{"title":"分布式双过程模型预测了不确定条件下决策的战略转移。","authors":"Mianzhi Hu, Hilary J Don, Darrell A Worthy","doi":"10.1038/s44271-025-00249-y","DOIUrl":null,"url":null,"abstract":"<p><p>In an uncertain world, human decision-making often involves adaptively leveraging different strategies to maximize gains. These strategic shifts, however, are overlooked by many traditional reinforcement learning models. Here, we incorporate parallel evaluation systems into distribution-based modeling and propose an entropy-weighted dual-process model that leverages Dirichlet and multivariate Gaussian distributions to represent frequency and value-based decision-making strategies, respectively. Model simulations and empirical tests demonstrated that our model outperformed traditional RL models by uniquely capturing participants' strategic change from value-based to frequency-based learning in response to heightened uncertainty. As reward variance increased, participants switched from focusing on actual rewards to using reward frequency as a proxy for value, thereby showing greater preference for more frequently rewarded but less valuable options. These findings suggest that increased uncertainty encourages the compensatory use of diverse evaluation methods, and our dual-process model provides a promising framework for studying multi-system decision-making in complex, multivariable contexts.</p>","PeriodicalId":501698,"journal":{"name":"Communications Psychology","volume":"3 1","pages":"61"},"PeriodicalIF":0.0000,"publicationDate":"2025-04-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11997072/pdf/","citationCount":"0","resultStr":"{\"title\":\"Distributional dual-process model predicts strategic shifts in decision-making under uncertainty.\",\"authors\":\"Mianzhi Hu, Hilary J Don, Darrell A Worthy\",\"doi\":\"10.1038/s44271-025-00249-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In an uncertain world, human decision-making often involves adaptively leveraging different strategies to maximize gains. These strategic shifts, however, are overlooked by many traditional reinforcement learning models. Here, we incorporate parallel evaluation systems into distribution-based modeling and propose an entropy-weighted dual-process model that leverages Dirichlet and multivariate Gaussian distributions to represent frequency and value-based decision-making strategies, respectively. Model simulations and empirical tests demonstrated that our model outperformed traditional RL models by uniquely capturing participants' strategic change from value-based to frequency-based learning