{"title":"chatgpt - 01预览优于ChatGPT-4作为紧急情况下踝关节疼痛分类的诊断支持工具。","authors":"Pooya Hosseini-Monfared, Shayan Amiri, Alireza Mirahmadi, Amirhossein Shahbazi, Aliasghar Alamian, Mohammad Azizi, Seyed Morteza Kazemi","doi":"10.22037/aaemj.v13i1.2580","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>ChatGPT, a general-purpose language model, is not specifically optimized for medical applications. This study aimed to assess the performance of ChatGPT-4 and o1-preview in generating differential diagnoses for common cases of ankle pain in emergency settings.</p><p><strong>Methods: </strong>Common presentations of ankle pain were identified through consultations with an experienced orthopedic surgeon and a review of relevant hospital and social media sources. To replicate typical patient inquiries, questions were crafted in simple, non-technical language, requesting three possible differential diagnoses for each scenario. The second phase involved designing case vignettes reflecting scenarios typical for triage nurses or physicians. Responses from ChatGPT were evaluated against a benchmark established by two experienced orthopedic surgeons, with a scoring system assessing the accuracy, clarity, and relevance of the differential diagnoses based on their order.</p><p><strong>Results: </strong>In 21 ankle pain presentations, ChatGPT-o1 preview outperformed ChatGPT-4 in both accuracy and clarity, with only the clarity score reaching statistical significance (p < 0.001). ChatGPT-o1 preview also had a significantly higher total score (p = 0.004). In 15 case vignettes, ChatGPT-o1 preview scored better on diagnostic and management clarity, though differences in diagnostic accuracy were not statistically significant. Among 51 questions, ChatGPT-4 and ChatGPT-o1 preview produced incorrect responses for 5 (9.8%) and 4 (7.8%) questions, respectively. Inter-rater reliability analysis demonstrated excellent reliability of the scoring system with interclass coefficients of 0.99 (95% CI, 0.998-0.999) for accuracy scores and 0.99 (95% CI, 0.990-0.995) for clarity scores.</p><p><strong>Conclusion: </strong>Our findings demonstrated that both ChatGPT-4 and ChatGPT-o1 preview provide acceptable performance in the triage of ankle pain cases in emergency settings. ChatGPT-o1 preview outperformed ChatGPT-4, offering clearer and more precise responses. While both models show potential as supportive tools, their role should remain supervised and strictly supplementary to clinical expertise.</p>","PeriodicalId":8146,"journal":{"name":"Archives of Academic Emergency Medicine","volume":"13 1","pages":"e42"},"PeriodicalIF":2.0000,"publicationDate":"2025-04-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12145124/pdf/","citationCount":"0","resultStr":"{\"title\":\"ChatGPT-o1 Preview Outperforms ChatGPT-4 as a Diagnostic Support Tool for Ankle Pain Triage in Emergency Settings.\",\"authors\":\"Pooya Hosseini-Monfared, Shayan Amiri, Alireza Mirahmadi, Amirhossein Shahbazi, Aliasghar Alamian, Mohammad Azizi, Seyed Morteza Kazemi\",\"doi\":\"10.22037/aaemj.v13i1.2580\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>ChatGPT, a general-purpose language model, is not specifically optimized for medical applications. This study aimed to assess the performance of ChatGPT-4 and o1-preview in generating differential diagnoses for common cases of ankle pain in emergency settings.</p><p><strong>Methods: </strong>Common presentations of ankle pain were identified through consultations with an experienced orthopedic surgeon and a review of relevant hospital and social media sources. To replicate typical patient inquiries, questions were crafted in simple, non-technical language, requesting three possible differential diagnoses for each scenario. The second phase involved designing case vignettes reflecting scenarios typical for triage nurses or physicians. Responses from ChatGPT were evaluated against a benchmark established by two experienced orthopedic surgeons, with a scoring system assessing the accuracy, clarity, and relevance of the differential diagnoses based on their order.