Salman Ul Hassan Dar, Marvin Seyfarth, Isabelle Ayx, Theano Papavassiliu, Stefan O. Schoenberg, Robert Malte Siepmann, Fabian Christopher Laqua, Jannik Kahmann, Norbert Frey, Bettina Baeßler, Sebastian Foersch, Daniel Truhn, Jakob Nikolas Kather, Sandy Engelhardt
{"title":"无条件潜伏扩散模型记忆患者成像数据","authors":"Salman Ul Hassan Dar, Marvin Seyfarth, Isabelle Ayx, Theano Papavassiliu, Stefan O. Schoenberg, Robert Malte Siepmann, Fabian Christopher Laqua, Jannik Kahmann, Norbert Frey, Bettina Baeßler, Sebastian Foersch, Daniel Truhn, Jakob Nikolas Kather, Sandy Engelhardt","doi":"10.1038/s41551-025-01468-8","DOIUrl":null,"url":null,"abstract":"<p>Generative artificial intelligence models facilitate open-data sharing by proposing synthetic data as surrogates of real patient data. Despite the promise for healthcare, some of these models are susceptible to patient data memorization, where models generate patient data copies instead of novel synthetic samples, resulting in patient re-identification. Here we assess memorization in unconditional latent diffusion models by training them on a variety of datasets for synthetic data generation and detecting memorization with a self-supervised copy detection approach. We show a high degree of patient data memorization across all datasets, with approximately 37.2% of patient data detected as memorized and 68.7% of synthetic samples identified as patient data copies. Latent diffusion models are more susceptible to memorization than autoencoders and generative adversarial networks, and they outperform non-diffusion models in synthesis quality. Augmentation strategies during training, small architecture size and increasing datasets can reduce memorization, while overtraining the models can enhance it. These results emphasize the importance of carefully training generative models on private medical imaging datasets and examining the synthetic data to ensure patient privacy.</p>","PeriodicalId":19063,"journal":{"name":"Nature Biomedical Engineering","volume":"290 1","pages":""},"PeriodicalIF":26.8000,"publicationDate":"2025-08-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Unconditional latent diffusion models memorize patient imaging data\",\"authors\":\"Salman Ul Hassan Dar, Marvin Seyfarth, Isabelle Ayx, Theano Papavassiliu, Stefan O. Schoenberg, Robert Malte Siepmann, Fabian Christopher Laqua, Jannik Kahmann, Norbert Frey, Bettina Baeßler, Sebastian Foersch, Daniel Truhn, Jakob Nikolas Kather, Sandy Engelhardt\",\"doi\":\"10.1038/s41551-025-01468-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Generative artificial intelligence models facilitate open-data sharing by proposing synthetic data as surrogates of real patient data. Despite the promise for healthcare, some of these models are susceptible to patient data memorization, where models generate patient data copies instead of novel synthetic samples, resulting in patient re-identification. Here we assess memorization in unconditional latent diffusion models by training them on a variety of datasets for synthetic data generation and detecting memorization with a self-supervised copy detection approach. We show a high degree of patient data memorization across all datasets, with approximately 37.2% of patient data detected as memorized and 68.7% of synthetic samples identified as patient data copies. Latent diffusion models are more susceptible to memorization than autoencoders and generative adversarial networks, and they outperform non-diffusion models in synthesis quality. Augmentation strategies during training, small architecture size and increasing datasets can reduce memorization, while overtraining the models can enhance it. These results emphasize the importance of carefully training generative models on private medical imaging datasets and examining the synthetic data to ensure patient privacy.</p>\",\"PeriodicalId\":19063,\"journal\":{\"name\":\"Nature Biomedical Engineering\",\"volume\":\"290 1\",\"pages\":\"\"},\"PeriodicalIF\":26.8000,\"publicationDate\":\"2025-08-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Biomedical Engineering\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1038/s41551-025-01468-8\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"ENGINEERING, BIOMEDICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Biomedical Engineering","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1038/s41551-025-01468-8","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
Unconditional latent diffusion models memorize patient imaging data
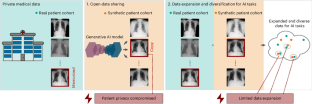
Generative artificial intelligence models facilitate open-data sharing by proposing synthetic data as surrogates of real patient data. Despite the promise for healthcare, some of these models are susceptible to patient data memorization, where models generate patient data copies instead of novel synthetic samples, resulting in patient re-identification. Here we assess memorization in unconditional latent diffusion models by training them on a variety of datasets for synthetic data generation and detecting memorization with a self-supervised copy detection approach. We show a high degree of patient data memorization across all datasets, with approximately 37.2% of patient data detected as memorized and 68.7% of synthetic samples identified as patient data copies. Latent diffusion models are more susceptible to memorization than autoencoders and generative adversarial networks, and they outperform non-diffusion models in synthesis quality. Augmentation strategies during training, small architecture size and increasing datasets can reduce memorization, while overtraining the models can enhance it. These results emphasize the importance of carefully training generative models on private medical imaging datasets and examining the synthetic data to ensure patient privacy.
期刊介绍:
Nature Biomedical Engineering is an online-only monthly journal that was launched in January 2017. It aims to publish original research, reviews, and commentary focusing on applied biomedicine and health technology. The journal targets a diverse audience, including life scientists who are involved in developing experimental or computational systems and methods to enhance our understanding of human physiology. It also covers biomedical researchers and engineers who are engaged in designing or optimizing therapies, assays, devices, or procedures for diagnosing or treating diseases. Additionally, clinicians, who make use of research outputs to evaluate patient health or administer therapy in various clinical settings and healthcare contexts, are also part of the target audience.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


