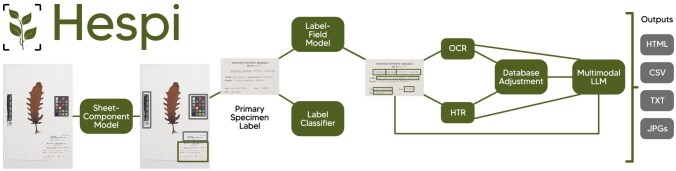
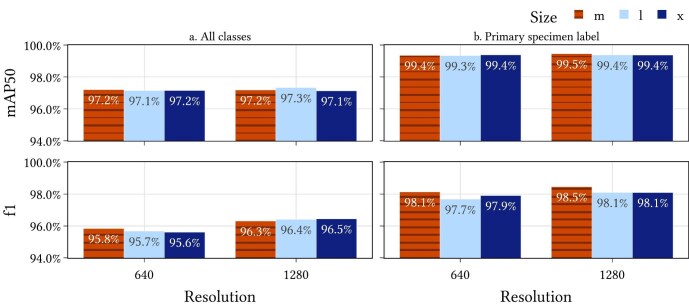
Specimen-associated biodiversity data are crucial for biological, environmental, and conservation sciences. A rate shift is needed to extract data from specimen images efficiently, moving beyond human-mediated transcription. We developed Hespi (for herbarium specimen sheet pipeline) using advanced computer vision techniques to extract authoritative data applicable for a range of research purposes from primary specimen labels on herbarium specimens. Hespi integrates two object detection models: one for detecting the components of the sheet and another for fields on the primary specimen label. It classifies labels as printed, typed, handwritten, or mixed and uses optical character recognition and handwritten text recognition for extraction. The text is then corrected against authoritative taxon databases and refined using a multimodal large language model. Hespi accurately detects and extracts text from specimen sheets across international herbaria, and its modular design allows users to train and integrate custom models.
期刊介绍:
BioScience is a monthly journal that has been in publication since 1964. It provides readers with authoritative and current overviews of biological research. The journal is peer-reviewed and heavily cited, making it a reliable source for researchers, educators, and students. In addition to research articles, BioScience also covers topics such as biology education, public policy, history, and the fundamental principles of the biological sciences. This makes the content accessible to a wide range of readers. The journal includes professionally written feature articles that explore the latest advancements in biology. It also features discussions on professional issues, book reviews, news about the American Institute of Biological Sciences (AIBS), and columns on policy (Washington Watch) and education (Eye on Education).


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


