{"title":"使用混合变压器模型高效准确地识别美国手语手势。","authors":"Mohammed Aly, Islam S Fathi","doi":"10.1038/s41598-025-06344-8","DOIUrl":null,"url":null,"abstract":"<p><p>Gesture recognition plays a vital role in computer vision, especially for interpreting sign language and enabling human-computer interaction. Many existing methods struggle with challenges like heavy computational demands, difficulty in understanding long-range relationships, sensitivity to background noise, and poor performance in varied environments. While CNNs excel at capturing local details, they often miss the bigger picture. Vision Transformers, on the other hand, are better at modeling global context but usually require significantly more computational resources, limiting their use in real-time systems. To tackle these issues, we propose a Hybrid Transformer-CNN model that combines the strengths of both architectures. Our approach begins with CNN layers that extract detailed local features from both the overall hand and specific hand regions. These CNN features are then refined by a Vision Transformer module, which captures long-range dependencies and global contextual information within the gesture. This integration allows the model to effectively recognize subtle hand movements while maintaining computational efficiency. Tested on the ASL Alphabet dataset, our model achieves a high accuracy of 99.97%, runs at 110 frames per second, and requires only 5.0 GFLOPs-much less than traditional Vision Transformer models, which need over twice the computational power. Central to this success is our feature fusion strategy using element-wise multiplication, which helps the model focus on important gesture details while suppressing background noise. Additionally, we employ advanced data augmentation techniques and a training approach incorporating contrastive learning and domain adaptation to boost robustness. Overall, this work offers a practical and powerful solution for gesture recognition, striking an optimal balance between accuracy, speed, and efficiency-an important step toward real-world applications.</p>","PeriodicalId":21811,"journal":{"name":"Scientific Reports","volume":"15 1","pages":"20253"},"PeriodicalIF":3.9000,"publicationDate":"2025-06-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12185765/pdf/","citationCount":"0","resultStr":"{\"title\":\"Recognizing American Sign Language gestures efficiently and accurately using a hybrid transformer model.\",\"authors\":\"Mohammed Aly, Islam S Fathi\",\"doi\":\"10.1038/s41598-025-06344-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Gesture recognition plays a vital role in computer vision, especially for interpreting sign language and enabling human-computer interaction. Many existing methods struggle with challenges like heavy computational demands, difficulty in understanding long-range relationships, sensitivity to background noise, and poor performance in varied environments. While CNNs excel at capturing local details, they often miss the bigger picture. Vision Transformers, on the other hand, are better at modeling global context but usually require significantly more computational resources, limiting their use in real-time systems. To tackle these issues, we propose a Hybrid Transformer-CNN model that combines the strengths of both architectures. Our approach begins with CNN layers that extract detailed local features from both the overall hand and specific hand regions. These CNN features are then refined by a Vision Transformer module, which captures long-range dependencies and global contextual information within the gesture. This integration allows the model to effectively recognize subtle hand movements while maintaining computational efficiency. Tested on the ASL Alphabet dataset, our model achieves a high accuracy of 99.97%, runs at 110 frames per second, and requires only 5.0 GFLOPs-much less than traditional Vision Transformer models, which need over twice the computational power. Central to this success is our feature fusion strategy using element-wise multiplication, which helps the model focus on important gesture details while suppressing background noise. Additionally, we employ advanced data augmentation techniques and a training approach incorporating contrastive learning and domain adaptation to boost robustness. Overall, this work offers a practical and powerful solution for gesture recognition, striking an optimal balance between accuracy, speed, and efficiency-an important step toward real-world applications.</p>\",\"PeriodicalId\":21811,\"journal\":{\"name\":\"Scientific Reports\",\"volume\":\"15 1\",\"pages\":\"20253\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-06-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12185765/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Reports\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41598-025-06344-8\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Reports","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41598-025-06344-8","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Recognizing American Sign Language gestures efficiently and accurately using a hybrid transformer model.
