Danilo Dessí, Francesco Osborne, Davide Buscaldi, Diego Reforgiato Recupero, Enrico Motta
{"title":"CS-KG 2.0:计算机科学的大规模知识图谱。","authors":"Danilo Dessí, Francesco Osborne, Davide Buscaldi, Diego Reforgiato Recupero, Enrico Motta","doi":"10.1038/s41597-025-05200-8","DOIUrl":null,"url":null,"abstract":"<p><p>The rapid evolution of AI and the increased accessibility of scientific articles through open access marks a pivotal moment in research. AI-driven tools are reshaping how scientists explore, interpret, and contribute to the body of scientific knowledge, offering unprecedented opportunities. Nonetheless, a significant challenge remains: dealing with the overwhelming number of papers published every year. A promising solution is the use of knowledge graphs, which provide structured, interconnected, and formalized frameworks that improve the capabilities of AI systems to integrate information from the literature. This paper presents the last version of the Computer Science Knowledge Graph (CS-KG 2.0), an extensive knowledge base generated from 15 million research papers. CS-KG 2.0 describes 25 million entities linked by 67 million relationships, offering a nuanced representation of the scientific knowledge within the field of computer science. This innovative resource facilitates new research opportunities in key areas such as analysis and forecasting of research trends, hypothesis generation, smart literature search, automatic production of literature review, and scientific question-answering.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"12 1","pages":"964"},"PeriodicalIF":6.9000,"publicationDate":"2025-06-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12149285/pdf/","citationCount":"0","resultStr":"{\"title\":\"CS-KG 2.0: A Large-scale Knowledge Graph of Computer Science.\",\"authors\":\"Danilo Dessí, Francesco Osborne, Davide Buscaldi, Diego Reforgiato Recupero, Enrico Motta\",\"doi\":\"10.1038/s41597-025-05200-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The rapid evolution of AI and the increased accessibility of scientific articles through open access marks a pivotal moment in research. AI-driven tools are reshaping how scientists explore, interpret, and contribute to the body of scientific knowledge, offering unprecedented opportunities. Nonetheless, a significant challenge remains: dealing with the overwhelming number of papers published every year. A promising solution is the use of knowledge graphs, which provide structured, interconnected, and formalized frameworks that improve the capabilities of AI systems to integrate information from the literature. This paper presents the last version of the Computer Science Knowledge Graph (CS-KG 2.0), an extensive knowledge base generated from 15 million research papers. CS-KG 2.0 describes 25 million entities linked by 67 million relationships, offering a nuanced representation of the scientific knowledge within the field of computer science. This innovative resource facilitates new research opportunities in key areas such as analysis and forecasting of research trends, hypothesis generation, smart literature search, automatic production of literature review, and scientific question-answering.</p>\",\"PeriodicalId\":21597,\"journal\":{\"name\":\"Scientific Data\",\"volume\":\"12 1\",\"pages\":\"964\"},\"PeriodicalIF\":6.9000,\"publicationDate\":\"2025-06-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12149285/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Data\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41597-025-05200-8\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-025-05200-8","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
CS-KG 2.0: A Large-scale Knowledge Graph of Computer Science.
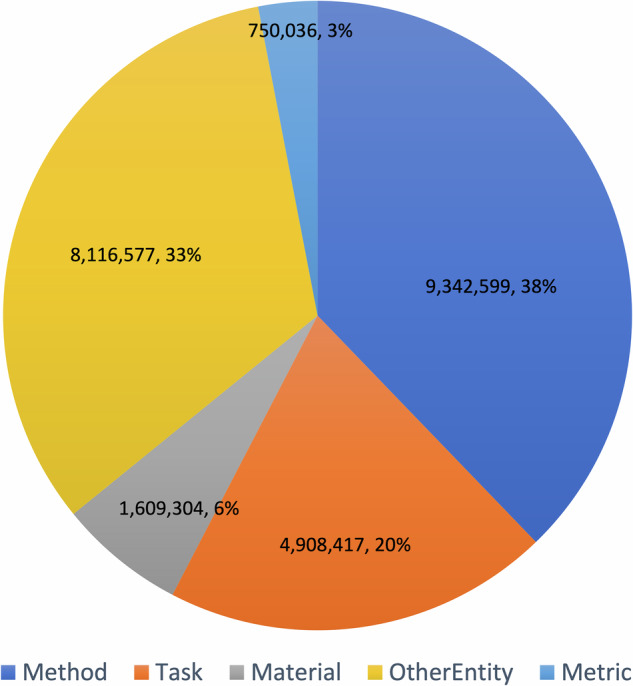
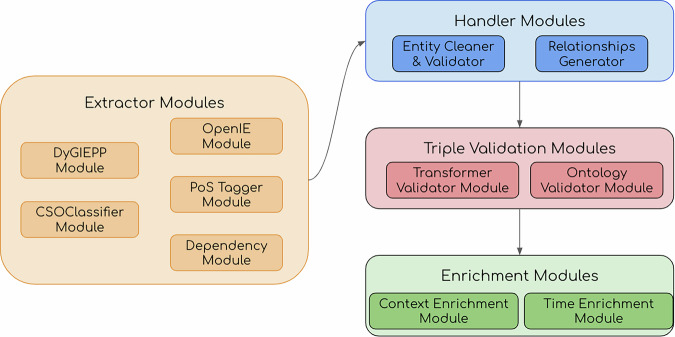
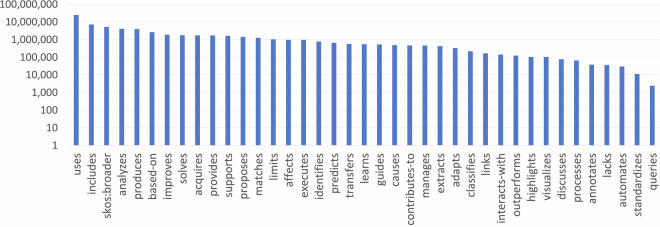
The rapid evolution of AI and the increased accessibility of scientific articles through open access marks a pivotal moment in research. AI-driven tools are reshaping how scientists explore, interpret, and contribute to the body of scientific knowledge, offering unprecedented opportunities. Nonetheless, a significant challenge remains: dealing with the overwhelming number of papers published every year. A promising solution is the use of knowledge graphs, which provide structured, interconnected, and formalized frameworks that improve the capabilities of AI systems to integrate information from the literature. This paper presents the last version of the Computer Science Knowledge Graph (CS-KG 2.0), an extensive knowledge base generated from 15 million research papers. CS-KG 2.0 describes 25 million entities linked by 67 million relationships, offering a nuanced representation of the scientific knowledge within the field of computer science. This innovative resource facilitates new research opportunities in key areas such as analysis and forecasting of research trends, hypothesis generation, smart literature search, automatic production of literature review, and scientific question-answering.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


