Robert Y Lee, Kevin S Li, James Sibley, Trevor Cohen, William B Lober, Janaki O'Brien, Nicole LeDuc, Kasey Mallon Andrews, Anna Ungar, Jessica Walsh, Elizabeth L Nielsen, Danae G Dotolo, Erin K Kross
{"title":"一个用于自然语言处理的模块化管道筛选了电子健康记录中实用试验结果的人类抽象。","authors":"Robert Y Lee, Kevin S Li, James Sibley, Trevor Cohen, William B Lober, Janaki O'Brien, Nicole LeDuc, Kasey Mallon Andrews, Anna Ungar, Jessica Walsh, Elizabeth L Nielsen, Danae G Dotolo, Erin K Kross","doi":"10.1101/2025.06.23.25330134","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Natural language processing (NLP) allows efficient extraction of clinical variables and outcomes from electronic health records (EHR). However, measuring pragmatic clinical trial outcomes may demand accuracy that exceeds NLP performance. Combining NLP with human adjudication can address this gap, yet few software solutions support such workflows. We developed a modular, scalable system for NLP-screened human abstraction to measure the primary outcomes of two clinical trials.</p><p><strong>Methods: </strong>In two clinical trials of hospitalized patients with serious illness, a deep-learning NLP model screened EHR passages for documented goals-of-care discussions. Screen-positive passages were referred for human adjudication using a REDCap-based system to measure the trial outcomes. Dynamic pooling of passages using structured query language (SQL) within the REDCap database reduced unnecessary abstraction while ensuring data completeness.</p><p><strong>Results: </strong>In the first trial (N=2,512), NLP identified 22,187 screen-positive passages (0.8%) from 2.6 million EHR passages. Human reviewers adjudicated 7,494 passages over 34.3 abstractor-hours to measure the cumulative incidence and time to first documented goals-of-care discussion for all patients with 92.6% patient-level sensitivity. In the second trial (N=617), NLP identified 8,952 screen-positive passages (1.6%) from 559,596 passages at a threshold with near-100% sensitivity. Human reviewers adjudicated 3,509 passages over 27.9 abstractor-hours to measure the same outcome for all patients.</p><p><strong>Conclusion: </strong>We present the design and source code for a scalable and efficient pipeline for measuring complex EHR-derived outcomes using NLP-screened human abstraction. This implementation is adaptable to diverse research needs, and its modular pipeline represents a practical middle ground between custom software and commercial platforms.</p>","PeriodicalId":94281,"journal":{"name":"medRxiv : the preprint server for health sciences","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12262768/pdf/","citationCount":"0","resultStr":"{\"title\":\"A modular pipeline for natural language processing-screened human abstraction of a pragmatic trial outcome from electronic health records.\",\"authors\":\"Robert Y Lee, Kevin S Li, James Sibley, Trevor Cohen, William B Lober, Janaki O'Brien, Nicole LeDuc, Kasey Mallon Andrews, Anna Ungar, Jessica Walsh, Elizabeth L Nielsen, Danae G Dotolo, Erin K Kross\",\"doi\":\"10.1101/2025.06.23.25330134\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Natural language processing (NLP) allows efficient extraction of clinical variables and outcomes from electronic health records (EHR). However, measuring pragmatic clinical trial outcomes may demand accuracy that exceeds NLP performance. Combining NLP with human adjudication can address this gap, yet few software solutions support such workflows. We developed a modular, scalable system for NLP-screened human abstraction to measure the primary outcomes of two clinical trials.</p><p><strong>Methods: </strong>In two clinical trials of hospitalized patients with serious illness, a deep-learning NLP model screened EHR passages for documented goals-of-care discussions. Screen-positive passages were referred for human adjudication using a REDCap-based system to measure the trial outcomes. Dynamic pooling of passages using structured query language (SQL) within the REDCap database reduced unnecessary abstraction while ensuring data completeness.</p><p><strong>Results: </strong>In the first trial (N=2,512), NLP identified 22,187 screen-positive passages (0.8%) from 2.6 million EHR passages. Human reviewers adjudicated 7,494 passages over 34.3 abstractor-hours to measure the cumulative incidence and time to first documented goals-of-care discussion for all patients with 92.6% patient-level sensitivity. In the second trial (N=617), NLP identified 8,952 screen-positive passages (1.6%) from 559,596 passages at a threshold with near-100% sensitivity. Human reviewers adjudicated 3,509 passages over 27.9 abstractor-hours to measure the same outcome for all patients.</p><p><strong>Conclusion: </strong>We present the design and source code for a scalable and efficient pipeline for measuring complex EHR-derived outcomes using NLP-screened human abstraction. This implementation is adaptable to diverse research needs, and its modular pipeline represents a practical middle ground between custom software and commercial platforms.</p>\",\"PeriodicalId\":94281,\"journal\":{\"name\":\"medRxiv : the preprint server for health sciences\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-09-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12262768/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"medRxiv : the preprint server for health sciences\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1101/2025.06.23.25330134\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"medRxiv : the preprint server for health sciences","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2025.06.23.25330134","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
A modular pipeline for natural language processing-screened human abstraction of a pragmatic trial outcome from electronic health records.
