Amna A Othman, Kendall A Flaharty, Suzanna E Ledgister Hanchard, Ping Hu, Dat Duong, Rebekah L Waikel, Benjamin D Solomon
{"title":"评估遗传条件下与衰老相关的大型语言模型性能。","authors":"Amna A Othman, Kendall A Flaharty, Suzanna E Ledgister Hanchard, Ping Hu, Dat Duong, Rebekah L Waikel, Benjamin D Solomon","doi":"10.1038/s41514-025-00226-z","DOIUrl":null,"url":null,"abstract":"<p><p>Most genetic conditions are described in pediatric populations, leaving a gap in understanding their clinical progression and management in adulthood. Motivated by other applications of large language models (LLMs), we evaluated whether Llama-2-70b-chat (70b) and GPT-3.5 (GPT) could generate plausible medical vignettes, patient-geneticist dialogues and management plans for a hypothetical child and adult patients across 282 genetic conditions (selected by prevalence and categorized based on age-related characteristics). Results showed that LLMs provided appropriate age-based responses in both child and adult outputs based on Correctness and Completeness scores graded by clinicians. Sub-analysis of metabolic conditions including those typically presents neonatally with crisis also showed age-appropriate LLM responses. However 70b and GPT obtained low Correctness and Completeness scores at producing plausible management plans (55-66% for 70b and a wider range, 50-90%, for GPT). This suggests that LLMs still have some limitations in clinical applications.</p>","PeriodicalId":94160,"journal":{"name":"npj aging","volume":"11 1","pages":"33"},"PeriodicalIF":6.0000,"publicationDate":"2025-05-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12049513/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing large language model performance related to aging in genetic conditions.\",\"authors\":\"Amna A Othman, Kendall A Flaharty, Suzanna E Ledgister Hanchard, Ping Hu, Dat Duong, Rebekah L Waikel, Benjamin D Solomon\",\"doi\":\"10.1038/s41514-025-00226-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Most genetic conditions are described in pediatric populations, leaving a gap in understanding their clinical progression and management in adulthood. Motivated by other applications of large language models (LLMs), we evaluated whether Llama-2-70b-chat (70b) and GPT-3.5 (GPT) could generate plausible medical vignettes, patient-geneticist dialogues and management plans for a hypothetical child and adult patients across 282 genetic conditions (selected by prevalence and categorized based on age-related characteristics). Results showed that LLMs provided appropriate age-based responses in both child and adult outputs based on Correctness and Completeness scores graded by clinicians. Sub-analysis of metabolic conditions including those typically presents neonatally with crisis also showed age-appropriate LLM responses. However 70b and GPT obtained low Correctness and Completeness scores at producing plausible management plans (55-66% for 70b and a wider range, 50-90%, for GPT). This suggests that LLMs still have some limitations in clinical applications.</p>\",\"PeriodicalId\":94160,\"journal\":{\"name\":\"npj aging\",\"volume\":\"11 1\",\"pages\":\"33\"},\"PeriodicalIF\":6.0000,\"publicationDate\":\"2025-05-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12049513/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"npj aging\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1038/s41514-025-00226-z\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"GERIATRICS & GERONTOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"npj aging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s41514-025-00226-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"GERIATRICS & GERONTOLOGY","Score":null,"Total":0}
Assessing large language model performance related to aging in genetic conditions.
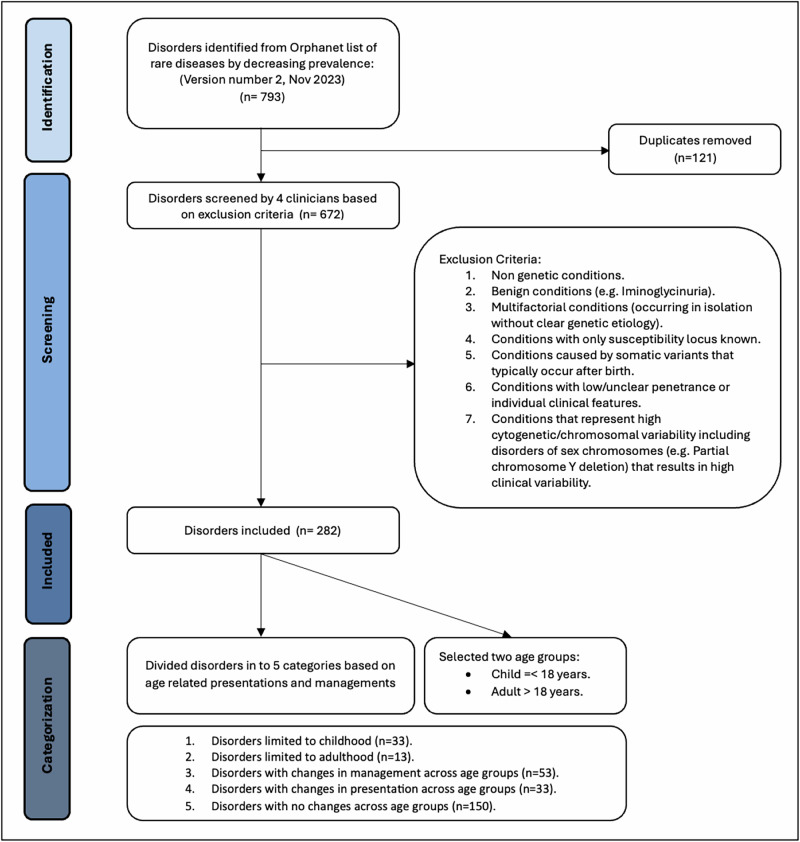
Most genetic conditions are described in pediatric populations, leaving a gap in understanding their clinical progression and management in adulthood. Motivated by other applications of large language models (LLMs), we evaluated whether Llama-2-70b-chat (70b) and GPT-3.5 (GPT) could generate plausible medical vignettes, patient-geneticist dialogues and management plans for a hypothetical child and adult patients across 282 genetic conditions (selected by prevalence and categorized based on age-related characteristics). Results showed that LLMs provided appropriate age-based responses in both child and adult outputs based on Correctness and Completeness scores graded by clinicians. Sub-analysis of metabolic conditions including those typically presents neonatally with crisis also showed age-appropriate LLM responses. However 70b and GPT obtained low Correctness and Completeness scores at producing plausible management plans (55-66% for 70b and a wider range, 50-90%, for GPT). This suggests that LLMs still have some limitations in clinical applications.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


