{"title":"语义语言流畅性测试自动聚类分析的日文LDA模型。","authors":"Masahiro Yoshihara, Yoshihiro Itaguchi","doi":"10.3758/s13428-025-02696-1","DOIUrl":null,"url":null,"abstract":"<p><p>In the semantic variant of verbal fluency tests (VFTs), clustering analysis has become popular for examining the semantic structure. While the computational psycholinguistics approach has recently drawn attention to increasing the reproducibility of clustering analysis, such an approach is not available in all languages. To make the computational approach available in the Japanese language, we constructed a Japanese latent Dirichlet allocation (LDA) model. Our LDA model enables researchers and clinicians to objectively quantify the associative relationships of words, thereby making it possible to automatically detect semantic clusters. We conducted the semantic VFT with healthy young Japanese adults to examine the validity of our LDA model. We performed clustering analyses using the computational approach with our LDA model and the conventional manual approach with human coders. The results showed that the LDA model identified semantic clusters, as did the human coders. In addition, we demonstrated for the first time that response intervals within a cluster were significantly shorter than those outside of clusters, regardless of the clustering approaches. This indicates that both approaches reflect a broadly accepted assumption that closer semantic relations require less processing time. However, LDA-based clustering produced, on average, larger clusters than human-based clustering did, indicating that the LDA model captured semantic relationships between words that human coders would not recognize. Taken together, the present results demonstrated the validity of our LDA model. We hope that our LDA model fosters the use of the computational linguistic approach in semantic VFTs with Japanese participants.</p>","PeriodicalId":8717,"journal":{"name":"Behavior Research Methods","volume":"57 8","pages":"209"},"PeriodicalIF":3.9000,"publicationDate":"2025-06-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12209035/pdf/","citationCount":"0","resultStr":"{\"title\":\"A Japanese LDA model for automatic clustering analysis of semantic verbal fluency tests.\",\"authors\":\"Masahiro Yoshihara, Yoshihiro Itaguchi\",\"doi\":\"10.3758/s13428-025-02696-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In the semantic variant of verbal fluency tests (VFTs), clustering analysis has become popular for examining the semantic structure. While the computational psycholinguistics approach has recently drawn attention to increasing the reproducibility of clustering analysis, such an approach is not available in all languages. To make the computational approach available in the Japanese language, we constructed a Japanese latent Dirichlet allocation (LDA) model. Our LDA model enables researchers and clinicians to objectively quantify the associative relationships of words, thereby making it possible to automatically detect semantic clusters. We conducted the semantic VFT with healthy young Japanese adults to examine the validity of our LDA model. We performed clustering analyses using the computational approach with our LDA model and the conventional manual approach with human coders. The results showed that the LDA model identified semantic clusters, as did the human coders. In addition, we demonstrated for the first time that response intervals within a cluster were significantly shorter than those outside of clusters, regardless of the clustering approaches. This indicates that both approaches reflect a broadly accepted assumption that closer semantic relations require less processing time. However, LDA-based clustering produced, on average, larger clusters than human-based clustering did, indicating that the LDA model captured semantic relationships between words that human coders would not recognize. Taken together, the present results demonstrated the validity of our LDA model. We hope that our LDA model fosters the use of the computational linguistic approach in semantic VFTs with Japanese participants.</p>\",\"PeriodicalId\":8717,\"journal\":{\"name\":\"Behavior Research Methods\",\"volume\":\"57 8\",\"pages\":\"209\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-06-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12209035/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Behavior Research Methods\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.3758/s13428-025-02696-1\",\"RegionNum\":2,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHOLOGY, EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Behavior Research Methods","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.3758/s13428-025-02696-1","RegionNum":2,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PSYCHOLOGY, EXPERIMENTAL","Score":null,"Total":0}
A Japanese LDA model for automatic clustering analysis of semantic verbal fluency tests.
