Yolanda Freire, Andrea Santamaría Laorden, Jaime Orejas Pérez, Ignacio Ortiz Collado, Margarita Gómez Sánchez, Israel J Thuissard Vasallo, Víctor Díaz-Flores García, Ana Suárez
{"title":"评估快速配方对ChatGPT在种植体中可靠性和可重复性的影响。","authors":"Yolanda Freire, Andrea Santamaría Laorden, Jaime Orejas Pérez, Ignacio Ortiz Collado, Margarita Gómez Sánchez, Israel J Thuissard Vasallo, Víctor Díaz-Flores García, Ana Suárez","doi":"10.1371/journal.pone.0323086","DOIUrl":null,"url":null,"abstract":"<p><p>Language models (LLMs) such as ChatGPT are widely available to any dental professional. However, there is limited evidence to evaluate the reliability and reproducibility of ChatGPT-4 in relation to implant-supported prostheses, as well as the impact of prompt design on its responses. This constrains understanding of its application within this specific area of dentistry. The purpose of this study was to evaluate the performance of ChatGPT-4 in generating answers about implant-supported prostheses using different prompts. Thirty questions on implant-supported and implant-retained prostheses were posed, with 30 answers generated per question using general and specific prompts, totaling 1800 answers. Experts assessed reliability (agreement with expert grading) and repeatability (response consistency) using a 3-point Likert scale. General prompts achieved 70.89% reliability, with repeatability ranging from moderate to almost perfect. Specific prompts showed higher performance, with 78.8% reliability and substantial to almost perfect repeatability. The specific prompt significantly improved reliability compared to the general prompt. Despite these promising results, ChatGPT's ability to generate reliable answers on implant-supported prostheses remains limited, highlighting the need for professional oversight. Using specific prompts can enhance its performance. The use of a specific prompt might improve the answer generation performance of ChatGPT.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"20 5","pages":"e0323086"},"PeriodicalIF":2.6000,"publicationDate":"2025-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12124515/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating the influence of prompt formulation on the reliability and repeatability of ChatGPT in implant-supported prostheses.\",\"authors\":\"Yolanda Freire, Andrea Santamaría Laorden, Jaime Orejas Pérez, Ignacio Ortiz Collado, Margarita Gómez Sánchez, Israel J Thuissard Vasallo, Víctor Díaz-Flores García, Ana Suárez\",\"doi\":\"10.1371/journal.pone.0323086\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Language models (LLMs) such as ChatGPT are widely available to any dental professional. However, there is limited evidence to evaluate the reliability and reproducibility of ChatGPT-4 in relation to implant-supported prostheses, as well as the impact of prompt design on its responses. This constrains understanding of its application within this specific area of dentistry. The purpose of this study was to evaluate the performance of ChatGPT-4 in generating answers about implant-supported prostheses using different prompts. Thirty questions on implant-supported and implant-retained prostheses were posed, with 30 answers generated per question using general and specific prompts, totaling 1800 answers. Experts assessed reliability (agreement with expert grading) and repeatability (response consistency) using a 3-point Likert scale. General prompts achieved 70.89% reliability, with repeatability ranging from moderate to almost perfect. Specific prompts showed higher performance, with 78.8% reliability and substantial to almost perfect repeatability. The specific prompt significantly improved reliability compared to the general prompt. Despite these promising results, ChatGPT's ability to generate reliable answers on implant-supported prostheses remains limited, highlighting the need for professional oversight. Using specific prompts can enhance its performance. The use of a specific prompt might improve the answer generation performance of ChatGPT.</p>\",\"PeriodicalId\":20189,\"journal\":{\"name\":\"PLoS ONE\",\"volume\":\"20 5\",\"pages\":\"e0323086\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2025-05-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12124515/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLoS ONE\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pone.0323086\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0323086","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Evaluating the influence of prompt formulation on the reliability and repeatability of ChatGPT in implant-supported prostheses.
