{"title":"计算机辅助文本精炼中人机协作的半监督框架。","authors":"Yicheng Sun, Yi Wang, Hanbo Yang, Richard Suen","doi":"10.1038/s41598-025-10085-z","DOIUrl":null,"url":null,"abstract":"<p><p>Human writing often exhibits a range of styles and levels of sophistication. However, automated text generation systems typically lack the nuanced understanding required to produce refined and elegant prose. Due to the inherent one-to-many relationship between inputs and outputs in natural language generation tasks, achieving annotator consistency is challenging. This complexity makes the annotation process considerably more difficult compared to tasks focused on natural language understanding. Our study focuses on the typical task of text refinement, which faces annotation difficulties, aiming to generate sentences with more elegant expressions while preserving the original semantics of the input sentence. This paper proposes a semi-automatic data construction method that combines auto-generation with human judgment. Initially, this method translates collected sentences containing elegant expressions into ordinary expressions through back translation. Subsequently, in an iterative quality control process, data filtering and human judgment are introduced to screen the auto-generated data based on quality standards, resulting in a large-scale text refinement dataset. By replacing manual annotation with human judgment and involving only a small amount of data for human judgment in each iteration, this method significantly reduces annotation difficulty and workload. With minimal human effort, it acquires a substantial amount of labeled data for text refinement, laying a foundation for further research in the field.</p>","PeriodicalId":21811,"journal":{"name":"Scientific Reports","volume":"15 1","pages":"24312"},"PeriodicalIF":3.9000,"publicationDate":"2025-07-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12234744/pdf/","citationCount":"0","resultStr":"{\"title\":\"A semi supervised framework for human and machine collaboration in computer assisted text refinement.\",\"authors\":\"Yicheng Sun, Yi Wang, Hanbo Yang, Richard Suen\",\"doi\":\"10.1038/s41598-025-10085-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Human writing often exhibits a range of styles and levels of sophistication. However, automated text generation systems typically lack the nuanced understanding required to produce refined and elegant prose. Due to the inherent one-to-many relationship between inputs and outputs in natural language generation tasks, achieving annotator consistency is challenging. This complexity makes the annotation process considerably more difficult compared to tasks focused on natural language understanding. Our study focuses on the typical task of text refinement, which faces annotation difficulties, aiming to generate sentences with more elegant expressions while preserving the original semantics of the input sentence. This paper proposes a semi-automatic data construction method that combines auto-generation with human judgment. Initially, this method translates collected sentences containing elegant expressions into ordinary expressions through back translation. Subsequently, in an iterative quality control process, data filtering and human judgment are introduced to screen the auto-generated data based on quality standards, resulting in a large-scale text refinement dataset. By replacing manual annotation with human judgment and involving only a small amount of data for human judgment in each iteration, this method significantly reduces annotation difficulty and workload. With minimal human effort, it acquires a substantial amount of labeled data for text refinement, laying a foundation for further research in the field.</p>\",\"PeriodicalId\":21811,\"journal\":{\"name\":\"Scientific Reports\",\"volume\":\"15 1\",\"pages\":\"24312\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-07-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12234744/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Reports\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41598-025-10085-z\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Reports","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41598-025-10085-z","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
A semi supervised framework for human and machine collaboration in computer assisted text refinement.
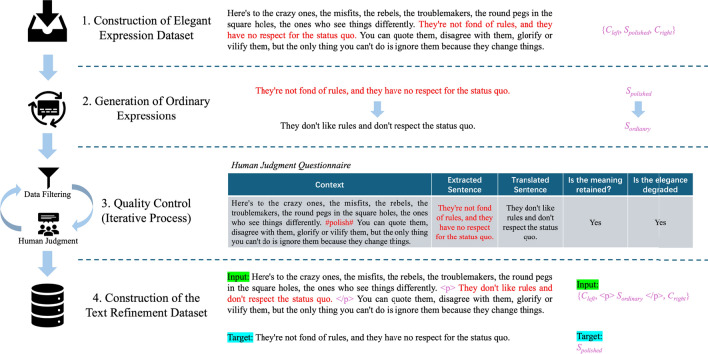
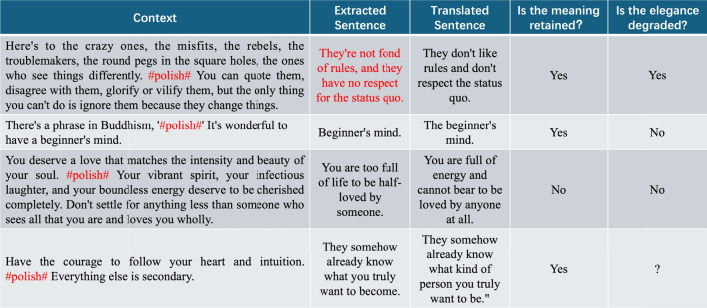
Human writing often exhibits a range of styles and levels of sophistication. However, automated text generation systems typically lack the nuanced understanding required to produce refined and elegant prose. Due to the inherent one-to-many relationship between inputs and outputs in natural language generation tasks, achieving annotator consistency is challenging. This complexity makes the annotation process considerably more difficult compared to tasks focused on natural language understanding. Our study focuses on the typical task of text refinement, which faces annotation difficulties, aiming to generate sentences with more elegant expressions while preserving the original semantics of the input sentence. This paper proposes a semi-automatic data construction method that combines auto-generation with human judgment. Initially, this method translates collected sentences containing elegant expressions into ordinary expressions through back translation. Subsequently, in an iterative quality control process, data filtering and human judgment are introduced to screen the auto-generated data based on quality standards, resulting in a large-scale text refinement dataset. By replacing manual annotation with human judgment and involving only a small amount of data for human judgment in each iteration, this method significantly reduces annotation difficulty and workload. With minimal human effort, it acquires a substantial amount of labeled data for text refinement, laying a foundation for further research in the field.
期刊介绍:
We publish original research from all areas of the natural sciences, psychology, medicine and engineering. You can learn more about what we publish by browsing our specific scientific subject areas below or explore Scientific Reports by browsing all articles and collections.
Scientific Reports has a 2-year impact factor: 4.380 (2021), and is the 6th most-cited journal in the world, with more than 540,000 citations in 2020 (Clarivate Analytics, 2021).
•Engineering
Engineering covers all aspects of engineering, technology, and applied science. It plays a crucial role in the development of technologies to address some of the world''s biggest challenges, helping to save lives and improve the way we live.
•Physical sciences
Physical sciences are those academic disciplines that aim to uncover the underlying laws of nature — often written in the language of mathematics. It is a collective term for areas of study including astronomy, chemistry, materials science and physics.
•Earth and environmental sciences
Earth and environmental sciences cover all aspects of Earth and planetary science and broadly encompass solid Earth processes, surface and atmospheric dynamics, Earth system history, climate and climate change, marine and freshwater systems, and ecology. It also considers the interactions between humans and these systems.
•Biological sciences
Biological sciences encompass all the divisions of natural sciences examining various aspects of vital processes. The concept includes anatomy, physiology, cell biology, biochemistry and biophysics, and covers all organisms from microorganisms, animals to plants.
•Health sciences
The health sciences study health, disease and healthcare. This field of study aims to develop knowledge, interventions and technology for use in healthcare to improve the treatment of patients.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


