O. S. Hafez, O. A. Abouelfetouh, Y. O. Mohamed, M. N. Hasaneen, O. H. Fathy, Y. H. Hassan, M. M. Mahroos, R. A. Elomda, M. M. Ghouneem
{"title":"循环存储器:用于FMCW激光雷达交错/去交错的低延迟单缓冲区技术","authors":"O. S. Hafez, O. A. Abouelfetouh, Y. O. Mohamed, M. N. Hasaneen, O. H. Fathy, Y. H. Hassan, M. M. Mahroos, R. A. Elomda, M. M. Ghouneem","doi":"10.1007/s10470-025-02476-z","DOIUrl":null,"url":null,"abstract":"<div><p>Pipelined systems have long proven their efficiency in high-throughput data processing by enabling concurrent execution of sequential tasks. However, a recurring challenge in such systems is the mismatch between order of data generation and consumption across pipeline stages. This problem imposes a critical constraint: the system must collect new data block while simultaneously reorganizing previously acquired data block–all without interrupting pipeline throughput. A ping-pong buffer allows a system to do so by doubling buffering memory size. This idea increases memory data throughput by not halting the pipeline operation. This paper presents a memory read/write algorithm called “Cyclic Memory” as an alternative to the ping-pong buffering algorithm for the data interleaving/de-interleaving process. Unlike the ping-pong buffering algorithm, the cyclic memory algorithm does not require double buffering. This means that cyclic memory cuts memory requirements in half, uses less area, and consumes less power. This paper will discuss the derivation of the algorithm as well as its implementation.</p></div>","PeriodicalId":7827,"journal":{"name":"Analog Integrated Circuits and Signal Processing","volume":"124 3","pages":""},"PeriodicalIF":1.4000,"publicationDate":"2025-08-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Cyclic memory: a low-latency, single-buffer technique for FMCW LiDAR interleaving/de-interleaving\",\"authors\":\"O. S. Hafez, O. A. Abouelfetouh, Y. O. Mohamed, M. N. Hasaneen, O. H. Fathy, Y. H. Hassan, M. M. Mahroos, R. A. Elomda, M. M. Ghouneem\",\"doi\":\"10.1007/s10470-025-02476-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Pipelined systems have long proven their efficiency in high-throughput data processing by enabling concurrent execution of sequential tasks. However, a recurring challenge in such systems is the mismatch between order of data generation and consumption across pipeline stages. This problem imposes a critical constraint: the system must collect new data block while simultaneously reorganizing previously acquired data block–all without interrupting pipeline throughput. A ping-pong buffer allows a system to do so by doubling buffering memory size. This idea increases memory data throughput by not halting the pipeline operation. This paper presents a memory read/write algorithm called “Cyclic Memory” as an alternative to the ping-pong buffering algorithm for the data interleaving/de-interleaving process. Unlike the ping-pong buffering algorithm, the cyclic memory algorithm does not require double buffering. This means that cyclic memory cuts memory requirements in half, uses less area, and consumes less power. This paper will discuss the derivation of the algorithm as well as its implementation.</p></div>\",\"PeriodicalId\":7827,\"journal\":{\"name\":\"Analog Integrated Circuits and Signal Processing\",\"volume\":\"124 3\",\"pages\":\"\"},\"PeriodicalIF\":1.4000,\"publicationDate\":\"2025-08-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Analog Integrated Circuits and Signal Processing\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10470-025-02476-z\",\"RegionNum\":4,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Analog Integrated Circuits and Signal Processing","FirstCategoryId":"5","ListUrlMain":"https://link.springer.com/article/10.1007/s10470-025-02476-z","RegionNum":4,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
Cyclic memory: a low-latency, single-buffer technique for FMCW LiDAR interleaving/de-interleaving
Pipelined systems have long proven their efficiency in high-throughput data processing by enabling concurrent execution of sequential tasks. However, a recurring challenge in such systems is the mismatch between order of data generation and consumption across pipeline stages. This problem imposes a critical constraint: the system must collect new data block while simultaneously reorganizing previously acquired data block–all without interrupting pipeline throughput. A ping-pong buffer allows a system to do so by doubling buffering memory size. This idea increases memory data throughput by not halting the pipeline operation. This paper presents a memory read/write algorithm called “Cyclic Memory” as an alternative to the ping-pong buffering algorithm for the data interleaving/de-interleaving process. Unlike the ping-pong buffering algorithm, the cyclic memory algorithm does not require double buffering. This means that cyclic memory cuts memory requirements in half, uses less area, and consumes less power. This paper will discuss the derivation of the algorithm as well as its implementation.
期刊介绍:
Analog Integrated Circuits and Signal Processing is an archival peer reviewed journal dedicated to the design and application of analog, radio frequency (RF), and mixed signal integrated circuits (ICs) as well as signal processing circuits and systems. It features both new research results and tutorial views and reflects the large volume of cutting-edge research activity in the worldwide field today.
A partial list of topics includes analog and mixed signal interface circuits and systems; analog and RFIC design; data converters; active-RC, switched-capacitor, and continuous-time integrated filters; mixed analog/digital VLSI systems; wireless radio transceivers; clock and data recovery circuits; and high speed optoelectronic circuits and systems.

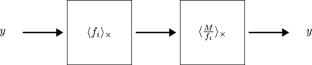

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


