演化数据流的短时记忆聚类算法
IF 6.6
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
数据流聚类是许多流数据分析应用中的一个基本问题,它面临着以下关键挑战:(a)有效地利用初始结果来更新聚类;(b)在处理非平稳数据时有效管理概念漂移,这会导致聚类精度随时间下降。为了解决这些限制,本文提出了一种新的针对不断发展的数据流的短期记忆聚类算法,称为STM-Stream。短时记忆是指将细胞群的细胞核和半径存储在窗口滑动时,通过三个关键步骤实现流式数据聚类:首先,使用细胞分裂法获得初始数据分布。然后,采用一种新的动态投影策略将存储的数据分布与新到达的数据分布融合在一起。最后,基于更新后的内存,设计了一种自适应分组半径分组和合并方法,得到最终的聚类结果。针对聚类过程中经常出现的概念漂移问题,分析和讨论了四种类型的概念漂移(突发性、渐进性、渐进式和重复发生)的内部过程。本文进一步提取了两种主要的变化过程:逐渐漂移和突然漂移来描述数据迁移过程。通过动态投影和自适应群半径方法,该算法可以在概念漂移发生时自动纠正其突然或逐渐变化的记忆,对增量和发生的概念漂移同样有效。实验表明,STM-Stream可以有效地解决连续生成的流数据中经常发生的概念漂移,从而防止聚类精度随时间下降。本文章由计算机程序翻译,如有差异,请以英文原文为准。
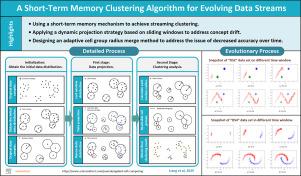
A short-term memory clustering algorithm for evolving data streams
Data stream clustering is a fundamental problem in many streaming data analysis applications, which faces the following key challenges: (a) efficiently utilizing initial results to update clusters; (b) effectively managing concept drift when dealing with non-stationary data, which leads to decreased clustering accuracy over time. To address these limitations, this paper presents a new short-term memory clustering algorithm for evolving data streams, called STM-Stream. Short-term memory refers to storing the nucleus and radius of cell groups as the window slides, enabling streaming data clustering through three key steps: Firstly, the cell split method is used to obtain the initial data distribution. Then, a novel dynamic projection strategy is used to fuse the stored data distribution with newly arriving data distributions. Finally, based on the updated memory, an adaptive group radius grouping and merging method is designed to produce the final clustering result. Regarding the frequently occurring concept drift issue during clustering, the internal processes of four types of concept drift (Sudden, Gradual, Incremental, and Reoccurring) are analyzed and discussed. The article further extracted two main change processes: Gradual and Sudden drift to characterize the data migration process. Through dynamic projection and adaptive group radius methods, the algorithm can automatically correct its memory with sudden or gradual changes when concept drift occurs, which is equally effective for incremental and occurring concept drift. The experiment demonstrated that STM-Stream can effectively address concept drift, which frequently occurs in continuously generated streaming data, thereby preventing a decline in clustering accuracy over time.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Applied Soft Computing
工程技术-计算机:跨学科应用
CiteScore
15.80
自引率
6.90%
发文量
874
审稿时长
10.9 months
期刊介绍:
Applied Soft Computing is an international journal promoting an integrated view of soft computing to solve real life problems.The focus is to publish the highest quality research in application and convergence of the areas of Fuzzy Logic, Neural Networks, Evolutionary Computing, Rough Sets and other similar techniques to address real world complexities.
Applied Soft Computing is a rolling publication: articles are published as soon as the editor-in-chief has accepted them. Therefore, the web site will continuously be updated with new articles and the publication time will be short.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


