Reem Agbareia, Mahmud Omar, Ofira Zloto, Benjamin S Glicksberg, Girish N Nadkarni, Eyal Klang
{"title":"通过OCT进行视网膜疾病诊断的多模态llm:少次学习与单次学习。","authors":"Reem Agbareia, Mahmud Omar, Ofira Zloto, Benjamin S Glicksberg, Girish N Nadkarni, Eyal Klang","doi":"10.1177/25158414251340569","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and aim: </strong>Multimodal large language models (LLMs) have shown potential in processing both text and image data for clinical applications. This study evaluated their diagnostic performance in identifying retinal diseases from optical coherence tomography (OCT) images.</p><p><strong>Methods: </strong>We assessed the diagnostic accuracy of GPT-4o and Claude Sonnet 3.5 using two public OCT datasets (OCTID, OCTDL) containing expert-labeled images of four pathological conditions and normal retinas. Both models were tested using single-shot and few-shot prompts, with an overall of 3088 models' API calls. Statistical analyses were performed to evaluate differences in overall and condition-specific performance.</p><p><strong>Results: </strong>GPT-4o's accuracy improved from 56.29% with single-shot prompts to 73.08% with few-shot prompts (<i>p</i> < 0.001). Similarly, Claude Sonnet 3.5 increased from 40.03% to 70.98% using the same approach (<i>p</i> < 0.001). Condition-specific analyses revealed similar trends, with absolute improvements ranging from 2% to 64%. These findings were consistent across the validation dataset.</p><p><strong>Conclusion: </strong>Few-shot prompted multimodal LLMs show promise for clinical integration, particularly in identifying normal retinas, which could help streamline referral processes in primary care. While these models fall short of the diagnostic accuracy reported in established deep learning literature, they offer simple, effective tools for assisting in routine retinal disease diagnosis. Future research should focus on further validation and integrating clinical text data with imaging.</p>","PeriodicalId":23054,"journal":{"name":"Therapeutic Advances in Ophthalmology","volume":"17 ","pages":"25158414251340569"},"PeriodicalIF":2.3000,"publicationDate":"2025-05-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12093016/pdf/","citationCount":"0","resultStr":"{\"title\":\"Multimodal LLMs for retinal disease diagnosis via OCT: few-shot versus single-shot learning.\",\"authors\":\"Reem Agbareia, Mahmud Omar, Ofira Zloto, Benjamin S Glicksberg, Girish N Nadkarni, Eyal Klang\",\"doi\":\"10.1177/25158414251340569\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background and aim: </strong>Multimodal large language models (LLMs) have shown potential in processing both text and image data for clinical applications. This study evaluated their diagnostic performance in identifying retinal diseases from optical coherence tomography (OCT) images.</p><p><strong>Methods: </strong>We assessed the diagnostic accuracy of GPT-4o and Claude Sonnet 3.5 using two public OCT datasets (OCTID, OCTDL) containing expert-labeled images of four pathological conditions and normal retinas. Both models were tested using single-shot and few-shot prompts, with an overall of 3088 models' API calls. Statistical analyses were performed to evaluate differences in overall and condition-specific performance.</p><p><strong>Results: </strong>GPT-4o's accuracy improved from 56.29% with single-shot prompts to 73.08% with few-shot prompts (<i>p</i> < 0.001). Similarly, Claude Sonnet 3.5 increased from 40.03% to 70.98% using the same approach (<i>p</i> < 0.001). Condition-specific analyses revealed similar trends, with absolute improvements ranging from 2% to 64%. These findings were consistent across the validation dataset.</p><p><strong>Conclusion: </strong>Few-shot prompted multimodal LLMs show promise for clinical integration, particularly in identifying normal retinas, which could help streamline referral processes in primary care. While these models fall short of the diagnostic accuracy reported in established deep learning literature, they offer simple, effective tools for assisting in routine retinal disease diagnosis. Future research should focus on further validation and integrating clinical text data with imaging.</p>\",\"PeriodicalId\":23054,\"journal\":{\"name\":\"Therapeutic Advances in Ophthalmology\",\"volume\":\"17 \",\"pages\":\"25158414251340569\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2025-05-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12093016/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Therapeutic Advances in Ophthalmology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1177/25158414251340569\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"OPHTHALMOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Therapeutic Advances in Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/25158414251340569","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
Multimodal LLMs for retinal disease diagnosis via OCT: few-shot versus single-shot learning.
Background and aim: Multimodal large language models (LLMs) have shown potential in processing both text and image data for clinical applications. This study evaluated their diagnostic performance in identifying retinal diseases from optical coherence tomography (OCT) images.
