Oya Kalaycıoğlu, Menelaos Pavlou, Serhat E Akhanlı, Mark A de Belder, Gareth Ambler, Rumana Z Omar
{"title":"评估基于树的集成机器学习技术用于临床风险预测的样本量要求。","authors":"Oya Kalaycıoğlu, Menelaos Pavlou, Serhat E Akhanlı, Mark A de Belder, Gareth Ambler, Rumana Z Omar","doi":"10.1177/09622802251338983","DOIUrl":null,"url":null,"abstract":"<p><p>Machine learning techniques (MLTs) are increasingly being used to develop clinical risk prediction models for binary health outcomes but the sample size requirements for developing and validating such models remain unclear. This study investigates whether sample size guidelines that target mean absolute prediction error (MAPE) for logistic regression models can be applied to tree-based ensemble MLTs (bagging, random forests, and boosting). Simulations based on two large cardiovascular datasets were used to evaluate the performance of MLTs in terms of MAPE, calibration, the <i>C</i>-statistic and Brier score, across six data-generating mechanisms (DGMs) and varying sample sizes. When the DGM and analysis model matched, boosting required a sample size 2-3 times larger than recommended; random forests and bagging did not achieve the target MAPE even with a 12-fold increase. For a neutral DGM that did not match any of the analysis models, logistic regression with only main effects and boosting resulted in target MAPE values with a 12-fold increase in the recommended sample size. For external validation, our simulations showed that sample size guidelines to achieve a target precision of the estimated <i>C</i>-statistic were suitable, and thus may be used to inform sample size calculations for MLTs.</p>","PeriodicalId":22038,"journal":{"name":"Statistical Methods in Medical Research","volume":" ","pages":"1356-1372"},"PeriodicalIF":1.9000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12308042/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating the sample size requirements of tree-based ensemble machine learning techniques for clinical risk prediction.\",\"authors\":\"Oya Kalaycıoğlu, Menelaos Pavlou, Serhat E Akhanlı, Mark A de Belder, Gareth Ambler, Rumana Z Omar\",\"doi\":\"10.1177/09622802251338983\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Machine learning techniques (MLTs) are increasingly being used to develop clinical risk prediction models for binary health outcomes but the sample size requirements for developing and validating such models remain unclear. This study investigates whether sample size guidelines that target mean absolute prediction error (MAPE) for logistic regression models can be applied to tree-based ensemble MLTs (bagging, random forests, and boosting). Simulations based on two large cardiovascular datasets were used to evaluate the performance of MLTs in terms of MAPE, calibration, the <i>C</i>-statistic and Brier score, across six data-generating mechanisms (DGMs) and varying sample sizes. When the DGM and analysis model matched, boosting required a sample size 2-3 times larger than recommended; random forests and bagging did not achieve the target MAPE even with a 12-fold increase. For a neutral DGM that did not match any of the analysis models, logistic regression with only main effects and boosting resulted in target MAPE values with a 12-fold increase in the recommended sample size. For external validation, our simulations showed that sample size guidelines to achieve a target precision of the estimated <i>C</i>-statistic were suitable, and thus may be used to inform sample size calculations for MLTs.</p>\",\"PeriodicalId\":22038,\"journal\":{\"name\":\"Statistical Methods in Medical Research\",\"volume\":\" \",\"pages\":\"1356-1372\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2025-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12308042/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Statistical Methods in Medical Research\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1177/09622802251338983\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/5/14 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Statistical Methods in Medical Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1177/09622802251338983","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/5/14 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Evaluating the sample size requirements of tree-based ensemble machine learning techniques for clinical risk prediction.
Machine learning techniques (MLTs) are increasingly being used to develop clinical risk prediction models for binary health outcomes but the sample size requirements for developing and validating such models remain unclear. This study investigates whether sample size guidelines that target mean absolute prediction error (MAPE) for logistic regression models can be applied to tree-based ensemble MLTs (bagging, random forests, and boosting). Simulations based on two large cardiovascular datasets were used to evaluate the performance of MLTs in terms of MAPE, calibration, the C-statistic and Brier score, across six data-generating mechanisms (DGMs) and varying sample sizes. When the DGM and analysis model matched, boosting required a sample size 2-3 times larger than recommended; random forests and bagging did not achieve the target MAPE even with a 12-fold increase. For a neutral DGM that did not match any of the analysis models, logistic regression with only main effects and boosting resulted in target MAPE values with a 12-fold increase in the recommended sample size. For external validation, our simulations showed that sample size guidelines to achieve a target precision of the estimated C-statistic were suitable, and thus may be used to inform sample size calculations for MLTs.
期刊介绍:
Statistical Methods in Medical Research is a peer reviewed scholarly journal and is the leading vehicle for articles in all the main areas of medical statistics and an essential reference for all medical statisticians. This unique journal is devoted solely to statistics and medicine and aims to keep professionals abreast of the many powerful statistical techniques now available to the medical profession. This journal is a member of the Committee on Publication Ethics (COPE)
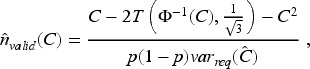
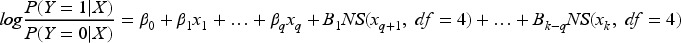
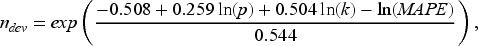

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


