Ramadhani Chambuso, Takudzwa Nyasha Musarurwa, Alessandro Pietro Aldera, Armin Deffur, Hayli Geffen, Douglas Perkins, Raj Ramesar
{"title":"基因组学和综合临床数据机器学习评分模型确定可能的Lynch综合征患者。","authors":"Ramadhani Chambuso, Takudzwa Nyasha Musarurwa, Alessandro Pietro Aldera, Armin Deffur, Hayli Geffen, Douglas Perkins, Raj Ramesar","doi":"10.1038/s44276-025-00140-7","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Lynch syndrome (LS) screening methods include multistep molecular somatic tumor testing to distinguish likely-LS patients from sporadic cases, which can be costly and complex. Also, direct germline testing for LS for every diagnosed solid cancer patient is a challenge in resource limited settings. We developed a unique machine learning scoring model to ascertain likely-LS cases from a cohort of colorectal cancer (CRC) patients.</p><p><strong>Methods: </strong>We used CRC patients from the cBioPortal database (TCGA studies) with complete clinicopathologic and somatic genomics data. We determined the rate of pathogenic/likely pathogenic variants in five (5) LS genes (MLH1, MSH2, MSH6, PMS2, EPCAM), and the BRAF mutations using a pre-designed bioinformatic annotation pipeline. Annovar, Intervar, Variant Effect Predictor (VEP), and OncoKB software tools were used to functionally annotate and interpret somatic variants detected. The OncoKB precision oncology knowledge base was used to provide information on the effects of the identified variants. We scored the clinicopathologic and somatic genomics data automatically using a machine learning model to discriminate between likely-LS and sporadic CRC cases. The training and testing datasets comprised of 80% and 20% of the total CRC patients, respectively. Group regularisation methods in combination with 10-fold cross-validation were performed for feature selection on the training data.</p><p><strong>Results: </strong>Out of 4800 CRC patients frorm the TCGA datasets with clinicopathological and somatic genomics data, we ascertained 524 patients with complete data. The scoring model using both clinicopathological and genetic characteristics for likely-LS showed a sensitivity and specificity of 100%, and both had the maximum accuracy, area under the curve (AUC) and AUC for precision-recall (AUCPR) of 1. In a similar analysis, the training and testing models that only relied on clinical or pathological characteristics had a sensitivity of 0.88 and 0.50, specificity of 0.55 and 0.51, accuracy of 0.58 and 0.51, AUC of 0.74 and 0.61, and AUCPR of 0.21 and 0.19, respectively.</p><p><strong>Conclusions: </strong>Simultaneous scoring of LS clinicopathological and somatic genomics data can improve prediction and ascertainment for likely-LS from all CRC cases. This approach can increase accuracy while reducing the reliance on expensive direct germline testing for all CRC patients, making LS screening more accessible and cost-effective, especially in resource-limited settings.</p>","PeriodicalId":519964,"journal":{"name":"BJC reports","volume":"3 1","pages":"30"},"PeriodicalIF":0.0000,"publicationDate":"2025-05-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12053672/pdf/","citationCount":"0","resultStr":"{\"title\":\"Genomics and integrative clinical data machine learning scoring model to ascertain likely Lynch syndrome patients.