in response to heightened uncertainty. As reward variance increased, participants switched from focusing on actual rewards to using reward frequency as a proxy for value, thereby showing greater preference for more frequently rewarded but less valuable options. These findings suggest that increased uncertainty encourages the compensatory use of diverse evaluation methods, and our dual-process model provides a promising framework for studying multi-system decision-making in complex, multivariable contexts.</p>\",\"PeriodicalId\":501698,\"journal\":{\"name\":\"Communications Psychology\",\"volume\":\"3 1\",\"pages\":\"61\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-04-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11997072/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Communications Psychology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1038/s44271-025-00249-y\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communications Psychology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s44271-025-00249-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Distributional dual-process model predicts strategic shifts in decision-making under uncertainty.
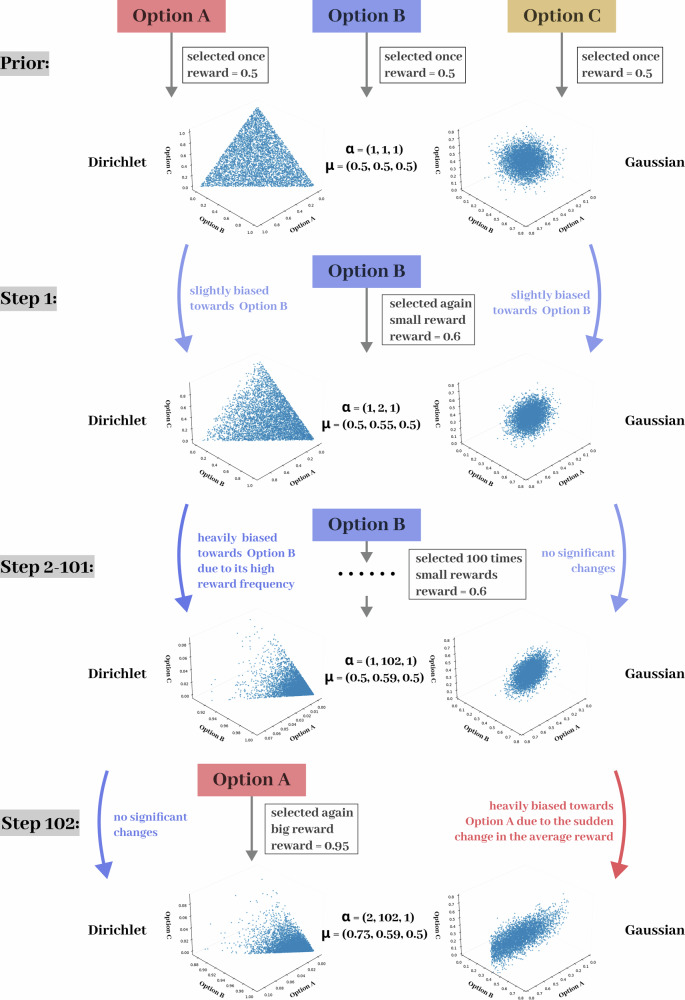
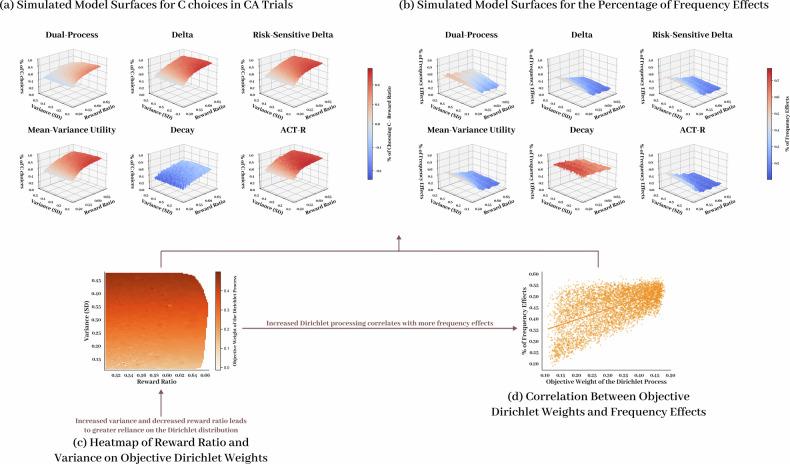
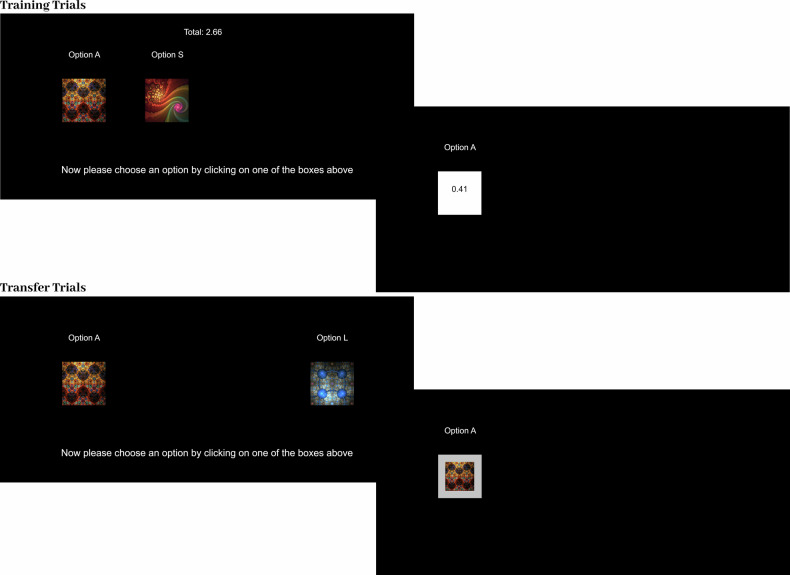
In an uncertain world, human decision-making often involves adaptively leveraging different strategies to maximize gains. These strategic shifts, however, are overlooked by many traditional reinforcement learning models. Here, we incorporate parallel evaluation systems into distribution-based modeling and propose an entropy-weighted dual-process model that leverages Dirichlet and multivariate Gaussian distributions to represent frequency and value-based decision-making strategies, respectively. Model simulations and empirical tests demonstrated that our model outperformed traditional RL models by uniquely capturing participants' strategic change from value-based to frequency-based learning in response to heightened uncertainty. As reward variance increased, participants switched from focusing on actual rewards to using reward frequency as a proxy for value, thereby showing greater preference for more frequently rewarded but less valuable options. These findings suggest that increased uncertainty encourages the compensatory use of diverse evaluation methods, and our dual-process model provides a promising framework for studying multi-system decision-making in complex, multivariable contexts.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