Background: Natural language processing (NLP) allows efficient extraction of clinical variables and outcomes from electronic health records (EHR). However, measuring pragmatic clinical trial outcomes may demand accuracy that exceeds NLP performance. Combining NLP with human adjudication can address this gap, yet few software solutions support such workflows. We developed a modular, scalable system for NLP-screened human abstraction to measure the primary outcomes of two clinical trials.
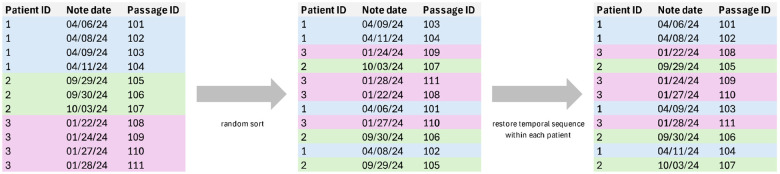
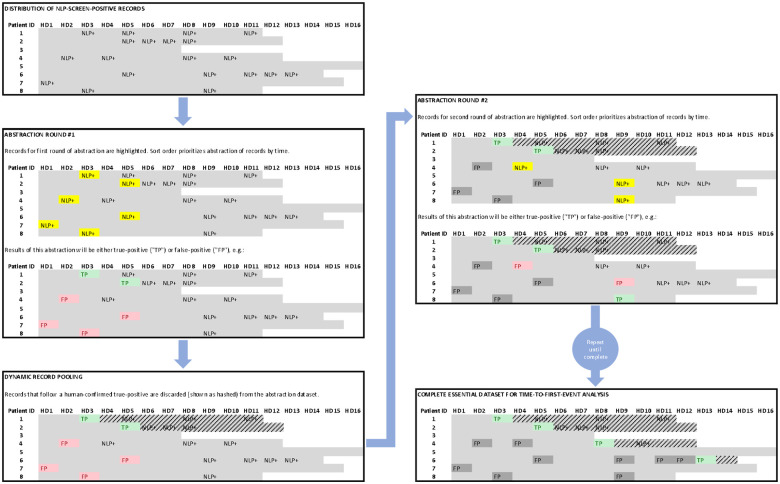
Methods: In two clinical trials of hospitalized patients with serious illness, a deep-learning NLP model screened EHR passages for documented goals-of-care discussions. Screen-positive passages were referred for human adjudication using a REDCap-based system to measure the trial outcomes. Dynamic pooling of passages using structured query language (SQL) within the REDCap database reduced unnecessary abstraction while ensuring data completeness.
Results: In the first trial (N=2,512), NLP identified 22,187 screen-positive passages (0.8%) from 2.6 million EHR passages. Human reviewers adjudicated 7,494 passages over 34.3 abstractor-hours to measure the cumulative incidence and time to first documented goals-of-care discussion for all patients with 92.6% patient-level sensitivity. In the second trial (N=617), NLP identified 8,952 screen-positive passages (1.6%) from 559,596 passages at a threshold with near-100% sensitivity. Human reviewers adjudicated 3,509 passages over 27.9 abstractor-hours to measure the same outcome for all patients.
Conclusion: We present the design and source code for a scalable and efficient pipeline for measuring complex EHR-derived outcomes using NLP-screened human abstraction. This implementation is adaptable to diverse research needs, and its modular pipeline represents a practical middle ground between custom software and commercial platforms.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


