Maziar Amini, Patrick W Chang, Rio O Davis, Denis D Nguyen, Jennifer L Dodge, Jennifer Phan, James Buxbaum, Ara Sahakian
{"title":"比较ChatGPT3.5和Bard结肠镜检查间隔的建议:弥合医疗保健环境中的差距。","authors":"Maziar Amini, Patrick W Chang, Rio O Davis, Denis D Nguyen, Jennifer L Dodge, Jennifer Phan, James Buxbaum, Ara Sahakian","doi":"10.1055/a-2586-5912","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and study aims: </strong>Colorectal cancer is a leading cause of cancer-related deaths, with screening and surveillance colonoscopy playing a crucial role in early detection. This study examined the efficacy of two freely available large language models (LLMs), GPT3.5 and Bard, in recommending colonoscopy intervals in diverse healthcare settings.</p><p><strong>Patients and methods: </strong>A cross-sectional study was conducted using data from routine colonoscopies at a large safety-net and a private tertiary hospital. GPT3.5 and Bard were tasked with recommending screening intervals based on colonoscopy reports and pathology data and their accuracy and inter-rater reliability were compared to a guideline-directed endoscopist panel.</p><p><strong>Results: </strong>Of 549 colonoscopies analyzed (N = 268 at safety-net and N = 281 private hospital), GPT3.5 showed better concordance with guideline recommendations (GPT3.5: 60.4% vs. Bard: 50.0%, <i>P</i> < 0.001). In the safety-net hospital, GPT3.5 had a 60.5% concordance rate with the panel compared with Bard's 45.7% ( <i>P</i> < 0.001). For the private hospital, concordance was 60.3% for GPT3.5 and 54.3% for Bard ( <i>P</i> = 0.13). GPT3.5 showed fair agreement with the panel (kappa = 0.324), whereas Bard displayed lower agreement (kappa = 0.219). For the safety-net hospital, GPT3.5 showed fair agreement with the panel (kappa = 0.340) whereas Bard showed slight agreement (kappa = 0.148). For the private hospital, both GPT3.5 and Bard demonstrated fair agreement with the panel (kappa = 0.295 and 0.282, respectively).</p><p><strong>Conclusions: </strong>This study highlights the limitations of freely available LLMs in assisting colonoscopy screening recommendations. Although the potential of freely available LLMs to offer uniformity is significant, the low accuracy, as noted, excludes their use as the sole agent in providing recommendations.</p>","PeriodicalId":11671,"journal":{"name":"Endoscopy International Open","volume":"13 ","pages":"a25865912"},"PeriodicalIF":2.3000,"publicationDate":"2025-06-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223955/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparing ChatGPT3.5 and Bard recommendations for colonoscopy intervals: Bridging the gap in healthcare settings.\",\"authors\":\"Maziar Amini, Patrick W Chang, Rio O Davis, Denis D Nguyen, Jennifer L Dodge, Jennifer Phan, James Buxbaum, Ara Sahakian\",\"doi\":\"10.1055/a-2586-5912\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background and study aims: </strong>Colorectal cancer is a leading cause of cancer-related deaths, with screening and surveillance colonoscopy playing a crucial role in early detection. This study examined the efficacy of two freely available large language models (LLMs), GPT3.5 and Bard, in recommending colonoscopy intervals in diverse healthcare settings.</p><p><strong>Patients and methods: </strong>A cross-sectional study was conducted using data from routine colonoscopies at a large safety-net and a private tertiary hospital. GPT3.5 and Bard were tasked with recommending screening intervals based on colonoscopy reports and pathology data and their accuracy and inter-rater reliability were compared to a guideline-directed endoscopist panel.</p><p><strong>Results: </strong>Of 549 colonoscopies analyzed (N = 268 at safety-net and N = 281 private hospital), GPT3.5 showed better concordance with guideline recommendations (GPT3.5: 60.4% vs. Bard: 50.0%, <i>P</i> < 0.001). In the safety-net hospital, GPT3.5 had a 60.5% concordance rate with the panel compared with Bard's 45.7% ( <i>P</i> < 0.001). For the private hospital, concordance was 60.3% for GPT3.5 and 54.3% for Bard ( <i>P</i> = 0.13). GPT3.5 showed fair agreement with the panel (kappa = 0.324), whereas Bard displayed lower agreement (kappa = 0.219). For the safety-net hospital, GPT3.5 showed fair agreement with the panel (kappa = 0.340) whereas Bard showed slight agreement (kappa = 0.148). For the private hospital, both GPT3.5 and Bard demonstrated fair agreement with the panel (kappa = 0.295 and 0.282, respectively).</p><p><strong>Conclusions: </strong>This study highlights the limitations of freely available LLMs in assisting colonoscopy screening recommendations. Although the potential of freely available LLMs to offer uniformity is significant, the low accuracy, as noted, excludes their use as the sole agent in providing recommendations.</p>\",\"PeriodicalId\":11671,\"journal\":{\"name\":\"Endoscopy International Open\",\"volume\":\"13 \",\"pages\":\"a25865912\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2025-06-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223955/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Endoscopy International Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1055/a-2586-5912\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"GASTROENTEROLOGY & HEPATOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Endoscopy International Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1055/a-2586-5912","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"GASTROENTEROLOGY & HEPATOLOGY","Score":null,"Total":0}
Comparing ChatGPT3.5 and Bard recommendations for colonoscopy intervals: Bridging the gap in healthcare settings.
Background and study aims: Colorectal cancer is a leading cause of cancer-related deaths, with screening and surveillance colonoscopy playing a crucial role in early detection. This study examined the efficacy of two freely available large language models (LLMs), GPT3.5 and Bard, in recommending colonoscopy intervals in diverse healthcare settings.
