评估人工智能聊天机器人阴茎增强信息:可读性、可靠性和质量的比较分析。
IF 2.5
3区 医学
Q2 UROLOGY & NEPHROLOGY
引用次数: 0
摘要
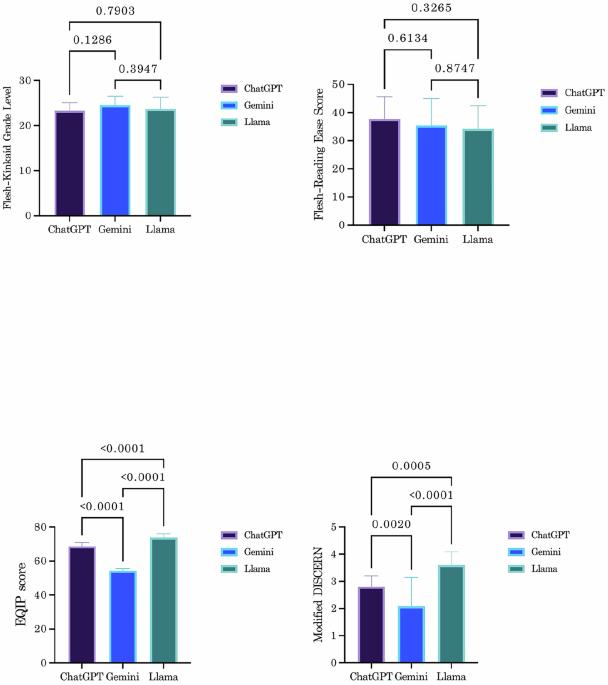
本研究旨在通过评估人工智能聊天机器人提供的阴茎增强(PE)信息的可靠性和质量来评估和比较人工智能聊天机器人的性能。通过谷歌trends (https://trends.google.com)和Semrush (https://www.semrush.com)确定了PE相关关键词的搜索趋势。考虑到区域趋势和搜索量的变化,对十年期间的数据进行了分析。基于这些趋势,选择了25个问题并将其分为三组:一般信息(GI),手术治疗(ST)和神话/误解(MM)。这些问题是向三个先进的聊天机器人提出的:ChatGPT-4、Gemini Pro和Llama 3.1。使用Flesch- kincaid Grade Level (FKGL)和Flesch Reading Ease Score (FRES)对每个模型的回复进行可读性分析,同时使用确保患者质量信息(EQIP)工具和修改后的DISCERN评分对回复的质量进行评估。根据FKGL和FRES,所有聊天机器人的回答都表现出可读性和理解性的困难,两者之间差异无统计学意义(FKGL: p = 0.167;FRES: p = 0.366)。Llama获得了最高的修正辨别分数中位数(4 [IQR:1]),显著优于ChatGPT (3 [IQR:0])和Gemini (3 [IQR:2])本文章由计算机程序翻译,如有差异,请以英文原文为准。
Evaluating AI chatbots in penis enhancement information: a comparative analysis of readability, reliability and quality
This study aims to evaluate and compare the performance of artificial intelligence chatbots by assessing the reliability and quality of the information they provide regarding penis enhancement (PE). Search trends for keywords related to PE were determined using Google Trends ( https://trends.google.com ) and Semrush ( https://www.semrush.com ). Data covering a ten-year period was analyzed, taking into account regional trends and changes in search volume. Based on these trends, 25 questions were selected and categorized into three groups: general information (GI), surgical treatment (ST) and myths/misconceptions (MM). These questions were posed to three advanced chatbots: ChatGPT-4, Gemini Pro and Llama 3.1. Responses from each model were analyzed for readability using the Flesch-Kincaid Grade Level (FKGL) and Flesch Reading Ease Score (FRES), while the quality of the responses was evaluated using the Ensuring Quality Information for Patients (EQIP) tool and the Modified DISCERN Score. All chatbot responses exhibited difficulty in readability and understanding according to FKGL and FRES, with no statistically significant differences among them (FKGL: p = 0.167; FRES: p = 0.366). Llama achieved the highest median Modified DISCERN score (4 [IQR:1]), significantly outperforming ChatGPT (3 [IQR:0]) and Gemini (3 [IQR:2]) (p < 0.001). Pairwise comparisons showed no significant difference between ChatGPT and Gemini (p = 0.070), but Llama was superior to both (p < 0.001). In EQIP scores, Llama also scored highest (73.8 ± 2.2), significantly surpassing ChatGPT (68.7 ± 2.1) and Gemini (54.2 ± 1.3) (p < 0.001). Across categories, Llama consistently achieved higher EQIP scores (GI:71.1 ± 1.6; ST: 73.6 ± 4.1; MM: 76.3 ± 2.1) and Modified DISCERN scores (GI:4 [IQR:0]; ST:4 [IQR:1]; MM:3 [IQR:1]) compared to ChatGPT (EQIP: GI:68.4 ± 1.1; ST: 65.7 ± 2.2; MM:71.1 ± 1.7; Modified DISCERN: GI:3 [IQR:1]; ST:3 [IQR:1]; MM:3 [IQR:0]) and Gemini (EQIP: GI:55.2 ± 1.4; ST:55.2 ± 1.6; MM:2.6 ± 2.5; Modified DISCERN: GI:1 [IQR:2]; ST:1 [IQR:2]; MM:3 [IQR:0]) (p < 0.001). This study highlights Llama’s superior reliability in providing PE-related health information, though all chatbots struggled with readability.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

International Journal of Impotence Research
医学-泌尿学与肾脏学
CiteScore
4.90
自引率
19.20%
发文量
140
审稿时长
>12 weeks
期刊介绍:
International Journal of Impotence Research: The Journal of Sexual Medicine addresses sexual medicine for both genders as an interdisciplinary field. This includes basic science researchers, urologists, endocrinologists, cardiologists, family practitioners, gynecologists, internists, neurologists, psychiatrists, psychologists, radiologists and other health care clinicians.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