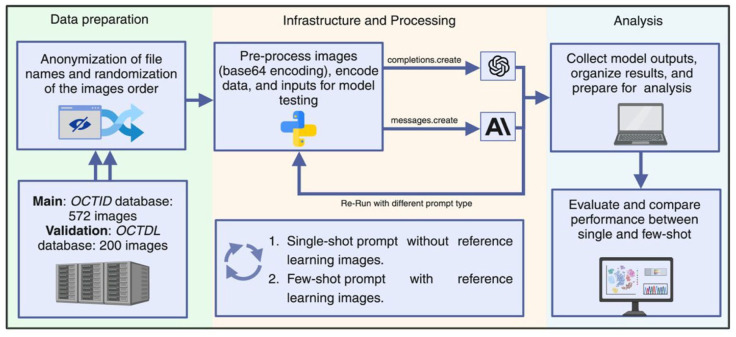
Methods: We assessed the diagnostic accuracy of GPT-4o and Claude Sonnet 3.5 using two public OCT datasets (OCTID, OCTDL) containing expert-labeled images of four pathological conditions and normal retinas. Both models were tested using single-shot and few-shot prompts, with an overall of 3088 models' API calls. Statistical analyses were performed to evaluate differences in overall and condition-specific performance.
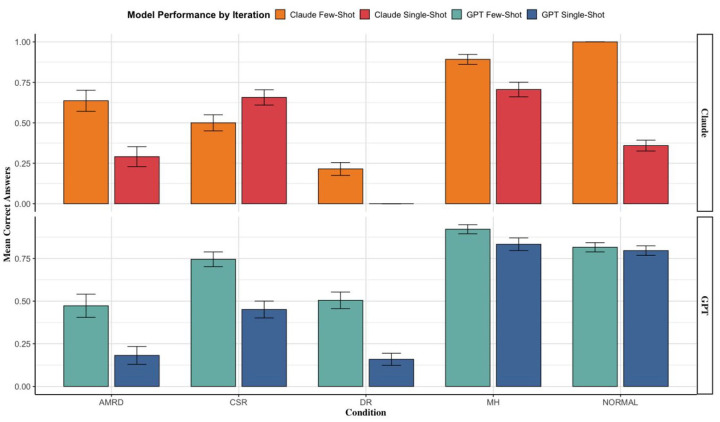
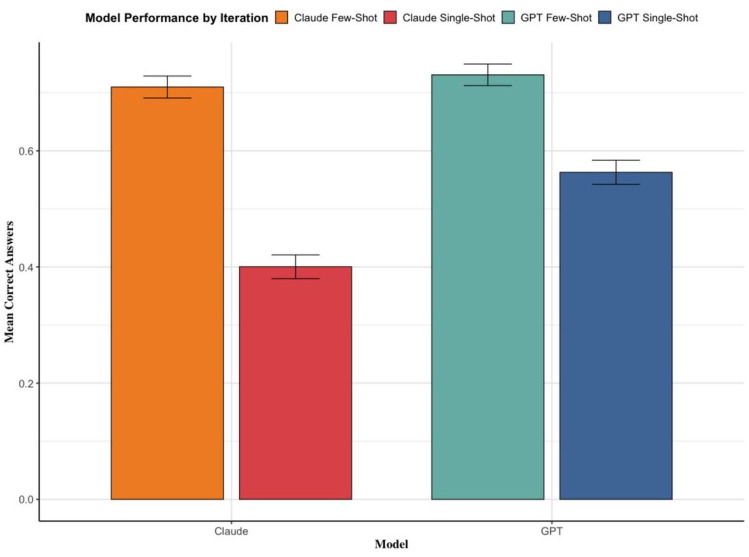
Results: GPT-4o's accuracy improved from 56.29% with single-shot prompts to 73.08% with few-shot prompts (p < 0.001). Similarly, Claude Sonnet 3.5 increased from 40.03% to 70.98% using the same approach (p < 0.001). Condition-specific analyses revealed similar trends, with absolute improvements ranging from 2% to 64%. These findings were consistent across the validation dataset.
Conclusion: Few-shot prompted multimodal LLMs show promise for clinical integration, particularly in identifying normal retinas, which could help streamline referral processes in primary care. While these models fall short of the diagnostic accuracy reported in established deep learning literature, they offer simple, effective tools for assisting in routine retinal disease diagnosis. Future research should focus on further validation and integrating clinical text data with imaging.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


