{"title":"强化液体状态机——基于强化的脉冲神经网络训练新策略。","authors":"Dominik Krenzer, Martin Bogdan","doi":"10.3389/fncom.2025.1569374","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Feedback and reinforcement signals in the brain act as natures sophisticated teaching tools, guiding neural circuits to self-organization, adaptation, and the encoding of complex patterns. This study investigates the impact of two feedback mechanisms within a deep liquid state machine architecture designed for spiking neural networks.</p><p><strong>Methods: </strong>The Reinforced Liquid State Machine architecture integrates liquid layers, a winner-takes-all mechanism, a linear readout layer, and a novel reward-based reinforcement system to enhance learning efficacy. While traditional Liquid State Machines often employ unsupervised approaches, we introduce strict feedback to improve network performance by not only reinforcing correct predictions but also penalizing wrong ones.</p><p><strong>Results: </strong>Strict feedback is compared to another strategy known as forgiving feedback, excluding punishment, using evaluations on the Spiking Heidelberg data. Experimental results demonstrate that both feedback mechanisms significantly outperform the baseline unsupervised approach, achieving superior accuracy and adaptability in response to dynamic input patterns.</p><p><strong>Discussion: </strong>This comparative analysis highlights the potential of feedback integration in deepened Liquid State Machines, offering insights into optimizing spiking neural networks through reinforcement-driven architectures.</p>","PeriodicalId":12363,"journal":{"name":"Frontiers in Computational Neuroscience","volume":"19 ","pages":"1569374"},"PeriodicalIF":2.3000,"publicationDate":"2025-05-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12141346/pdf/","citationCount":"0","resultStr":"{\"title\":\"Reinforced liquid state machines-new training strategies for spiking neural networks based on reinforcements.\",\"authors\":\"Dominik Krenzer, Martin Bogdan\",\"doi\":\"10.3389/fncom.2025.1569374\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Feedback and reinforcement signals in the brain act as natures sophisticated teaching tools, guiding neural circuits to self-organization, adaptation, and the encoding of complex patterns. This study investigates the impact of two feedback mechanisms within a deep liquid state machine architecture designed for spiking neural networks.</p><p><strong>Methods: </strong>The Reinforced Liquid State Machine architecture integrates liquid layers, a winner-takes-all mechanism, a linear readout layer, and a novel reward-based reinforcement system to enhance learning efficacy. While traditional Liquid State Machines often employ unsupervised approaches, we introduce strict feedback to improve network performance by not only reinforcing correct predictions but also penalizing wrong ones.</p><p><strong>Results: </strong>Strict feedback is compared to another strategy known as forgiving feedback, excluding punishment, using evaluations on the Spiking Heidelberg data. Experimental results demonstrate that both feedback mechanisms significantly outperform the baseline unsupervised approach, achieving superior accuracy and adaptability in response to dynamic input patterns.</p><p><strong>Discussion: </strong>This comparative analysis highlights the potential of feedback integration in deepened Liquid State Machines, offering insights into optimizing spiking neural networks through reinforcement-driven architectures.</p>\",\"PeriodicalId\":12363,\"journal\":{\"name\":\"Frontiers in Computational Neuroscience\",\"volume\":\"19 \",\"pages\":\"1569374\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2025-05-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12141346/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Computational Neuroscience\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3389/fncom.2025.1569374\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Computational Neuroscience","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3389/fncom.2025.1569374","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Reinforced liquid state machines-new training strategies for spiking neural networks based on reinforcements.
Introduction: Feedback and reinforcement signals in the brain act as natures sophisticated teaching tools, guiding neural circuits to self-organization, adaptation, and the encoding of complex patterns. This study investigates the impact of two feedback mechanisms within a deep liquid state machine architecture designed for spiking neural networks.
