Daniel M Tassone, Matthew M Hitchcock, Connor J Rossier, Douglas Fletcher, Julia Ye, Ian Langford, Julie Boatman, J Daniel Markley
{"title":"评估用于bccid2解释和管理的GPT聊天机器人中的思维链提示:人工智能与人类专家相比如何?","authors":"Daniel M Tassone, Matthew M Hitchcock, Connor J Rossier, Douglas Fletcher, Julia Ye, Ian Langford, Julie Boatman, J Daniel Markley","doi":"10.1017/ash.2025.10059","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Rapid molecular diagnostics, such as the BIOFIRE® Blood Culture Identification 2 (BCID2) panel, have improved the time to pathogen identification in bloodstream infections. However, accurate interpretation and antimicrobial optimization require Infectious Disease (ID) expertise, which may not always be readily available. GPT-powered chatbots could support antimicrobial stewardship programs (ASPs) by assisting non-specialist providers in BCID2 result interpretation and treatment recommendations. This study evaluates the performance of a GPT-4 chatbot compared to ASP prospective audit and feedback interventions.</p><p><strong>Methods: </strong>This prospective observational study assessed 43 consecutive real-world cases of bacteremia at a 399-bed VA Medical Center from January to May 2024. The GPT-chatbot utilized \"chain-of-thought\" prompting and external knowledge integration to generate recommendations. Two independent ID physicians evaluated chatbot and ASP recommendations across four domains: BCID2 interpretation, source control, antibiotic therapy, and additional diagnostic workup. The primary endpoint was the combined rate of harmful or inadequate recommendations. Secondary endpoints assessed the rate of harmful or inadequate responses for each domain.</p><p><strong>Results: </strong>The chatbot had a significantly higher rate of harmful or inadequate recommendations (13%) compared to ASP (4%, <i>p</i> = 0.047). The most significant discrepancy was observed in the domain of antibiotic therapy, where harmful recommendations occurred in up to 10% (<i>p</i> <0.05) of chatbot evaluations. The chatbot performed well in BCID2 interpretation (100% accuracy) but provided more inadequate responses in source control consideration (10% vs. 2% for ASP, <i>p</i> = 0.022).</p><p><strong>Conclusions: </strong>GPT-powered chatbots show potential for supporting antimicrobial stewardship but should only complement, not replace, human expertise in infectious disease management.</p>","PeriodicalId":72246,"journal":{"name":"Antimicrobial stewardship & healthcare epidemiology : ASHE","volume":"5 1","pages":"e154"},"PeriodicalIF":0.0000,"publicationDate":"2025-07-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12247004/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating chain-of-thought prompting in a GPT chatbot for BCID2 interpretation and stewardship: how does AI compare to human experts?\",\"authors\":\"Daniel M Tassone, Matthew M Hitchcock, Connor J Rossier, Douglas Fletcher, Julia Ye, Ian Langford, Julie Boatman, J Daniel Markley\",\"doi\":\"10.1017/ash.2025.10059\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Rapid molecular diagnostics, such as the BIOFIRE® Blood Culture Identification 2 (BCID2) panel, have improved the time to pathogen identification in bloodstream infections. However, accurate interpretation and antimicrobial optimization require Infectious Disease (ID) expertise, which may not always be readily available. GPT-powered chatbots could support antimicrobial stewardship programs (ASPs) by assisting non-specialist providers in BCID2 result interpretation and treatment recommendations. This study evaluates the performance of a GPT-4 chatbot compared to ASP prospective audit and feedback interventions.</p><p><strong>Methods: </strong>This prospective observational study assessed 43 consecutive real-world cases of bacteremia at a 399-bed VA Medical Center from January to May 2024. The GPT-chatbot utilized \\\"chain-of-thought\\\" prompting and external knowledge integration to generate recommendations. Two independent ID physicians evaluated chatbot and ASP recommendations across four domains: BCID2 interpretation, source control, antibiotic therapy, and additional diagnostic workup. The primary endpoint was the combined rate of harmful or inadequate recommendations. Secondary endpoints assessed the rate of harmful or inadequate responses for each domain.</p><p><strong>Results: </strong>The chatbot had a significantly higher rate of harmful or inadequate recommendations (13%) compared to ASP (4%, <i>p</i> = 0.047). The most significant discrepancy was observed in the domain of antibiotic therapy, where harmful recommendations occurred in up to 10% (<i>p</i> <0.05) of chatbot evaluations. The chatbot performed well in BCID2 interpretation (100% accuracy) but provided more inadequate responses in source control consideration (10% vs. 2% for ASP, <i>p</i> = 0.022).</p><p><strong>Conclusions: </strong>GPT-powered chatbots show potential for supporting antimicrobial stewardship but should only complement, not replace, human expertise in infectious disease management.</p>\",\"PeriodicalId\":72246,\"journal\":{\"name\":\"Antimicrobial stewardship & healthcare epidemiology : ASHE\",\"volume\":\"5 1\",\"pages\":\"e154\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-07-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12247004/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Antimicrobial stewardship & healthcare epidemiology : ASHE\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1017/ash.2025.10059\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Antimicrobial stewardship & healthcare epidemiology : ASHE","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1017/ash.2025.10059","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:快速分子诊断,如BIOFIRE®血培养鉴定2 (bid2)小组,已经缩短了血液感染中病原体鉴定的时间。然而,准确的解释和抗菌优化需要传染病(ID)专业知识,这可能并不总是现成的。基于gpt的聊天机器人可以通过协助非专业提供者进行bccid2结果解释和治疗建议来支持抗菌药物管理计划(asp)。本研究评估了GPT-4聊天机器人与ASP前瞻性审计和反馈干预的性能。方法:这项前瞻性观察性研究评估了2024年1月至5月在VA医疗中心399个床位的43例连续的现实世界菌血症病例。gpt聊天机器人利用“思维链”提示和外部知识整合来生成建议。两名独立的ID医生评估了聊天机器人和ASP在四个领域的建议:bccid2解释、来源控制、抗生素治疗和额外的诊断检查。主要终点是有害或不充分推荐的综合比率。次要终点评估了每个领域的有害或不充分反应的比率。结果:与ASP (4%, p = 0.047)相比,聊天机器人的有害或不充分推荐率(13%)明显更高。在抗生素治疗领域观察到最显著的差异,其中有害建议发生率高达10% (p p = 0.022)。结论:gpt驱动的聊天机器人显示出支持抗菌药物管理的潜力,但应该只是补充,而不是取代人类在传染病管理方面的专业知识。
Evaluating chain-of-thought prompting in a GPT chatbot for BCID2 interpretation and stewardship: how does AI compare to human experts?
