Richard Gnatzy, Martin Lacher, Salvatore Cascio, Oliver Münsterer, Richard Wagner, Ophelia Aubert
{"title":"儿科外科培训生与人工智能:DeepSeek、Copilot、b谷歌Bard和儿科外科医生在欧洲儿科外科培训考试(EPSITE)中的表现比较分析","authors":"Richard Gnatzy, Martin Lacher, Salvatore Cascio, Oliver Münsterer, Richard Wagner, Ophelia Aubert","doi":"10.1007/s00383-025-06104-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Large language models (LLMs) have advanced rapidly, but their utility in pediatric surgery remains uncertain. This study assessed the performance of three AI models-DeepSeek, Microsoft Copilot (GPT-4) and Google Bard-on the European Pediatric Surgery In-Training Examination (EPSITE).</p><p><strong>Methods: </strong>We evaluated model performance using 294 EPSITE questions from 2021 to 2023. Data for Copilot and Bard were collected in early 2024, while DeepSeek was assessed in 2025. Responses were compared to those of pediatric surgical trainees. Statistical analyses determined performance differences.</p><p><strong>Results: </strong>DeepSeek achieved the highest accuracy (85.0%), followed by Copilot (55.4%) and Bard (48.0%). Pediatric surgical trainees averaged 60.1%. Performance differences were statistically significant (p < 0.0001). DeepSeek significantly outperformed both human trainees and other models (p < 0.0001), while Bard was consistently outperformed by trainees across all training levels (p < 0.01). Sixth-year trainees performed better than Copilot (p < 0.05). Copilot and Bard failed to answer a small portion of questions (3.4% and 4.7%, respectively) due to ethical concerns or perceived lack of correct choices. The time gap between model assessments reflects the rapid evolution of LLMs, contributing to the superior performance of newer models like DeepSeek.</p><p><strong>Conclusion: </strong>LLMs show variable performance in pediatric surgery, with newer models like DeepSeek demonstrating marked improvement. These findings highlight the rapid progression of LLM capabilities and emphasize the need for ongoing evaluation before clinical integration, especially in high-stakes decision-making contexts.</p>","PeriodicalId":19832,"journal":{"name":"Pediatric Surgery International","volume":"41 1","pages":"247"},"PeriodicalIF":1.6000,"publicationDate":"2025-08-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12334501/pdf/","citationCount":"0","resultStr":"{\"title\":\"Pediatric surgical trainees and artificial intelligence: a comparative analysis of DeepSeek, Copilot, Google Bard and pediatric surgeons' performance on the European Pediatric Surgical In-Training Examinations (EPSITE).\",\"authors\":\"Richard Gnatzy, Martin Lacher, Salvatore Cascio, Oliver Münsterer, Richard Wagner, Ophelia Aubert\",\"doi\":\"10.1007/s00383-025-06104-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Large language models (LLMs) have advanced rapidly, but their utility in pediatric surgery remains uncertain. This study assessed the performance of three AI models-DeepSeek, Microsoft Copilot (GPT-4) and Google Bard-on the European Pediatric Surgery In-Training Examination (EPSITE).</p><p><strong>Methods: </strong>We evaluated model performance using 294 EPSITE questions from 2021 to 2023. Data for Copilot and Bard were collected in early 2024, while DeepSeek was assessed in 2025. Responses were compared to those of pediatric surgical trainees. Statistical analyses determined performance differences.</p><p><strong>Results: </strong>DeepSeek achieved the highest accuracy (85.0%), followed by Copilot (55.4%) and Bard (48.0%). Pediatric surgical trainees averaged 60.1%. Performance differences were statistically significant (p < 0.0001). DeepSeek significantly outperformed both human trainees and other models (p < 0.0001), while Bard was consistently outperformed by trainees across all training levels (p < 0.01). Sixth-year trainees performed better than Copilot (p < 0.05). Copilot and Bard failed to answer a small portion of questions (3.4% and 4.7%, respectively) due to ethical concerns or perceived lack of correct choices. The time gap between model assessments reflects the rapid evolution of LLMs, contributing to the superior performance of newer models like DeepSeek.</p><p><strong>Conclusion: </strong>LLMs show variable performance in pediatric surgery, with newer models like DeepSeek demonstrating marked improvement. These findings highlight the rapid progression of LLM capabilities and emphasize the need for ongoing evaluation before clinical integration, especially in high-stakes decision-making contexts.</p>\",\"PeriodicalId\":19832,\"journal\":{\"name\":\"Pediatric Surgery International\",\"volume\":\"41 1\",\"pages\":\"247\"},\"PeriodicalIF\":1.6000,\"publicationDate\":\"2025-08-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12334501/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pediatric Surgery International\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1007/s00383-025-06104-9\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PEDIATRICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pediatric Surgery International","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00383-025-06104-9","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PEDIATRICS","Score":null,"Total":0}
Pediatric surgical trainees and artificial intelligence: a comparative analysis of DeepSeek, Copilot, Google Bard and pediatric surgeons' performance on the European Pediatric Surgical In-Training Examinations (EPSITE).
