Jesse van Remmerden, Zaharah Bukhsh, Yingqian Zhang
{"title":"离线强化学习学习调度作业车间调度。","authors":"Jesse van Remmerden, Zaharah Bukhsh, Yingqian Zhang","doi":"10.1007/s10994-025-06826-w","DOIUrl":null,"url":null,"abstract":"<p><p>The Job Shop Scheduling Problem (JSSP) is a complex combinatorial optimization problem. While online Reinforcement Learning (RL) has shown promise by quickly finding acceptable solutions for JSSP, it faces key limitations: it requires extensive training interactions from scratch leading to sample inefficiency, cannot leverage existing high-quality solutions from traditional methods like Constraint Programming (CP), and require simulated environments to train in, which are impracticable to build for complex scheduling environments. We introduce Offline Learned Dispatching (Offline-LD), an offline reinforcement learning approach for JSSP, which addresses these limitations by learning from historical scheduling data. Our approach is motivated by scenarios where historical scheduling data and expert solutions are available or scenarios where online training of RL approaches with simulated environments is impracticable. Offline-LD introduces maskable variants of two Q-learning methods, namely, Maskable Quantile Regression DQN (mQRDQN) and discrete maskable Soft Actor-Critic (d-mSAC), that are able to learn from historical data, through Conservative Q-Learning (CQL), whereby we present a novel entropy bonus modification for d-mSAC, for maskable action spaces. Moreover, we introduce a novel reward normalization method for JSSP in an offline RL setting. Our experiments demonstrate that Offline-LD outperforms online RL on both generated and benchmark instances when trained on only 100 solutions generated by CP. Notably, introducing noise to the expert dataset yields comparable or superior results to using the expert dataset, with the same amount of instances, a promising finding for real-world applications, where data is inherently noisy and imperfect.</p>","PeriodicalId":49900,"journal":{"name":"Machine Learning","volume":"114 8","pages":"191"},"PeriodicalIF":2.9000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12263752/pdf/","citationCount":"0","resultStr":"{\"title\":\"Offline reinforcement learning for learning to dispatch for job shop scheduling.\",\"authors\":\"Jesse van Remmerden, Zaharah Bukhsh, Yingqian Zhang\",\"doi\":\"10.1007/s10994-025-06826-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The Job Shop Scheduling Problem (JSSP) is a complex combinatorial optimization problem. While online Reinforcement Learning (RL) has shown promise by quickly finding acceptable solutions for JSSP, it faces key limitations: it requires extensive training interactions from scratch leading to sample inefficiency, cannot leverage existing high-quality solutions from traditional methods like Constraint Programming (CP), and require simulated environments to train in, which are impracticable to build for complex scheduling environments. We introduce Offline Learned Dispatching (Offline-LD), an offline reinforcement learning approach for JSSP, which addresses these limitations by learning from historical scheduling data. Our approach is motivated by scenarios where historical scheduling data and expert solutions are available or scenarios where online training of RL approaches with simulated environments is impracticable. Offline-LD introduces maskable variants of two Q-learning methods, namely, Maskable Quantile Regression DQN (mQRDQN) and discrete maskable Soft Actor-Critic (d-mSAC), that are able to learn from historical data, through Conservative Q-Learning (CQL), whereby we present a novel entropy bonus modification for d-mSAC, for maskable action spaces. Moreover, we introduce a novel reward normalization method for JSSP in an offline RL setting. Our experiments demonstrate that Offline-LD outperforms online RL on both generated and benchmark instances when trained on only 100 solutions generated by CP. Notably, introducing noise to the expert dataset yields comparable or superior results to using the expert dataset, with the same amount of instances, a promising finding for real-world applications, where data is inherently noisy and imperfect.</p>\",\"PeriodicalId\":49900,\"journal\":{\"name\":\"Machine Learning\",\"volume\":\"114 8\",\"pages\":\"191\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12263752/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Machine Learning\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10994-025-06826-w\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/7/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Learning","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10994-025-06826-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/15 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Offline reinforcement learning for learning to dispatch for job shop scheduling.