Background: Rapid molecular diagnostics, such as the BIOFIRE® Blood Culture Identification 2 (BCID2) panel, have improved the time to pathogen identification in bloodstream infections. However, accurate interpretation and antimicrobial optimization require Infectious Disease (ID) expertise, which may not always be readily available. GPT-powered chatbots could support antimicrobial stewardship programs (ASPs) by assisting non-specialist providers in BCID2 result interpretation and treatment recommendations. This study evaluates the performance of a GPT-4 chatbot compared to ASP prospective audit and feedback interventions.
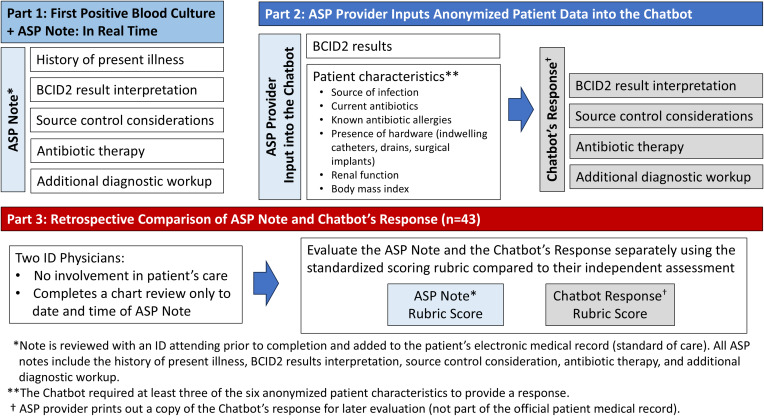
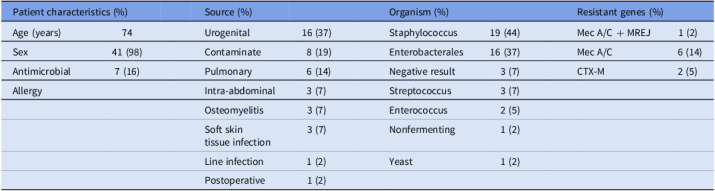
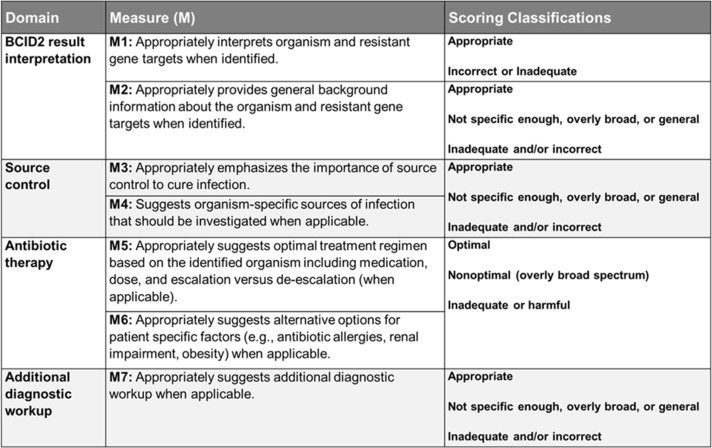
Methods: This prospective observational study assessed 43 consecutive real-world cases of bacteremia at a 399-bed VA Medical Center from January to May 2024. The GPT-chatbot utilized "chain-of-thought" prompting and external knowledge integration to generate recommendations. Two independent ID physicians evaluated chatbot and ASP recommendations across four domains: BCID2 interpretation, source control, antibiotic therapy, and additional diagnostic workup. The primary endpoint was the combined rate of harmful or inadequate recommendations. Secondary endpoints assessed the rate of harmful or inadequate responses for each domain.
Results: The chatbot had a significantly higher rate of harmful or inadequate recommendations (13%) compared to ASP (4%, p = 0.047). The most significant discrepancy was observed in the domain of antibiotic therapy, where harmful recommendations occurred in up to 10% (p <0.05) of chatbot evaluations. The chatbot performed well in BCID2 interpretation (100% accuracy) but provided more inadequate responses in source control consideration (10% vs. 2% for ASP, p = 0.022).
Conclusions: GPT-powered chatbots show potential for supporting antimicrobial stewardship but should only complement, not replace, human expertise in infectious disease management.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


