Eben Holderness, Bruce Atwood, Marc Verhagen, Ann K Shinn, Philip Cawkwell, Hudson Cerruti, James Pustejovsky, Mei-Hua Hall
{"title":"精神健康记录中的机器学习:创伤注释的金标准方法。","authors":"Eben Holderness, Bruce Atwood, Marc Verhagen, Ann K Shinn, Philip Cawkwell, Hudson Cerruti, James Pustejovsky, Mei-Hua Hall","doi":"10.1038/s41398-025-03487-0","DOIUrl":null,"url":null,"abstract":"<p><p>Psychiatric electronic health records present unique challenges for machine learning due to their unstructured, complex, and variable nature. This study aimed to create a gold standard dataset by identifying a cohort of patients with psychotic disorders and posttraumatic stress disorder, (PTSD), developing clinically-informed guidelines for annotating traumatic events in their health records and to create a gold standard publicly available dataset, and demonstrating the dataset's suitability for training machine learning models to detect indicators of symptoms, substance use, and trauma in new records. We compiled a representative corpus of 200 narrative heavy health records (470,489 tokens) from a centralized database and developed a detailed annotation scheme with a team of clinical experts and computational linguistics. Clinicians annotated the corpus for trauma-related events and relevant clinical information with high inter-annotator agreement (0.715 for entity/span tags and 0.874 for attributes). Additionally, machine learning models were developed to demonstrate practical viability of the gold standard corpus for machine learning applications, achieving a micro F1 score of 0.76 and 0.82 for spans and attributes respectively, indicative of their predictive reliability. This study established the first gold-standard dataset for the complex task of labelling traumatic features in psychiatric health records. High inter-annotator agreement and model performance illustrate its utility in advancing the application of machine learning in psychiatric healthcare in order to better understand disease heterogeneity and treatment implications.</p>","PeriodicalId":23278,"journal":{"name":"Translational Psychiatry","volume":"15 1","pages":"260"},"PeriodicalIF":6.2000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12317041/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine learning in psychiatric health records: A gold standard approach to trauma annotation.\",\"authors\":\"Eben Holderness, Bruce Atwood, Marc Verhagen, Ann K Shinn, Philip Cawkwell, Hudson Cerruti, James Pustejovsky, Mei-Hua Hall\",\"doi\":\"10.1038/s41398-025-03487-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Psychiatric electronic health records present unique challenges for machine learning due to their unstructured, complex, and variable nature. This study aimed to create a gold standard dataset by identifying a cohort of patients with psychotic disorders and posttraumatic stress disorder, (PTSD), developing clinically-informed guidelines for annotating traumatic events in their health records and to create a gold standard publicly available dataset, and demonstrating the dataset's suitability for training machine learning models to detect indicators of symptoms, substance use, and trauma in new records. We compiled a representative corpus of 200 narrative heavy health records (470,489 tokens) from a centralized database and developed a detailed annotation scheme with a team of clinical experts and computational linguistics. Clinicians annotated the corpus for trauma-related events and relevant clinical information with high inter-annotator agreement (0.715 for entity/span tags and 0.874 for attributes). Additionally, machine learning models were developed to demonstrate practical viability of the gold standard corpus for machine learning applications, achieving a micro F1 score of 0.76 and 0.82 for spans and attributes respectively, indicative of their predictive reliability. This study established the first gold-standard dataset for the complex task of labelling traumatic features in psychiatric health records. High inter-annotator agreement and model performance illustrate its utility in advancing the application of machine learning in psychiatric healthcare in order to better understand disease heterogeneity and treatment implications.</p>\",\"PeriodicalId\":23278,\"journal\":{\"name\":\"Translational Psychiatry\",\"volume\":\"15 1\",\"pages\":\"260\"},\"PeriodicalIF\":6.2000,\"publicationDate\":\"2025-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12317041/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Translational Psychiatry\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1038/s41398-025-03487-0\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHIATRY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Translational Psychiatry","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41398-025-03487-0","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PSYCHIATRY","Score":null,"Total":0}
Machine learning in psychiatric health records: A gold standard approach to trauma annotation.