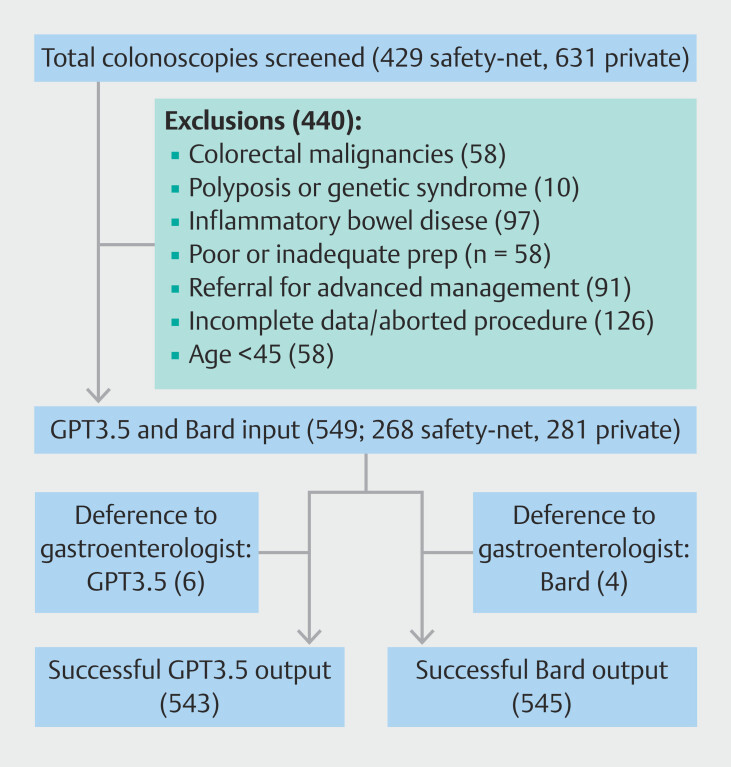
Patients and methods: A cross-sectional study was conducted using data from routine colonoscopies at a large safety-net and a private tertiary hospital. GPT3.5 and Bard were tasked with recommending screening intervals based on colonoscopy reports and pathology data and their accuracy and inter-rater reliability were compared to a guideline-directed endoscopist panel.
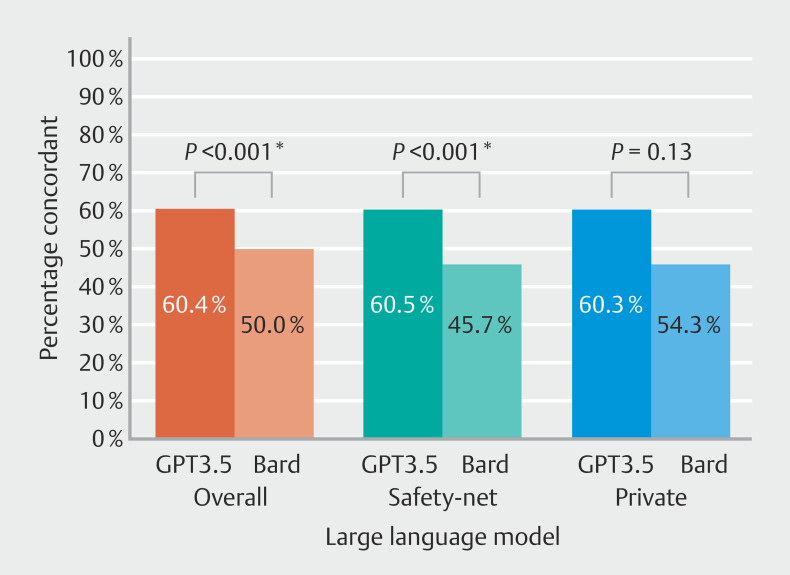
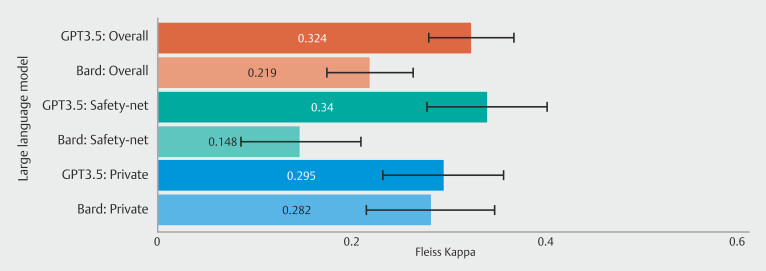
Results: Of 549 colonoscopies analyzed (N = 268 at safety-net and N = 281 private hospital), GPT3.5 showed better concordance with guideline recommendations (GPT3.5: 60.4% vs. Bard: 50.0%, P < 0.001). In the safety-net hospital, GPT3.5 had a 60.5% concordance rate with the panel compared with Bard's 45.7% ( P < 0.001). For the private hospital, concordance was 60.3% for GPT3.5 and 54.3% for Bard ( P = 0.13). GPT3.5 showed fair agreement with the panel (kappa = 0.324), whereas Bard displayed lower agreement (kappa = 0.219). For the safety-net hospital, GPT3.5 showed fair agreement with the panel (kappa = 0.340) whereas Bard showed slight agreement (kappa = 0.148). For the private hospital, both GPT3.5 and Bard demonstrated fair agreement with the panel (kappa = 0.295 and 0.282, respectively).
Conclusions: This study highlights the limitations of freely available LLMs in assisting colonoscopy screening recommendations. Although the potential of freely available LLMs to offer uniformity is significant, the low accuracy, as noted, excludes their use as the sole agent in providing recommendations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


