{"title":"使用大型语言模型从多相催化文献中提取和分析数据","authors":"Benjamin W. Walls, and , Suljo Linic*, ","doi":"10.1021/acscatal.5c03844","DOIUrl":null,"url":null,"abstract":"<p >Extracting experimentally measured heterogeneous catalysis data from the text of research articles into structured databases would facilitate the rapid screening of catalysts with target properties and the development of models capable of directly predicting experimental outcomes. This text mining task has been transformed by the release of large language models (LLMs) capable of following general natural language instructions, which have made it possible to mine text without the need to train task-specific models or define comprehensive expression-matching rules. Here, we develop and share a text mining tool called CatMiner that extracts arbitrary user-specified structure–environment–property data using LLMs. It is agnostic to LLM choice, with both OpenAI GPT models and open-source Llama and DeepSeek models supported without modification. We benchmark the ability of CatMiner to rapidly extract useful data from abundant published literature by focusing on a case study of the oxidative coupling of methane. We explore how model choice and prompting strategies affect extraction quality. Key capabilities, including the use of domain knowledge, iterative prompting, and document-wide context handling are shown to be critical for effective performance. We identify situations where CatMiner struggles and suggest reporting standards for the community to make catalysis data easier to extract going forward. CatMiner enables the creation of machine-readable catalysis datasets, streamlining access to experimental insights buried in the literature.</p>","PeriodicalId":9,"journal":{"name":"ACS Catalysis ","volume":"15 17","pages":"14751–14763"},"PeriodicalIF":13.1000,"publicationDate":"2025-08-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Use of Large Language Models for Extracting and Analyzing Data from Heterogeneous Catalysis Literature\",\"authors\":\"Benjamin W. Walls, and , Suljo Linic*, \",\"doi\":\"10.1021/acscatal.5c03844\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Extracting experimentally measured heterogeneous catalysis data from the text of research articles into structured databases would facilitate the rapid screening of catalysts with target properties and the development of models capable of directly predicting experimental outcomes. This text mining task has been transformed by the release of large language models (LLMs) capable of following general natural language instructions, which have made it possible to mine text without the need to train task-specific models or define comprehensive expression-matching rules. Here, we develop and share a text mining tool called CatMiner that extracts arbitrary user-specified structure–environment–property data using LLMs. It is agnostic to LLM choice, with both OpenAI GPT models and open-source Llama and DeepSeek models supported without modification. We benchmark the ability of CatMiner to rapidly extract useful data from abundant published literature by focusing on a case study of the oxidative coupling of methane. We explore how model choice and prompting strategies affect extraction quality. Key capabilities, including the use of domain knowledge, iterative prompting, and document-wide context handling are shown to be critical for effective performance. We identify situations where CatMiner struggles and suggest reporting standards for the community to make catalysis data easier to extract going forward. CatMiner enables the creation of machine-readable catalysis datasets, streamlining access to experimental insights buried in the literature.</p>\",\"PeriodicalId\":9,\"journal\":{\"name\":\"ACS Catalysis \",\"volume\":\"15 17\",\"pages\":\"14751–14763\"},\"PeriodicalIF\":13.1000,\"publicationDate\":\"2025-08-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ACS Catalysis \",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acscatal.5c03844\",\"RegionNum\":1,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, PHYSICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Catalysis ","FirstCategoryId":"92","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acscatal.5c03844","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
Use of Large Language Models for Extracting and Analyzing Data from Heterogeneous Catalysis Literature
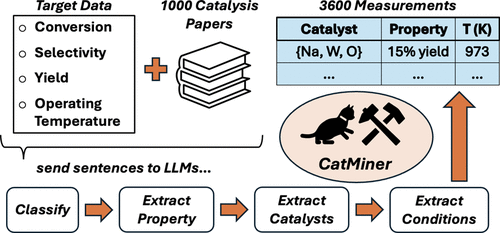
Extracting experimentally measured heterogeneous catalysis data from the text of research articles into structured databases would facilitate the rapid screening of catalysts with target properties and the development of models capable of directly predicting experimental outcomes. This text mining task has been transformed by the release of large language models (LLMs) capable of following general natural language instructions, which have made it possible to mine text without the need to train task-specific models or define comprehensive expression-matching rules. Here, we develop and share a text mining tool called CatMiner that extracts arbitrary user-specified structure–environment–property data using LLMs. It is agnostic to LLM choice, with both OpenAI GPT models and open-source Llama and DeepSeek models supported without modification. We benchmark the ability of CatMiner to rapidly extract useful data from abundant published literature by focusing on a case study of the oxidative coupling of methane. We explore how model choice and prompting strategies affect extraction quality. Key capabilities, including the use of domain knowledge, iterative prompting, and document-wide context handling are shown to be critical for effective performance. We identify situations where CatMiner struggles and suggest reporting standards for the community to make catalysis data easier to extract going forward. CatMiner enables the creation of machine-readable catalysis datasets, streamlining access to experimental insights buried in the literature.
期刊介绍:
ACS Catalysis is an esteemed journal that publishes original research in the fields of heterogeneous catalysis, molecular catalysis, and biocatalysis. It offers broad coverage across diverse areas such as life sciences, organometallics and synthesis, photochemistry and electrochemistry, drug discovery and synthesis, materials science, environmental protection, polymer discovery and synthesis, and energy and fuels.
The scope of the journal is to showcase innovative work in various aspects of catalysis. This includes new reactions and novel synthetic approaches utilizing known catalysts, the discovery or modification of new catalysts, elucidation of catalytic mechanisms through cutting-edge investigations, practical enhancements of existing processes, as well as conceptual advances in the field. Contributions to ACS Catalysis can encompass both experimental and theoretical research focused on catalytic molecules, macromolecules, and materials that exhibit catalytic turnover.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