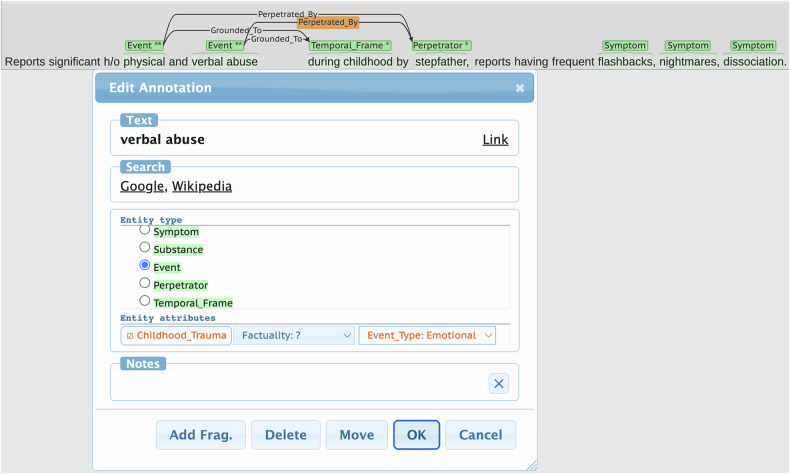
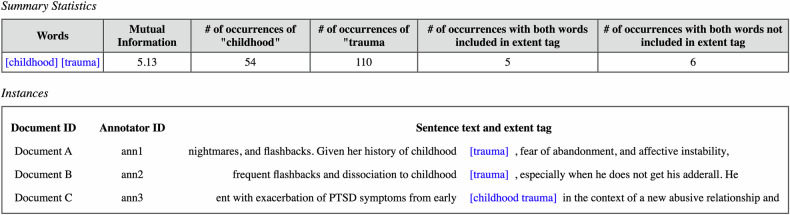
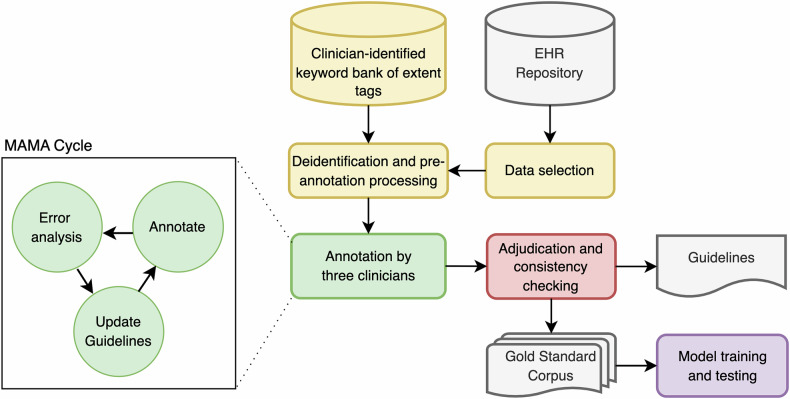
Psychiatric electronic health records present unique challenges for machine learning due to their unstructured, complex, and variable nature. This study aimed to create a gold standard dataset by identifying a cohort of patients with psychotic disorders and posttraumatic stress disorder, (PTSD), developing clinically-informed guidelines for annotating traumatic events in their health records and to create a gold standard publicly available dataset, and demonstrating the dataset's suitability for training machine learning models to detect indicators of symptoms, substance use, and trauma in new records. We compiled a representative corpus of 200 narrative heavy health records (470,489 tokens) from a centralized database and developed a detailed annotation scheme with a team of clinical experts and computational linguistics. Clinicians annotated the corpus for trauma-related events and relevant clinical information with high inter-annotator agreement (0.715 for entity/span tags and 0.874 for attributes). Additionally, machine learning models were developed to demonstrate practical viability of the gold standard corpus for machine learning applications, achieving a micro F1 score of 0.76 and 0.82 for spans and attributes respectively, indicative of their predictive reliability. This study established the first gold-standard dataset for the complex task of labelling traumatic features in psychiatric health records. High inter-annotator agreement and model performance illustrate its utility in advancing the application of machine learning in psychiatric healthcare in order to better understand disease heterogeneity and treatment implications.
期刊介绍:
Psychiatry has suffered tremendously by the limited translational pipeline. Nobel laureate Julius Axelrod''s discovery in 1961 of monoamine reuptake by pre-synaptic neurons still forms the basis of contemporary antidepressant treatment. There is a grievous gap between the explosion of knowledge in neuroscience and conceptually novel treatments for our patients. Translational Psychiatry bridges this gap by fostering and highlighting the pathway from discovery to clinical applications, healthcare and global health. We view translation broadly as the full spectrum of work that marks the pathway from discovery to global health, inclusive. The steps of translation that are within the scope of Translational Psychiatry include (i) fundamental discovery, (ii) bench to bedside, (iii) bedside to clinical applications (clinical trials), (iv) translation to policy and health care guidelines, (v) assessment of health policy and usage, and (vi) global health. All areas of medical research, including — but not restricted to — molecular biology, genetics, pharmacology, imaging and epidemiology are welcome as they contribute to enhance the field of translational psychiatry.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