\",\"authors\":\"Ramadhani Chambuso, Takudzwa Nyasha Musarurwa, Alessandro Pietro Aldera, Armin Deffur, Hayli Geffen, Douglas Perkins, Raj Ramesar\",\"doi\":\"10.1038/s44276-025-00140-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Lynch syndrome (LS) screening methods include multistep molecular somatic tumor testing to distinguish likely-LS patients from sporadic cases, which can be costly and complex. Also, direct germline testing for LS for every diagnosed solid cancer patient is a challenge in resource limited settings. We developed a unique machine learning scoring model to ascertain likely-LS cases from a cohort of colorectal cancer (CRC) patients.</p><p><strong>Methods: </strong>We used CRC patients from the cBioPortal database (TCGA studies) with complete clinicopathologic and somatic genomics data. We determined the rate of pathogenic/likely pathogenic variants in five (5) LS genes (MLH1, MSH2, MSH6, PMS2, EPCAM), and the BRAF mutations using a pre-designed bioinformatic annotation pipeline. Annovar, Intervar, Variant Effect Predictor (VEP), and OncoKB software tools were used to functionally annotate and interpret somatic variants detected. The OncoKB precision oncology knowledge base was used to provide information on the effects of the identified variants. We scored the clinicopathologic and somatic genomics data automatically using a machine learning model to discriminate between likely-LS and sporadic CRC cases. The training and testing datasets comprised of 80% and 20% of the total CRC patients, respectively. Group regularisation methods in combination with 10-fold cross-validation were performed for feature selection on the training data.</p><p><strong>Results: </strong>Out of 4800 CRC patients frorm the TCGA datasets with clinicopathological and somatic genomics data, we ascertained 524 patients with complete data. The scoring model using both clinicopathological and genetic characteristics for likely-LS showed a sensitivity and specificity of 100%, and both had the maximum accuracy, area under the curve (AUC) and AUC for precision-recall (AUCPR) of 1. In a similar analysis, the training and testing models that only relied on clinical or pathological characteristics had a sensitivity of 0.88 and 0.50, specificity of 0.55 and 0.51, accuracy of 0.58 and 0.51, AUC of 0.74 and 0.61, and AUCPR of 0.21 and 0.19, respectively.</p><p><strong>Conclusions: </strong>Simultaneous scoring of LS clinicopathological and somatic genomics data can improve prediction and ascertainment for likely-LS from all CRC cases. This approach can increase accuracy while reducing the reliance on expensive direct germline testing for all CRC patients, making LS screening more accessible and cost-effective, especially in resource-limited settings.