Samir Cayenne, Natalia Penaloza, Anne C Chan, M I Tahashilder, Rodney C Guiseppi, Touka Banaee
{"title":"利用ChatGPT-3.5辅助眼科医生进行临床决策。","authors":"Samir Cayenne, Natalia Penaloza, Anne C Chan, M I Tahashilder, Rodney C Guiseppi, Touka Banaee","doi":"10.18502/jovr.v20.14692","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>ChatGPT-3.5 has the potential to assist ophthalmologists by generating a differential diagnosis based on patient presentation.</p><p><strong>Methods: </strong>One hundred ocular pathologies were tested. Each pathology had two signs and two symptoms prompted into ChatGPT-3.5 through a clinical vignette template to generate a list of four preferentially ordered differential diagnoses, denoted as Method A. Thirty of the original 100 pathologies were further subcategorized into three groups of 10: cornea, retina, and neuro-ophthalmology. To assess whether additional clinical information affected the accuracy of results, these subcategories were again prompted into ChatGPT-3.5 with the same previous two signs and symptoms, along with additional risk factors of age, sex, and past medical history, denoted as Method B. A one-tailed Wilcoxon signed-rank test was performed to compare the accuracy between Methods A and B across each subcategory (significance indicated by <i>P</i> <math><mo><</mo></math> 0.05).</p><p><strong>Results: </strong>ChatGPT-3.5 correctly diagnosed 51 out of 100 cases (51.00%) as its first differential diagnosis and 18 out of 100 cases (18.00%) as a differential other than its first diagnosis. However, 31 out of 100 cases (31.00%) were not included in the differential diagnosis list. Only the subcategory of neuro-ophthalmology showed a significant increase in accuracy (<i>P</i> = 0.01) when prompted with the additional risk factors (Method B) compared to only two signs and two symptoms (Method A).</p><p><strong>Conclusion: </strong>These results demonstrate that ChatGPT-3.5 may help assist clinicians in suggesting possible diagnoses based on varying complex clinical information. However, its accuracy is limited, and it cannot be utilized as a replacement for clinical decision-making.</p>","PeriodicalId":16586,"journal":{"name":"Journal of Ophthalmic & Vision Research","volume":"20 ","pages":""},"PeriodicalIF":1.5000,"publicationDate":"2025-05-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12257982/pdf/","citationCount":"0","resultStr":"{\"title\":\"Utilizing ChatGPT-3.5 to Assist Ophthalmologists in Clinical Decision-making.\",\"authors\":\"Samir Cayenne, Natalia Penaloza, Anne C Chan, M I Tahashilder, Rodney C Guiseppi, Touka Banaee\",\"doi\":\"10.18502/jovr.v20.14692\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>ChatGPT-3.5 has the potential to assist ophthalmologists by generating a differential diagnosis based on patient presentation.</p><p><strong>Methods: </strong>One hundred ocular pathologies were tested. Each pathology had two signs and two symptoms prompted into ChatGPT-3.5 through a clinical vignette template to generate a list of four preferentially ordered differential diagnoses, denoted as Method A. Thirty of the original 100 pathologies were further subcategorized into three groups of 10: cornea, retina, and neuro-ophthalmology. To assess whether additional clinical information affected the accuracy of results, these subcategories were again prompted into ChatGPT-3.5 with the same previous two signs and symptoms, along with additional risk factors of age, sex, and past medical history, denoted as Method B. A one-tailed Wilcoxon signed-rank test was performed to compare the accuracy between Methods A and B across each subcategory (significance indicated by <i>P</i> <math><mo><</mo></math> 0.05).</p><p><strong>Results: </strong>ChatGPT-3.5 correctly diagnosed 51 out of 100 cases (51.00%) as its first differential diagnosis and 18 out of 100 cases (18.00%) as a differential other than its first diagnosis. However, 31 out of 100 cases (31.00%) were not included in the differential diagnosis list. Only the subcategory of neuro-ophthalmology showed a significant increase in accuracy (<i>P</i> = 0.01) when prompted with the additional risk factors (Method B) compared to only two signs and two symptoms (Method A).</p><p><strong>Conclusion: </strong>These results demonstrate that ChatGPT-3.5 may help assist clinicians in suggesting possible diagnoses based on varying complex clinical information. However, its accuracy is limited, and it cannot be utilized as a replacement for clinical decision-making.</p>\",\"PeriodicalId\":16586,\"journal\":{\"name\":\"Journal of Ophthalmic & Vision Research\",\"volume\":\"20 \",\"pages\":\"\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2025-05-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12257982/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Ophthalmic & Vision Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.18502/jovr.v20.14692\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"OPHTHALMOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Ophthalmic & Vision Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.18502/jovr.v20.14692","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
Utilizing ChatGPT-3.5 to Assist Ophthalmologists in Clinical Decision-making.
Purpose: ChatGPT-3.5 has the potential to assist ophthalmologists by generating a differential diagnosis based on patient presentation.