</p><p><strong>Results: </strong>In 21 ankle pain presentations, ChatGPT-o1 preview outperformed ChatGPT-4 in both accuracy and clarity, with only the clarity score reaching statistical significance (p < 0.001). ChatGPT-o1 preview also had a significantly higher total score (p = 0.004). In 15 case vignettes, ChatGPT-o1 preview scored better on diagnostic and management clarity, though differences in diagnostic accuracy were not statistically significant. Among 51 questions, ChatGPT-4 and ChatGPT-o1 preview produced incorrect responses for 5 (9.8%) and 4 (7.8%) questions, respectively. Inter-rater reliability analysis demonstrated excellent reliability of the scoring system with interclass coefficients of 0.99 (95% CI, 0.998-0.999) for accuracy scores and 0.99 (95% CI, 0.990-0.995) for clarity scores.</p><p><strong>Conclusion: </strong>Our findings demonstrated that both ChatGPT-4 and ChatGPT-o1 preview provide acceptable performance in the triage of ankle pain cases in emergency settings. ChatGPT-o1 preview outperformed ChatGPT-4, offering clearer and more precise responses. While both models show potential as supportive tools, their role should remain supervised and strictly supplementary to clinical expertise.</p>\",\"PeriodicalId\":8146,\"journal\":{\"name\":\"Archives of Academic Emergency Medicine\",\"volume\":\"13 1\",\"pages\":\"e42\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-04-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12145124/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Archives of Academic Emergency Medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.22037/aaemj.v13i1.2580\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"EMERGENCY MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of Academic Emergency Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22037/aaemj.v13i1.2580","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
ChatGPT-o1 Preview Outperforms ChatGPT-4 as a Diagnostic Support Tool for Ankle Pain Triage in Emergency Settings.
Introduction: ChatGPT, a general-purpose language model, is not specifically optimized for medical applications. This study aimed to assess the performance of ChatGPT-4 and o1-preview in generating differential diagnoses for common cases of ankle pain in emergency settings.
Methods: Common presentations of ankle pain were identified through consultations with an experienced orthopedic surgeon and a review of relevant hospital and social media sources. To replicate typical patient inquiries, questions were crafted in simple, non-technical language, requesting three possible differential diagnoses for each scenario. The second phase involved designing case vignettes reflecting scenarios typical for triage nurses or physicians. Responses from ChatGPT were evaluated against a benchmark established by two experienced orthopedic surgeons, with a scoring system assessing the accuracy, clarity, and relevance of the differential diagnoses based on their order.
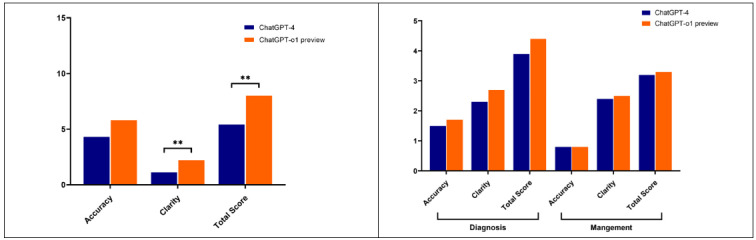
Results: In 21 ankle pain presentations, ChatGPT-o1 preview outperformed ChatGPT-4 in both accuracy and clarity, with only the clarity score reaching statistical significance (p < 0.001). ChatGPT-o1 preview also had a significantly higher total score (p = 0.004). In 15 case vignettes, ChatGPT-o1 preview scored better on diagnostic and management clarity, though differences in diagnostic accuracy were not statistically significant. Among 51 questions, ChatGPT-4 and ChatGPT-o1 preview produced incorrect responses for 5 (9.8%) and 4 (7.8%) questions, respectively. Inter-rater reliability analysis demonstrated excellent reliability of the scoring system with interclass coefficients of 0.99 (95% CI, 0.998-0.999) for accuracy scores and 0.99 (95% CI, 0.990-0.995) for clarity scores.
Conclusion: Our findings demonstrated that both ChatGPT-4 and ChatGPT-o1 preview provide acceptable performance in the triage of ankle pain cases in emergency settings. ChatGPT-o1 preview outperformed ChatGPT-4, offering clearer and more precise responses. While both models show potential as supportive tools, their role should remain supervised and strictly supplementary to clinical expertise.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