Objective: Large language models (LLMs) have advanced rapidly, but their utility in pediatric surgery remains uncertain. This study assessed the performance of three AI models-DeepSeek, Microsoft Copilot (GPT-4) and Google Bard-on the European Pediatric Surgery In-Training Examination (EPSITE).
Methods: We evaluated model performance using 294 EPSITE questions from 2021 to 2023. Data for Copilot and Bard were collected in early 2024, while DeepSeek was assessed in 2025. Responses were compared to those of pediatric surgical trainees. Statistical analyses determined performance differences.
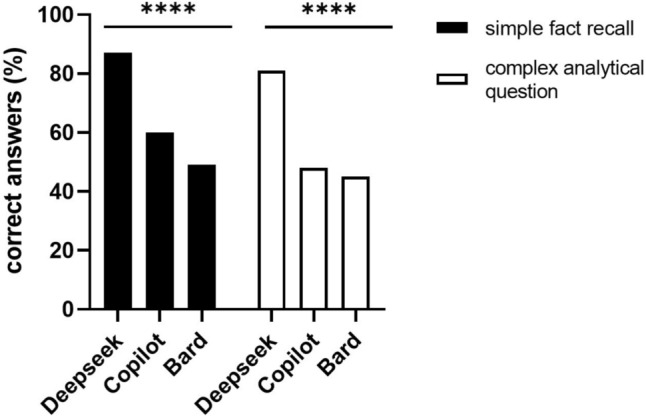
Results: DeepSeek achieved the highest accuracy (85.0%), followed by Copilot (55.4%) and Bard (48.0%). Pediatric surgical trainees averaged 60.1%. Performance differences were statistically significant (p < 0.0001). DeepSeek significantly outperformed both human trainees and other models (p < 0.0001), while Bard was consistently outperformed by trainees across all training levels (p < 0.01). Sixth-year trainees performed better than Copilot (p < 0.05). Copilot and Bard failed to answer a small portion of questions (3.4% and 4.7%, respectively) due to ethical concerns or perceived lack of correct choices. The time gap between model assessments reflects the rapid evolution of LLMs, contributing to the superior performance of newer models like DeepSeek.
Conclusion: LLMs show variable performance in pediatric surgery, with newer models like DeepSeek demonstrating marked improvement. These findings highlight the rapid progression of LLM capabilities and emphasize the need for ongoing evaluation before clinical integration, especially in high-stakes decision-making contexts.
期刊介绍:
Pediatric Surgery International is a journal devoted to the publication of new and important information from the entire spectrum of pediatric surgery. The major purpose of the journal is to promote postgraduate training and further education in the surgery of infants and children.
The contents will include articles in clinical and experimental surgery, as well as related fields. One section of each issue is devoted to a special topic, with invited contributions from recognized authorities. Other sections will include:
-Review articles-
Original articles-
Technical innovations-
Letters to the editor


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