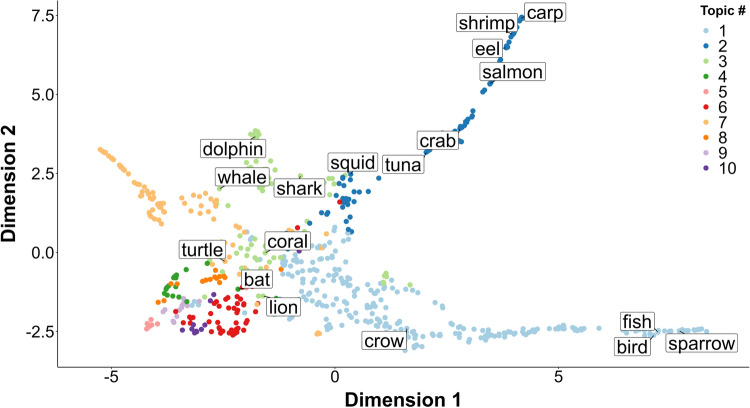
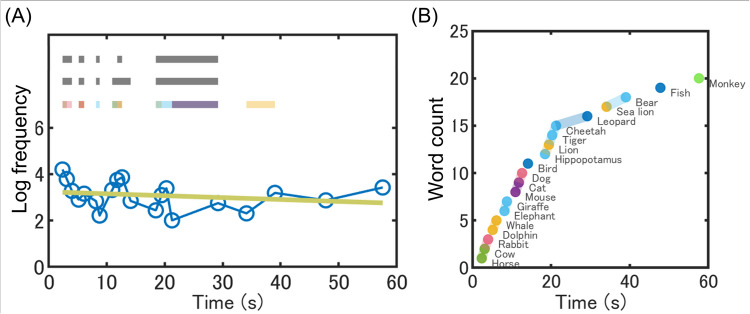
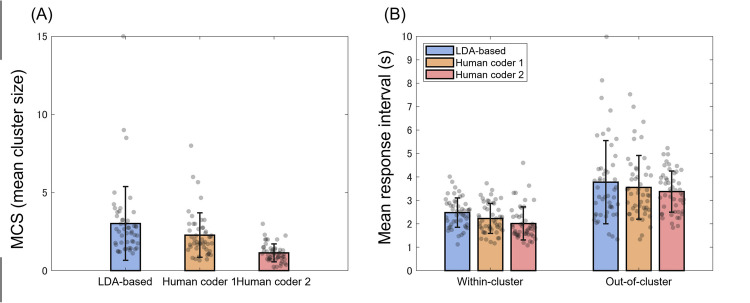
In the semantic variant of verbal fluency tests (VFTs), clustering analysis has become popular for examining the semantic structure. While the computational psycholinguistics approach has recently drawn attention to increasing the reproducibility of clustering analysis, such an approach is not available in all languages. To make the computational approach available in the Japanese language, we constructed a Japanese latent Dirichlet allocation (LDA) model. Our LDA model enables researchers and clinicians to objectively quantify the associative relationships of words, thereby making it possible to automatically detect semantic clusters. We conducted the semantic VFT with healthy young Japanese adults to examine the validity of our LDA model. We performed clustering analyses using the computational approach with our LDA model and the conventional manual approach with human coders. The results showed that the LDA model identified semantic clusters, as did the human coders. In addition, we demonstrated for the first time that response intervals within a cluster were significantly shorter than those outside of clusters, regardless of the clustering approaches. This indicates that both approaches reflect a broadly accepted assumption that closer semantic relations require less processing time. However, LDA-based clustering produced, on average, larger clusters than human-based clustering did, indicating that the LDA model captured semantic relationships between words that human coders would not recognize. Taken together, the present results demonstrated the validity of our LDA model. We hope that our LDA model fosters the use of the computational linguistic approach in semantic VFTs with Japanese participants.
期刊介绍:
Behavior Research Methods publishes articles concerned with the methods, techniques, and instrumentation of research in experimental psychology. The journal focuses particularly on the use of computer technology in psychological research. An annual special issue is devoted to this field.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