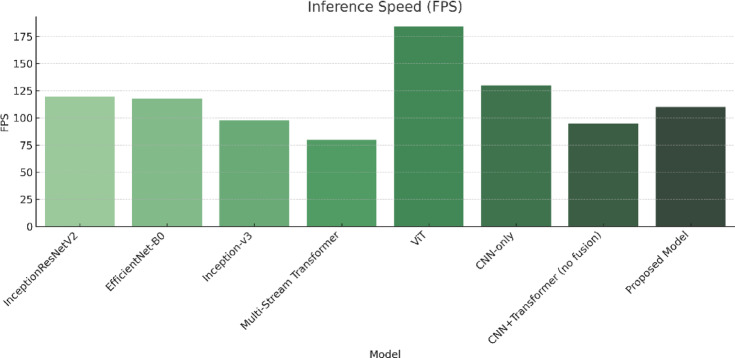
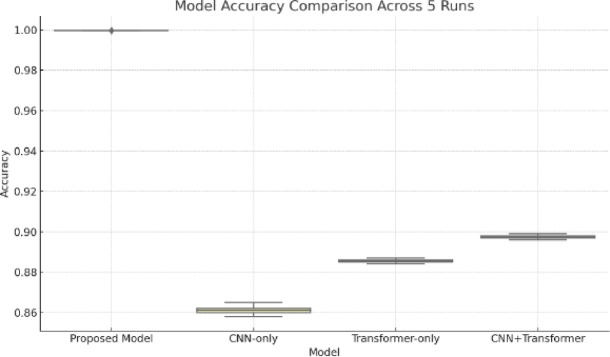
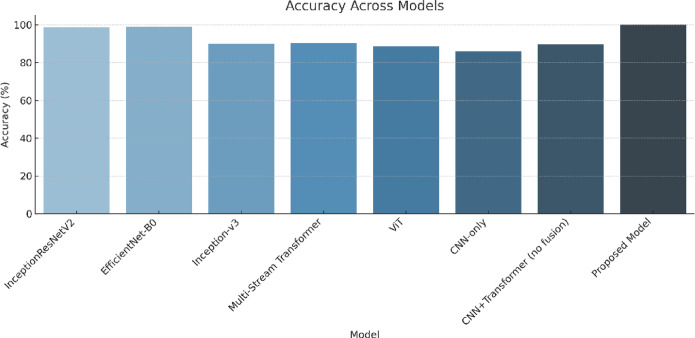
Gesture recognition plays a vital role in computer vision, especially for interpreting sign language and enabling human-computer interaction. Many existing methods struggle with challenges like heavy computational demands, difficulty in understanding long-range relationships, sensitivity to background noise, and poor performance in varied environments. While CNNs excel at capturing local details, they often miss the bigger picture. Vision Transformers, on the other hand, are better at modeling global context but usually require significantly more computational resources, limiting their use in real-time systems. To tackle these issues, we propose a Hybrid Transformer-CNN model that combines the strengths of both architectures. Our approach begins with CNN layers that extract detailed local features from both the overall hand and specific hand regions. These CNN features are then refined by a Vision Transformer module, which captures long-range dependencies and global contextual information within the gesture. This integration allows the model to effectively recognize subtle hand movements while maintaining computational efficiency. Tested on the ASL Alphabet dataset, our model achieves a high accuracy of 99.97%, runs at 110 frames per second, and requires only 5.0 GFLOPs-much less than traditional Vision Transformer models, which need over twice the computational power. Central to this success is our feature fusion strategy using element-wise multiplication, which helps the model focus on important gesture details while suppressing background noise. Additionally, we employ advanced data augmentation techniques and a training approach incorporating contrastive learning and domain adaptation to boost robustness. Overall, this work offers a practical and powerful solution for gesture recognition, striking an optimal balance between accuracy, speed, and efficiency-an important step toward real-world applications.
期刊介绍:
We publish original research from all areas of the natural sciences, psychology, medicine and engineering. You can learn more about what we publish by browsing our specific scientific subject areas below or explore Scientific Reports by browsing all articles and collections.
Scientific Reports has a 2-year impact factor: 4.380 (2021), and is the 6th most-cited journal in the world, with more than 540,000 citations in 2020 (Clarivate Analytics, 2021).
•Engineering
Engineering covers all aspects of engineering, technology, and applied science. It plays a crucial role in the development of technologies to address some of the world''s biggest challenges, helping to save lives and improve the way we live.
•Physical sciences
Physical sciences are those academic disciplines that aim to uncover the underlying laws of nature — often written in the language of mathematics. It is a collective term for areas of study including astronomy, chemistry, materials science and physics.
•Earth and environmental sciences
Earth and environmental sciences cover all aspects of Earth and planetary science and broadly encompass solid Earth processes, surface and atmospheric dynamics, Earth system history, climate and climate change, marine and freshwater systems, and ecology. It also considers the interactions between humans and these systems.
•Biological sciences
Biological sciences encompass all the divisions of natural sciences examining various aspects of vital processes. The concept includes anatomy, physiology, cell biology, biochemistry and biophysics, and covers all organisms from microorganisms, animals to plants.
•Health sciences
The health sciences study health, disease and healthcare. This field of study aims to develop knowledge, interventions and technology for use in healthcare to improve the treatment of patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