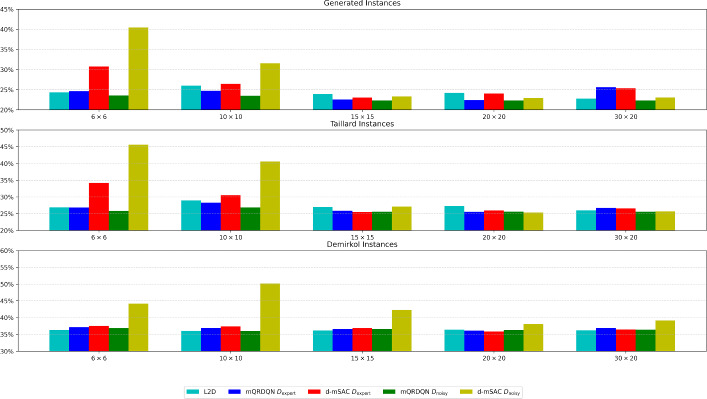
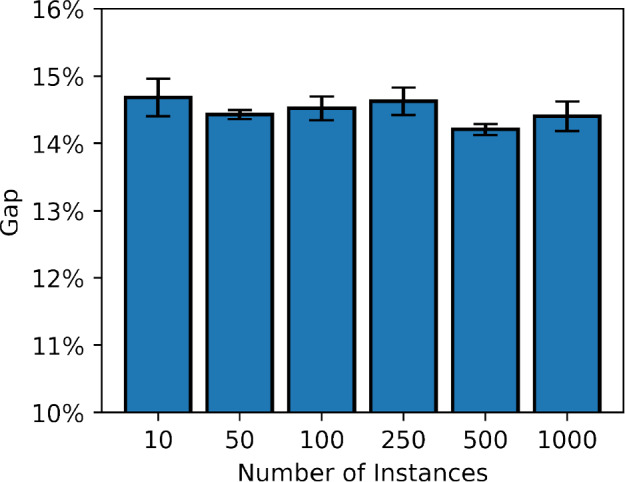
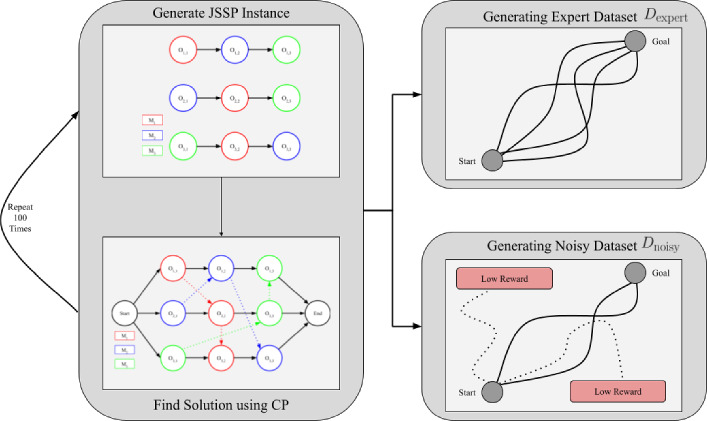
The Job Shop Scheduling Problem (JSSP) is a complex combinatorial optimization problem. While online Reinforcement Learning (RL) has shown promise by quickly finding acceptable solutions for JSSP, it faces key limitations: it requires extensive training interactions from scratch leading to sample inefficiency, cannot leverage existing high-quality solutions from traditional methods like Constraint Programming (CP), and require simulated environments to train in, which are impracticable to build for complex scheduling environments. We introduce Offline Learned Dispatching (Offline-LD), an offline reinforcement learning approach for JSSP, which addresses these limitations by learning from historical scheduling data. Our approach is motivated by scenarios where historical scheduling data and expert solutions are available or scenarios where online training of RL approaches with simulated environments is impracticable. Offline-LD introduces maskable variants of two Q-learning methods, namely, Maskable Quantile Regression DQN (mQRDQN) and discrete maskable Soft Actor-Critic (d-mSAC), that are able to learn from historical data, through Conservative Q-Learning (CQL), whereby we present a novel entropy bonus modification for d-mSAC, for maskable action spaces. Moreover, we introduce a novel reward normalization method for JSSP in an offline RL setting. Our experiments demonstrate that Offline-LD outperforms online RL on both generated and benchmark instances when trained on only 100 solutions generated by CP. Notably, introducing noise to the expert dataset yields comparable or superior results to using the expert dataset, with the same amount of instances, a promising finding for real-world applications, where data is inherently noisy and imperfect.
期刊介绍:
Machine Learning serves as a global platform dedicated to computational approaches in learning. The journal reports substantial findings on diverse learning methods applied to various problems, offering support through empirical studies, theoretical analysis, or connections to psychological phenomena. It demonstrates the application of learning methods to solve significant problems and aims to enhance the conduct of machine learning research with a focus on verifiable and replicable evidence in published papers.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