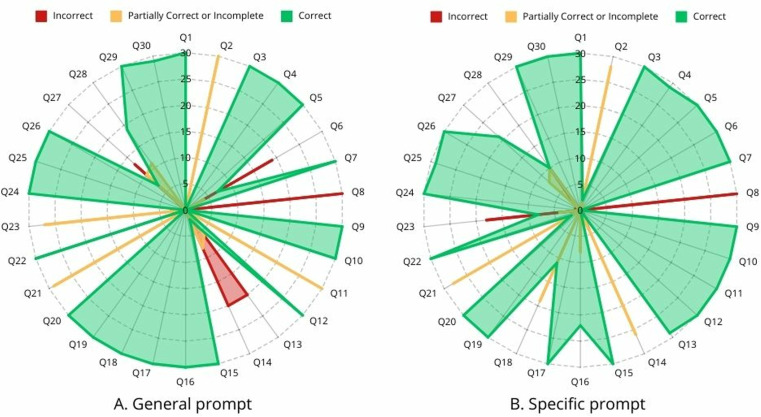
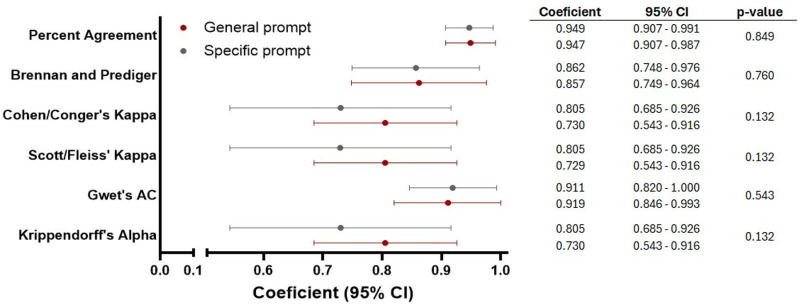
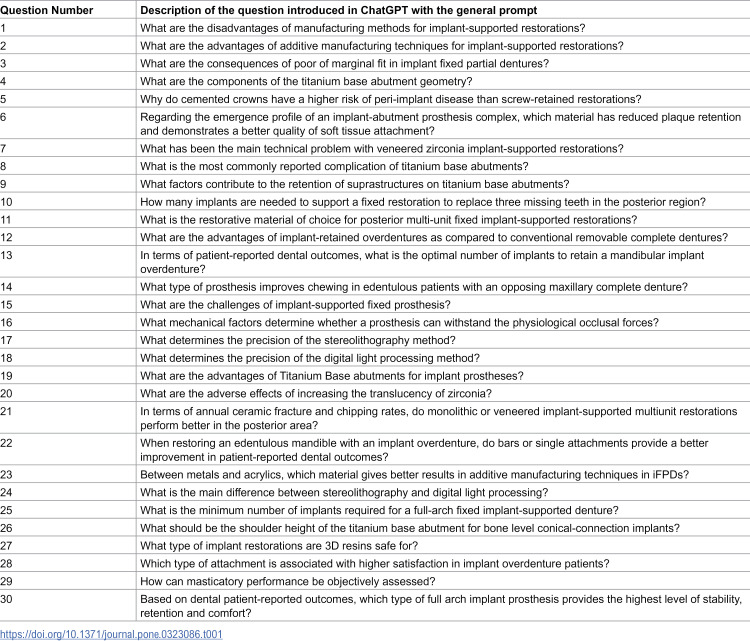
Language models (LLMs) such as ChatGPT are widely available to any dental professional. However, there is limited evidence to evaluate the reliability and reproducibility of ChatGPT-4 in relation to implant-supported prostheses, as well as the impact of prompt design on its responses. This constrains understanding of its application within this specific area of dentistry. The purpose of this study was to evaluate the performance of ChatGPT-4 in generating answers about implant-supported prostheses using different prompts. Thirty questions on implant-supported and implant-retained prostheses were posed, with 30 answers generated per question using general and specific prompts, totaling 1800 answers. Experts assessed reliability (agreement with expert grading) and repeatability (response consistency) using a 3-point Likert scale. General prompts achieved 70.89% reliability, with repeatability ranging from moderate to almost perfect. Specific prompts showed higher performance, with 78.8% reliability and substantial to almost perfect repeatability. The specific prompt significantly improved reliability compared to the general prompt. Despite these promising results, ChatGPT's ability to generate reliable answers on implant-supported prostheses remains limited, highlighting the need for professional oversight. Using specific prompts can enhance its performance. The use of a specific prompt might improve the answer generation performance of ChatGPT.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