</p>\",\"PeriodicalId\":519964,\"journal\":{\"name\":\"BJC reports\",\"volume\":\"3 1\",\"pages\":\"30\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-05-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12053672/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BJC reports\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1038/s44276-025-00140-7\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BJC reports","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s44276-025-00140-7","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Genomics and integrative clinical data machine learning scoring model to ascertain likely Lynch syndrome patients.
Background: Lynch syndrome (LS) screening methods include multistep molecular somatic tumor testing to distinguish likely-LS patients from sporadic cases, which can be costly and complex. Also, direct germline testing for LS for every diagnosed solid cancer patient is a challenge in resource limited settings. We developed a unique machine learning scoring model to ascertain likely-LS cases from a cohort of colorectal cancer (CRC) patients.
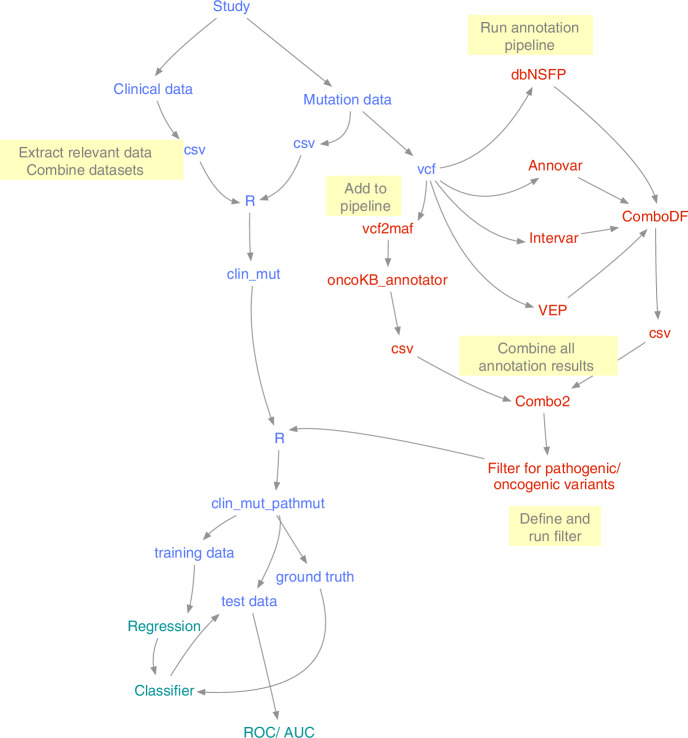
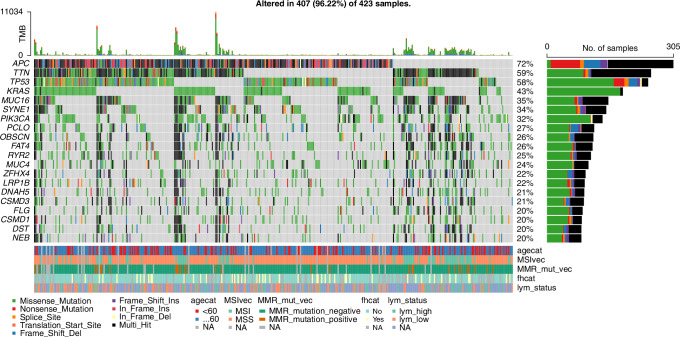
Methods: We used CRC patients from the cBioPortal database (TCGA studies) with complete clinicopathologic and somatic genomics data. We determined the rate of pathogenic/likely pathogenic variants in five (5) LS genes (MLH1, MSH2, MSH6, PMS2, EPCAM), and the BRAF mutations using a pre-designed bioinformatic annotation pipeline. Annovar, Intervar, Variant Effect Predictor (VEP), and OncoKB software tools were used to functionally annotate and interpret somatic variants detected. The OncoKB precision oncology knowledge base was used to provide information on the effects of the identified variants. We scored the clinicopathologic and somatic genomics data automatically using a machine learning model to discriminate between likely-LS and sporadic CRC cases. The training and testing datasets comprised of 80% and 20% of the total CRC patients, respectively. Group regularisation methods in combination with 10-fold cross-validation were performed for feature selection on the training data.
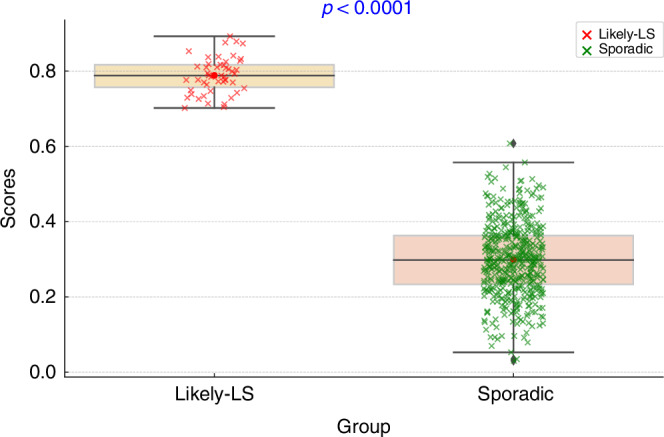
Results: Out of 4800 CRC patients frorm the TCGA datasets with clinicopathological and somatic genomics data, we ascertained 524 patients with complete data. The scoring model using both clinicopathological and genetic characteristics for likely-LS showed a sensitivity and specificity of 100%, and both had the maximum accuracy, area under the curve (AUC) and AUC for precision-recall (AUCPR) of 1. In a similar analysis, the training and testing models that only relied on clinical or pathological characteristics had a sensitivity of 0.88 and 0.50, specificity of 0.55 and 0.51, accuracy of 0.58 and 0.51, AUC of 0.74 and 0.61, and AUCPR of 0.21 and 0.19, respectively.
Conclusions: Simultaneous scoring of LS clinicopathological and somatic genomics data can improve prediction and ascertainment for likely-LS from all CRC cases. This approach can increase accuracy while reducing the reliance on expensive direct germline testing for all CRC patients, making LS screening more accessible and cost-effective, especially in resource-limited settings.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


