Ehtesham Hashmi, Amna Altaf, Muhammad Waqas Anwar, Muhammad Hasan Jamal, Usama Ijaz Bajwa
{"title":"BI-SENT:基于双语方面的乌尔都语COVID-19推文情感分析。","authors":"Ehtesham Hashmi, Amna Altaf, Muhammad Waqas Anwar, Muhammad Hasan Jamal, Usama Ijaz Bajwa","doi":"10.1371/journal.pone.0317562","DOIUrl":null,"url":null,"abstract":"<p><p>The COVID-19 pandemic resulted in over 600 million cases worldwide, and significantly impacted both physical and mental health, fostering widespread anxiety and fear. Consequently, the extensive use of online social networks to express emotions made sentiment analysis a crucial tool for understanding public sentiment. Traditionally, sentiment analysis in the Urdu language has focused on sentence-level analysis. However, aspect-level sentiment analysis is increasingly important and remains underexplored due to the challenges of the costly and time-consuming manual dataset annotation process. This study presents an innovative bilingual aspect-based sentiment analysis for Urdu and Roman Urdu using unsupervised methods. For Urdu, a syntactic rule-based approach achieves an accuracy of 83% in extracting aspect terms, marking a 5% improvement in F1-score over existing methods. For Roman Urdu, the study employs collocation patterns and topic modeling to identify and categorize key aspects, resulting in a perplexity score of -7 and a coherence score of 41. The results not only demonstrate the semantic coherence of the identified categories but also represent a significant advancement in aspect-level sentiment analysis by eliminating the need for manual annotation. This study offers new insights into the sentiments expressed during the pandemic, providing valuable feedback for policymakers and health organizations.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"20 6","pages":"e0317562"},"PeriodicalIF":2.6000,"publicationDate":"2025-06-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12165425/pdf/","citationCount":"0","resultStr":"{\"title\":\"BI-SENT: bilingual aspect-based sentiment analysis of COVID-19 Tweets in Urdu language.\",\"authors\":\"Ehtesham Hashmi, Amna Altaf, Muhammad Waqas Anwar, Muhammad Hasan Jamal, Usama Ijaz Bajwa\",\"doi\":\"10.1371/journal.pone.0317562\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The COVID-19 pandemic resulted in over 600 million cases worldwide, and significantly impacted both physical and mental health, fostering widespread anxiety and fear. Consequently, the extensive use of online social networks to express emotions made sentiment analysis a crucial tool for understanding public sentiment. Traditionally, sentiment analysis in the Urdu language has focused on sentence-level analysis. However, aspect-level sentiment analysis is increasingly important and remains underexplored due to the challenges of the costly and time-consuming manual dataset annotation process. This study presents an innovative bilingual aspect-based sentiment analysis for Urdu and Roman Urdu using unsupervised methods. For Urdu, a syntactic rule-based approach achieves an accuracy of 83% in extracting aspect terms, marking a 5% improvement in F1-score over existing methods. For Roman Urdu, the study employs collocation patterns and topic modeling to identify and categorize key aspects, resulting in a perplexity score of -7 and a coherence score of 41. The results not only demonstrate the semantic coherence of the identified categories but also represent a significant advancement in aspect-level sentiment analysis by eliminating the need for manual annotation. This study offers new insights into the sentiments expressed during the pandemic, providing valuable feedback for policymakers and health organizations.</p>\",\"PeriodicalId\":20189,\"journal\":{\"name\":\"PLoS ONE\",\"volume\":\"20 6\",\"pages\":\"e0317562\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2025-06-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12165425/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLoS ONE\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pone.0317562\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0317562","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
BI-SENT: bilingual aspect-based sentiment analysis of COVID-19 Tweets in Urdu language.
The COVID-19 pandemic resulted in over 600 million cases worldwide, and significantly impacted both physical and mental health, fostering widespread anxiety and fear. Consequently, the extensive use of online social networks to express emotions made sentiment analysis a crucial tool for understanding public sentiment. Traditionally, sentiment analysis in the Urdu language has focused on sentence-level analysis. However, aspect-level sentiment analysis is increasingly important and remains underexplored due to the challenges of the costly and time-consuming manual dataset annotation process. This study presents an innovative bilingual aspect-based sentiment analysis for Urdu and Roman Urdu using unsupervised methods. For Urdu, a syntactic rule-based approach achieves an accuracy of 83% in extracting aspect terms, marking a 5% improvement in F1-score over existing methods. For Roman Urdu, the study employs collocation patterns and topic modeling to identify and categorize key aspects, resulting in a perplexity score of -7 and a coherence score of 41. The results not only demonstrate the semantic coherence of the identified categories but also represent a significant advancement in aspect-level sentiment analysis by eliminating the need for manual annotation. This study offers new insights into the sentiments expressed during the pandemic, providing valuable feedback for policymakers and health organizations.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage
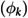

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


