Ming Yu Hsieh, Tzu-Ling Wang, Pen-Hua Su, Ming-Chih Chou
{"title":"提示工程对医学生考试中不同题型ChatGPT变体性能的影响","authors":"Ming Yu Hsieh, Tzu-Ling Wang, Pen-Hua Su, Ming-Chih Chou","doi":"10.2196/78320","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLMs) such as ChatGPT have shown promise in medical education assessments, but the comparative effects of prompt engineering across optimized variants and relative performance against medical students remain unclear.</p><p><strong>Objective: </strong>To systematically evaluate the impact of prompt engineering on five ChatGPT variants (GPT-3.5, GPT-4.0, GPT-4o, GPT-4o1mini, GPT-4o1) and benchmark their performance against fourth-year medical students in midterm and final examinations.</p><p><strong>Methods: </strong>A 100-item examination dataset covering multiple-choice, short-answer, clinical case analysis, and image-based questions was administered to each model under no-prompt and prompt-engineered conditions over five independent runs. Student cohort scores (n=143) were collected for comparison. Responses were scored using standardized rubrics, converted to percentages, and analyzed in SPSS Statistics 29 with paired t-tests and Cohen's d (p<0.05).</p><p><strong>Results: </strong>Baseline midterm scores ranged from 59.2% (GPT-3.5) to 94.1% (GPT-4o1); final scores from 55.0% to 92.4%. Fourth-year students averaged 89.4% (midterm) and 80.2% (final). Prompt engineering significantly improved GPT-3.5 (+10.6%, p<0.001) and GPT-4.0 (+3.2%, p=0.002) but yielded negligible gains for optimized variants (p=0.066-0.94). Optimized models matched or exceeded student performance on both exams.</p><p><strong>Conclusions: </strong>Prompt engineering enhances early-generation model performance, whereas advanced variants inherently achieve near-ceiling accuracy, surpassing medical students. As LLMs mature, emphasis should shift from prompt design to model selection, multimodal integration, and critical use of AI as a learning companion.</p><p><strong>Clinicaltrial: </strong></p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":" ","pages":""},"PeriodicalIF":3.2000,"publicationDate":"2025-08-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Impact of Prompt Engineering on the Performance of ChatGPT Variants Across Different Question Types in Medical Student Examinations.\",\"authors\":\"Ming Yu Hsieh, Tzu-Ling Wang, Pen-Hua Su, Ming-Chih Chou\",\"doi\":\"10.2196/78320\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Large language models (LLMs) such as ChatGPT have shown promise in medical education assessments, but the comparative effects of prompt engineering across optimized variants and relative performance against medical students remain unclear.</p><p><strong>Objective: </strong>To systematically evaluate the impact of prompt engineering on five ChatGPT variants (GPT-3.5, GPT-4.0, GPT-4o, GPT-4o1mini, GPT-4o1) and benchmark their performance against fourth-year medical students in midterm and final examinations.</p><p><strong>Methods: </strong>A 100-item examination dataset covering multiple-choice, short-answer, clinical case analysis, and image-based questions was administered to each model under no-prompt and prompt-engineered conditions over five independent runs. Student cohort scores (n=143) were collected for comparison. Responses were scored using standardized rubrics, converted to percentages, and analyzed in SPSS Statistics 29 with paired t-tests and Cohen's d (p<0.05).</p><p><strong>Results: </strong>Baseline midterm scores ranged from 59.2% (GPT-3.5) to 94.1% (GPT-4o1); final scores from 55.0% to 92.4%. Fourth-year students averaged 89.4% (midterm) and 80.2% (final). Prompt engineering significantly improved GPT-3.5 (+10.6%, p<0.001) and GPT-4.0 (+3.2%, p=0.002) but yielded negligible gains for optimized variants (p=0.066-0.94). Optimized models matched or exceeded student performance on both exams.</p><p><strong>Conclusions: </strong>Prompt engineering enhances early-generation model performance, whereas advanced variants inherently achieve near-ceiling accuracy, surpassing medical students. As LLMs mature, emphasis should shift from prompt design to model selection, multimodal integration, and critical use of AI as a learning companion.</p><p><strong>Clinicaltrial: </strong></p>\",\"PeriodicalId\":36236,\"journal\":{\"name\":\"JMIR Medical Education\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2025-08-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Education\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/78320\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION, SCIENTIFIC DISCIPLINES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/78320","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
Impact of Prompt Engineering on the Performance of ChatGPT Variants Across Different Question Types in Medical Student Examinations.
Background: Large language models (LLMs) such as ChatGPT have shown promise in medical education assessments, but the comparative effects of prompt engineering across optimized variants and relative performance against medical students remain unclear.
Objective: To systematically evaluate the impact of prompt engineering on five ChatGPT variants (GPT-3.5, GPT-4.0, GPT-4o, GPT-4o1mini, GPT-4o1) and benchmark their performance against fourth-year medical students in midterm and final examinations.
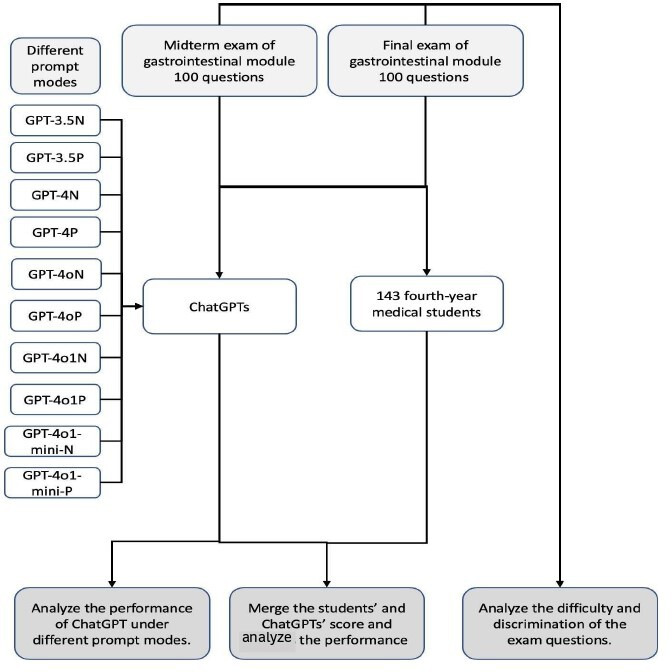
Methods: A 100-item examination dataset covering multiple-choice, short-answer, clinical case analysis, and image-based questions was administered to each model under no-prompt and prompt-engineered conditions over five independent runs. Student cohort scores (n=143) were collected for comparison. Responses were scored using standardized rubrics, converted to percentages, and analyzed in SPSS Statistics 29 with paired t-tests and Cohen's d (p<0.05).
Results: Baseline midterm scores ranged from 59.2% (GPT-3.5) to 94.1% (GPT-4o1); final scores from 55.0% to 92.4%. Fourth-year students averaged 89.4% (midterm) and 80.2% (final). Prompt engineering significantly improved GPT-3.5 (+10.6%, p<0.001) and GPT-4.0 (+3.2%, p=0.002) but yielded negligible gains for optimized variants (p=0.066-0.94). Optimized models matched or exceeded student performance on both exams.
Conclusions: Prompt engineering enhances early-generation model performance, whereas advanced variants inherently achieve near-ceiling accuracy, surpassing medical students. As LLMs mature, emphasis should shift from prompt design to model selection, multimodal integration, and critical use of AI as a learning companion.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


