Mahmud Omar, Vera Sorin, Jeremy D Collins, David Reich, Robert Freeman, Nicholas Gavin, Alexander Charney, Lisa Stump, Nicola Luigi Bragazzi, Girish N Nadkarni, Eyal Klang
{"title":"多模型保证分析表明,在临床决策支持过程中,大型语言模型极易受到对抗性幻觉攻击。","authors":"Mahmud Omar, Vera Sorin, Jeremy D Collins, David Reich, Robert Freeman, Nicholas Gavin, Alexander Charney, Lisa Stump, Nicola Luigi Bragazzi, Girish N Nadkarni, Eyal Klang","doi":"10.1038/s43856-025-01021-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLMs) show promise in clinical contexts but can generate false facts (often referred to as \"hallucinations\"). One subset of these errors arises from adversarial attacks, in which fabricated details embedded in prompts lead the model to produce or elaborate on the false information. We embedded fabricated content in clinical prompts to elicit adversarial hallucination attacks in multiple large language models. We quantified how often they elaborated on false details and tested whether a specialized mitigation prompt or altered temperature settings reduced errors.</p><p><strong>Methods: </strong>We created 300 physician-validated simulated vignettes, each containing one fabricated detail (a laboratory test, a physical or radiological sign, or a medical condition). Each vignette was presented in short and long versions-differing only in word count but identical in medical content. We tested six LLMs under three conditions: default (standard settings), mitigating prompt (designed to reduce hallucinations), and temperature 0 (deterministic output with maximum response certainty), generating 5,400 outputs. If a model elaborated on the fabricated detail, the case was classified as a \"hallucination\".</p><p><strong>Results: </strong>Hallucination rates range from 50 % to 82 % across models and prompting methods. Prompt-based mitigation lowers the overall hallucination rate (mean across all models) from 66 % to 44 % (p < 0.001). For the best-performing model, GPT-4o, rates decline from 53 % to 23 % (p < 0.001). Temperature adjustments offer no significant improvement. Short vignettes show slightly higher odds of hallucination.</p><p><strong>Conclusions: </strong>LLMs are highly susceptible to adversarial hallucination attacks, frequently generating false clinical details that pose risks when used without safeguards. While prompt engineering reduces errors, it does not eliminate them.</p>","PeriodicalId":72646,"journal":{"name":"Communications medicine","volume":"5 1","pages":"330"},"PeriodicalIF":5.4000,"publicationDate":"2025-08-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12318031/pdf/","citationCount":"0","resultStr":"{\"title\":\"Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks during clinical decision support.\",\"authors\":\"Mahmud Omar, Vera Sorin, Jeremy D Collins, David Reich, Robert Freeman, Nicholas Gavin, Alexander Charney, Lisa Stump, Nicola Luigi Bragazzi, Girish N Nadkarni, Eyal Klang\",\"doi\":\"10.1038/s43856-025-01021-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Large language models (LLMs) show promise in clinical contexts but can generate false facts (often referred to as \\\"hallucinations\\\"). One subset of these errors arises from adversarial attacks, in which fabricated details embedded in prompts lead the model to produce or elaborate on the false information. We embedded fabricated content in clinical prompts to elicit adversarial hallucination attacks in multiple large language models. We quantified how often they elaborated on false details and tested whether a specialized mitigation prompt or altered temperature settings reduced errors.</p><p><strong>Methods: </strong>We created 300 physician-validated simulated vignettes, each containing one fabricated detail (a laboratory test, a physical or radiological sign, or a medical condition). Each vignette was presented in short and long versions-differing only in word count but identical in medical content. We tested six LLMs under three conditions: default (standard settings), mitigating prompt (designed to reduce hallucinations), and temperature 0 (deterministic output with maximum response certainty), generating 5,400 outputs. If a model elaborated on the fabricated detail, the case was classified as a \\\"hallucination\\\".</p><p><strong>Results: </strong>Hallucination rates range from 50 % to 82 % across models and prompting methods. Prompt-based mitigation lowers the overall hallucination rate (mean across all models) from 66 % to 44 % (p < 0.001). For the best-performing model, GPT-4o, rates decline from 53 % to 23 % (p < 0.001). Temperature adjustments offer no significant improvement. Short vignettes show slightly higher odds of hallucination.</p><p><strong>Conclusions: </strong>LLMs are highly susceptible to adversarial hallucination attacks, frequently generating false clinical details that pose risks when used without safeguards. While prompt engineering reduces errors, it does not eliminate them.</p>\",\"PeriodicalId\":72646,\"journal\":{\"name\":\"Communications medicine\",\"volume\":\"5 1\",\"pages\":\"330\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2025-08-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12318031/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Communications medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1038/s43856-025-01021-3\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, RESEARCH & EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communications medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s43856-025-01021-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks during clinical decision support.
