Split-net:双变压器编码器,可拆分场景文本图像,用于脚本识别
IF 3.3
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
脚本识别对于理解场景和视频图像至关重要。由于物理外观、字体设计、复杂的背景、扭曲和不同脚本特征的显著重叠,这是具有挑战性的。现有的模型旨在利用场景文本图像作为一个整体来处理脚本图像,与此不同,我们建议将图像分为上下两部分,以捕捉各种脚本在笔画和风格上的复杂差异。在此基础上,研究了一种改进的脚本风格感知移动视觉转换器(M-ViT),用于对图像的视觉特征进行编码。为了丰富变压器块的特征,将一种新型边缘增强风格感知通道注意模块(EESA-CAM)集成到M-ViT中。此外,该模型利用编码器的梯度信息作为权重,采用动态加权平均方法融合双编码器的特征(从图像的上半部分和下半部分提取特征)。在MLe2e、CVSI2015和SIW-13三个标准数据集上的实验中,与最先进的模型相比,所提出的模型产生了更好的性能。本文章由计算机程序翻译,如有差异,请以英文原文为准。
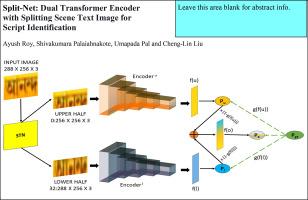
Split-net: Dual transformer encoder with splitting scene text image for script identification
Script identification is vital for understanding scenes and video images. It is challenging due to high variations in physical appearance, typeface design, complex background, distortion, and significant overlap in the characteristics of different scripts. Unlike existing models, which aim to tackle the script images utilizing the scene text image as a whole, we propose to split the image into upper and lower halves to capture the intricate differences in stroke and style of various scripts. Motivated by the accomplishments of the transformer, a modified script-style-aware Mobile-Vision Transformer (M-ViT) is explored for encoding visual features of the images. To enrich the features of the transformer blocks, a novel Edge Enhanced Style Aware Channel Attention Module (EESA-CAM) has been integrated with M-ViT. Furthermore, the model fuses the features of the dual encoders (extracting features from the upper and the lower half of the images) by a dynamic weighted average procedure utilizing the gradient information of the encoders as the weights. In experiments on three standard datasets, MLe2e, CVSI2015, and SIW-13, the proposed model yielded superior performance compared to state-of-the-art models.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Pattern Recognition Letters
工程技术-计算机:人工智能
CiteScore
12.40
自引率
5.90%
发文量
287
审稿时长
9.1 months
期刊介绍:
Pattern Recognition Letters aims at rapid publication of concise articles of a broad interest in pattern recognition.
Subject areas include all the current fields of interest represented by the Technical Committees of the International Association of Pattern Recognition, and other developing themes involving learning and recognition.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