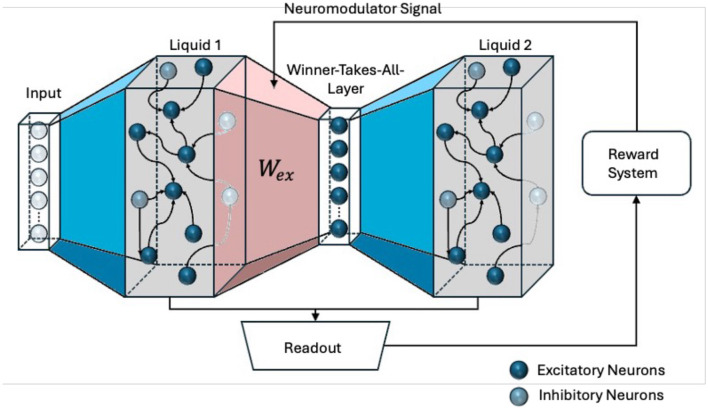
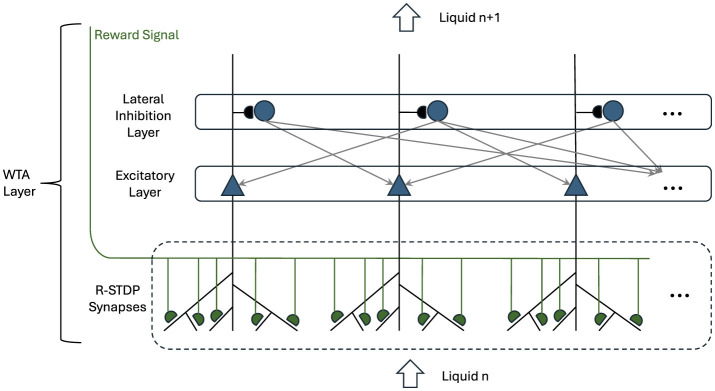
Methods: The Reinforced Liquid State Machine architecture integrates liquid layers, a winner-takes-all mechanism, a linear readout layer, and a novel reward-based reinforcement system to enhance learning efficacy. While traditional Liquid State Machines often employ unsupervised approaches, we introduce strict feedback to improve network performance by not only reinforcing correct predictions but also penalizing wrong ones.
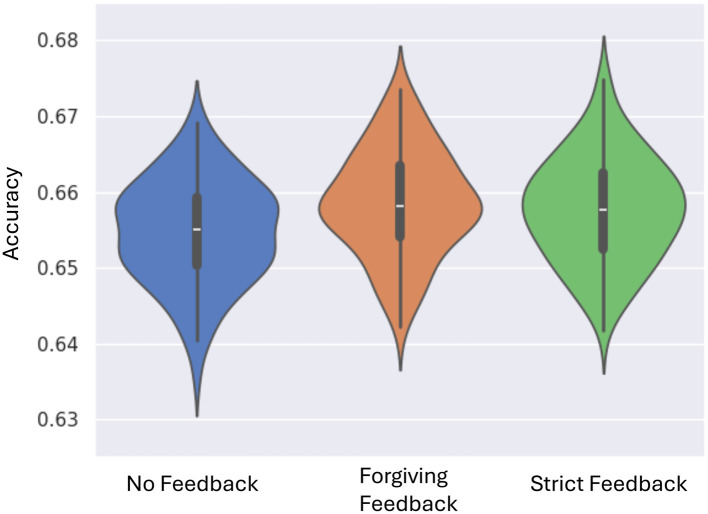
Results: Strict feedback is compared to another strategy known as forgiving feedback, excluding punishment, using evaluations on the Spiking Heidelberg data. Experimental results demonstrate that both feedback mechanisms significantly outperform the baseline unsupervised approach, achieving superior accuracy and adaptability in response to dynamic input patterns.
Discussion: This comparative analysis highlights the potential of feedback integration in deepened Liquid State Machines, offering insights into optimizing spiking neural networks through reinforcement-driven architectures.
期刊介绍:
Frontiers in Computational Neuroscience is a first-tier electronic journal devoted to promoting theoretical modeling of brain function and fostering interdisciplinary interactions between theoretical and experimental neuroscience. Progress in understanding the amazing capabilities of the brain is still limited, and we believe that it will only come with deep theoretical thinking and mutually stimulating cooperation between different disciplines and approaches. We therefore invite original contributions on a wide range of topics that present the fruits of such cooperation, or provide stimuli for future alliances. We aim to provide an interactive forum for cutting-edge theoretical studies of the nervous system, and for promulgating the best theoretical research to the broader neuroscience community. Models of all styles and at all levels are welcome, from biophysically motivated realistic simulations of neurons and synapses to high-level abstract models of inference and decision making. While the journal is primarily focused on theoretically based and driven research, we welcome experimental studies that validate and test theoretical conclusions.
Also: comp neuro
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