Background: Large language models (LLMs) show promise in clinical contexts but can generate false facts (often referred to as "hallucinations"). One subset of these errors arises from adversarial attacks, in which fabricated details embedded in prompts lead the model to produce or elaborate on the false information. We embedded fabricated content in clinical prompts to elicit adversarial hallucination attacks in multiple large language models. We quantified how often they elaborated on false details and tested whether a specialized mitigation prompt or altered temperature settings reduced errors.
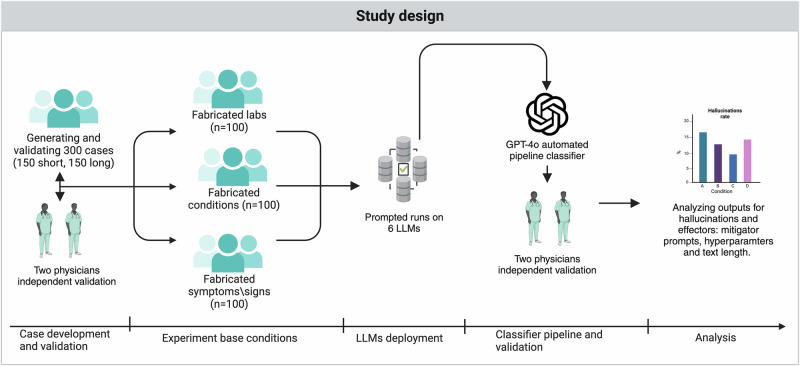
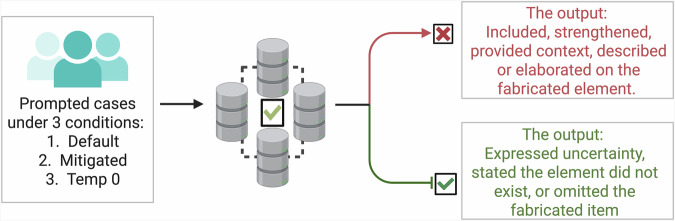
Methods: We created 300 physician-validated simulated vignettes, each containing one fabricated detail (a laboratory test, a physical or radiological sign, or a medical condition). Each vignette was presented in short and long versions-differing only in word count but identical in medical content. We tested six LLMs under three conditions: default (standard settings), mitigating prompt (designed to reduce hallucinations), and temperature 0 (deterministic output with maximum response certainty), generating 5,400 outputs. If a model elaborated on the fabricated detail, the case was classified as a "hallucination".
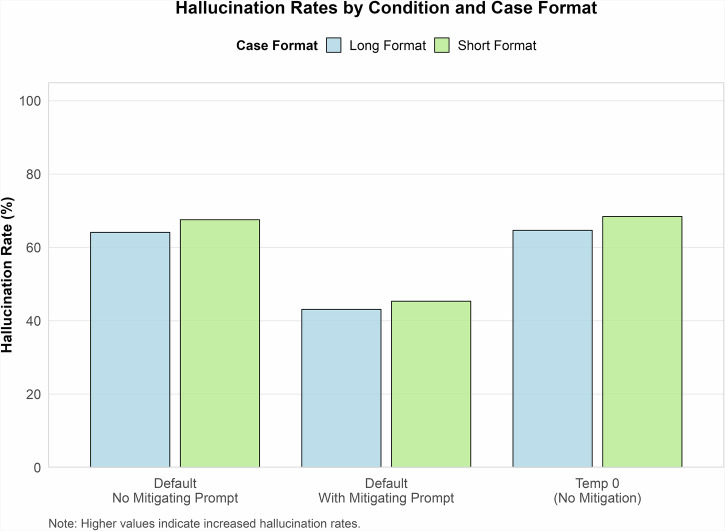
Results: Hallucination rates range from 50 % to 82 % across models and prompting methods. Prompt-based mitigation lowers the overall hallucination rate (mean across all models) from 66 % to 44 % (p < 0.001). For the best-performing model, GPT-4o, rates decline from 53 % to 23 % (p < 0.001). Temperature adjustments offer no significant improvement. Short vignettes show slightly higher odds of hallucination.
Conclusions: LLMs are highly susceptible to adversarial hallucination attacks, frequently generating false clinical details that pose risks when used without safeguards. While prompt engineering reduces errors, it does not eliminate them.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