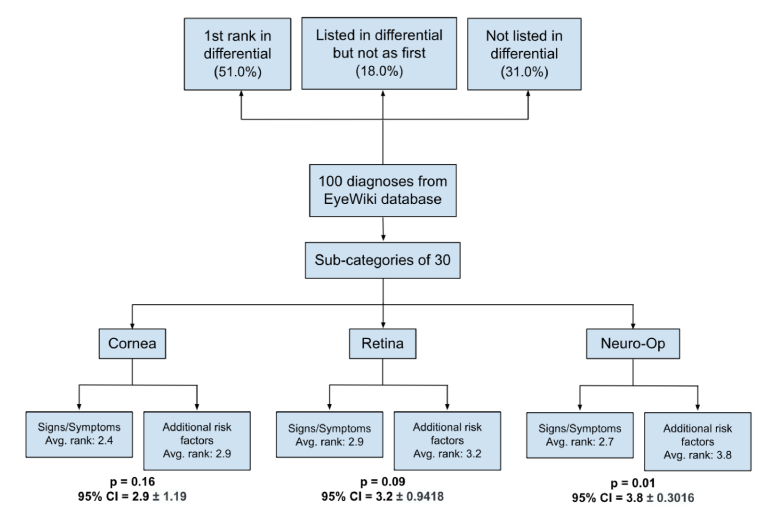
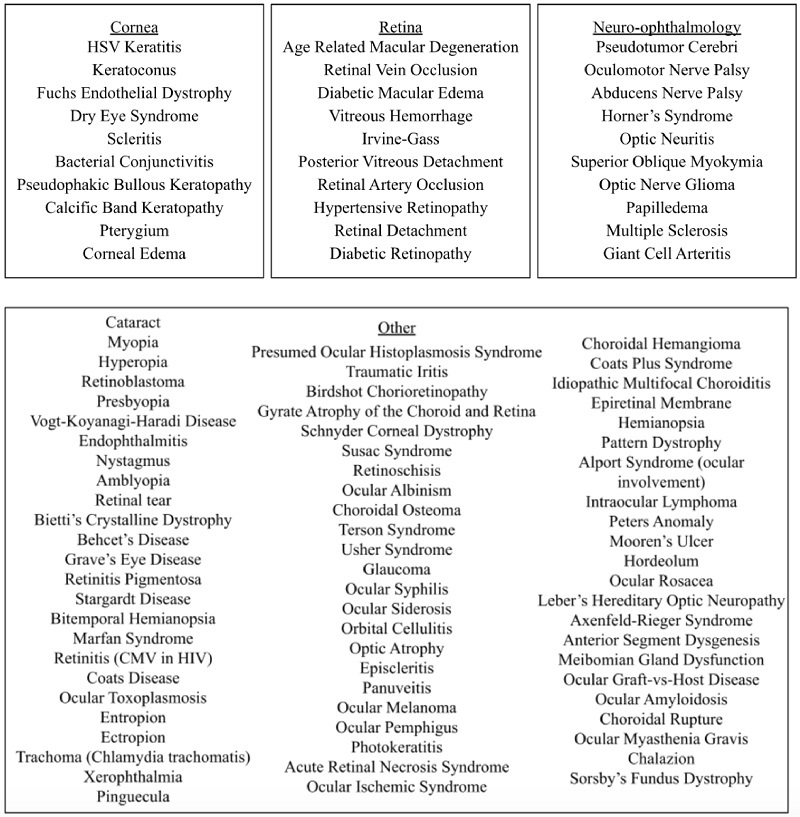
Methods: One hundred ocular pathologies were tested. Each pathology had two signs and two symptoms prompted into ChatGPT-3.5 through a clinical vignette template to generate a list of four preferentially ordered differential diagnoses, denoted as Method A. Thirty of the original 100 pathologies were further subcategorized into three groups of 10: cornea, retina, and neuro-ophthalmology. To assess whether additional clinical information affected the accuracy of results, these subcategories were again prompted into ChatGPT-3.5 with the same previous two signs and symptoms, along with additional risk factors of age, sex, and past medical history, denoted as Method B. A one-tailed Wilcoxon signed-rank test was performed to compare the accuracy between Methods A and B across each subcategory (significance indicated by P 0.05).
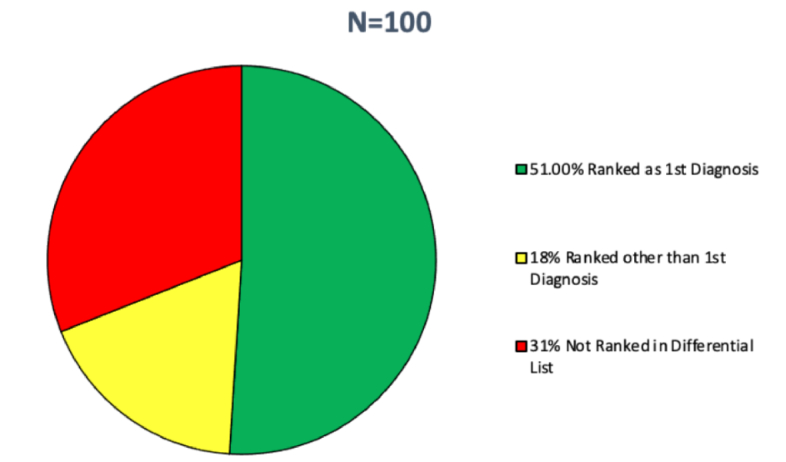
Results: ChatGPT-3.5 correctly diagnosed 51 out of 100 cases (51.00%) as its first differential diagnosis and 18 out of 100 cases (18.00%) as a differential other than its first diagnosis. However, 31 out of 100 cases (31.00%) were not included in the differential diagnosis list. Only the subcategory of neuro-ophthalmology showed a significant increase in accuracy (P = 0.01) when prompted with the additional risk factors (Method B) compared to only two signs and two symptoms (Method A).
Conclusion: These results demonstrate that ChatGPT-3.5 may help assist clinicians in suggesting possible diagnoses based on varying complex clinical information. However, its accuracy is limited, and it cannot be utilized as a replacement for clinical decision-making.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


