{"title":"植物图谱泛基因组学:技术、应用和挑战。","authors":"Ze-Zhen Du, Jia-Bao He, Wen-Biao Jiao","doi":"10.1007/s42994-025-00206-7","DOIUrl":null,"url":null,"abstract":"<div><p>Innovations in DNA sequencing technologies have greatly boosted population-level genomic studies in plants, facilitating the identification of key genetic variations for investigating population diversity and accelerating the molecular breeding of crops. Conventional methods for genomic analysis typically rely on small variants, such as SNPs and indels, and use single linear reference genomes, which introduces biases and reduces performance in highly divergent genomic regions. By integrating the population level of sequences, pangenomes, particularly graph pangenomes, offer a promising solution to these challenges. To date, numerous algorithms have been developed for constructing pangenome graphs, aligning reads to these graphs, and performing variant genotyping based on these graphs. As demonstrated in various plant pangenomic studies, these advancements allow for the detection of previously hidden variants, especially structural variants, thereby enhancing applications such as genetic mapping of agronomically important genes. However, noteworthy challenges remain to be overcome in applying pangenome graph approaches to plants. Addressing these issues will require the development of more sophisticated algorithms tailored specifically to plants. Such improvements will contribute to the scalability of this approach, facilitating the production of super-pangenomes, in which hundreds or even thousands of de novo–assembled genomes from one species or genus can be integrated. This, in turn, will promote broader pan-omic studies, further advancing our understanding of genetic diversity and driving innovations in crop breeding.</p></div>","PeriodicalId":53135,"journal":{"name":"aBIOTECH","volume":"6 2","pages":"361 - 376"},"PeriodicalIF":5.0000,"publicationDate":"2025-03-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12237840/pdf/","citationCount":"0","resultStr":"{\"title\":\"Plant graph-based pangenomics: techniques, applications, and challenges\",\"authors\":\"Ze-Zhen Du, Jia-Bao He, Wen-Biao Jiao\",\"doi\":\"10.1007/s42994-025-00206-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Innovations in DNA sequencing technologies have greatly boosted population-level genomic studies in plants, facilitating the identification of key genetic variations for investigating population diversity and accelerating the molecular breeding of crops. Conventional methods for genomic analysis typically rely on small variants, such as SNPs and indels, and use single linear reference genomes, which introduces biases and reduces performance in highly divergent genomic regions. By integrating the population level of sequences, pangenomes, particularly graph pangenomes, offer a promising solution to these challenges. To date, numerous algorithms have been developed for constructing pangenome graphs, aligning reads to these graphs, and performing variant genotyping based on these graphs. As demonstrated in various plant pangenomic studies, these advancements allow for the detection of previously hidden variants, especially structural variants, thereby enhancing applications such as genetic mapping of agronomically important genes. However, noteworthy challenges remain to be overcome in applying pangenome graph approaches to plants. Addressing these issues will require the development of more sophisticated algorithms tailored specifically to plants. Such improvements will contribute to the scalability of this approach, facilitating the production of super-pangenomes, in which hundreds or even thousands of de novo–assembled genomes from one species or genus can be integrated. This, in turn, will promote broader pan-omic studies, further advancing our understanding of genetic diversity and driving innovations in crop breeding.</p></div>\",\"PeriodicalId\":53135,\"journal\":{\"name\":\"aBIOTECH\",\"volume\":\"6 2\",\"pages\":\"361 - 376\"},\"PeriodicalIF\":5.0000,\"publicationDate\":\"2025-03-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12237840/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"aBIOTECH\",\"FirstCategoryId\":\"1091\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s42994-025-00206-7\",\"RegionNum\":4,\"RegionCategory\":\"农林科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOTECHNOLOGY & APPLIED MICROBIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"aBIOTECH","FirstCategoryId":"1091","ListUrlMain":"https://link.springer.com/article/10.1007/s42994-025-00206-7","RegionNum":4,"RegionCategory":"农林科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOTECHNOLOGY & APPLIED MICROBIOLOGY","Score":null,"Total":0}
Plant graph-based pangenomics: techniques, applications, and challenges
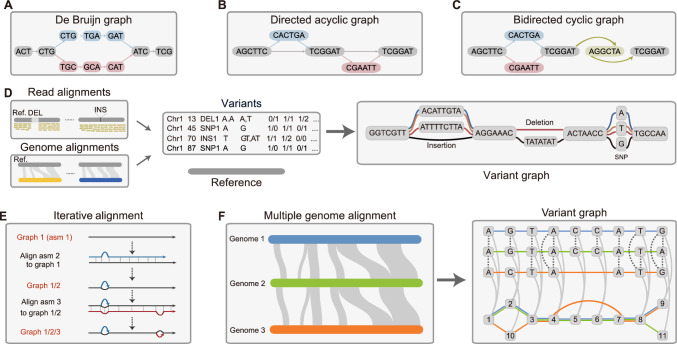
Innovations in DNA sequencing technologies have greatly boosted population-level genomic studies in plants, facilitating the identification of key genetic variations for investigating population diversity and accelerating the molecular breeding of crops. Conventional methods for genomic analysis typically rely on small variants, such as SNPs and indels, and use single linear reference genomes, which introduces biases and reduces performance in highly divergent genomic regions. By integrating the population level of sequences, pangenomes, particularly graph pangenomes, offer a promising solution to these challenges. To date, numerous algorithms have been developed for constructing pangenome graphs, aligning reads to these graphs, and performing variant genotyping based on these graphs. As demonstrated in various plant pangenomic studies, these advancements allow for the detection of previously hidden variants, especially structural variants, thereby enhancing applications such as genetic mapping of agronomically important genes. However, noteworthy challenges remain to be overcome in applying pangenome graph approaches to plants. Addressing these issues will require the development of more sophisticated algorithms tailored specifically to plants. Such improvements will contribute to the scalability of this approach, facilitating the production of super-pangenomes, in which hundreds or even thousands of de novo–assembled genomes from one species or genus can be integrated. This, in turn, will promote broader pan-omic studies, further advancing our understanding of genetic diversity and driving innovations in crop breeding.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


