Anna P Maino, Jakub Klikowski, Brendan Strong, Wahid Ghaffari, Michał Woźniak, Tristan Bourcier, Andrzej Grzybowski
{"title":"人工智能与人类认知:ChatGPT和参加欧洲眼科文凭考试的考生的比较分析。","authors":"Anna P Maino, Jakub Klikowski, Brendan Strong, Wahid Ghaffari, Michał Woźniak, Tristan Bourcier, Andrzej Grzybowski","doi":"10.3390/vision9020031","DOIUrl":null,"url":null,"abstract":"<p><strong>Background/objectives: </strong>This paper aims to assess ChatGPT's performance in answering European Board of Ophthalmology Diploma (EBOD) examination papers and to compare these results to pass benchmarks and candidate results.</p><p><strong>Methods: </strong>This cross-sectional study used a sample of past exam papers from 2012, 2013, 2020-2023 EBOD examinations. This study analyzed ChatGPT's responses to 440 multiple choice questions (MCQs), each containing five true/false statements (2200 statements in total) and 48 single best answer (SBA) questions.</p><p><strong>Results: </strong>ChatGPT, for MCQs, scored on average 64.39%. ChatGPT's strongest metric performance for MCQs was precision (68.76%). ChatGPT performed best at answering pathology MCQs (Grubbs test <i>p</i> < 0.05). Optics and refraction had the lowest-scoring MCQ performance across all metrics. ChatGPT-3.5 Turbo performed worse than human candidates and ChatGPT-4o on easy questions (75% vs. 100% accuracy) but outperformed humans and ChatGPT-4o on challenging questions (50% vs. 28% accuracy). ChatGPT's SBA performance averaged 28.43%, with the highest score and strongest performance in precision (29.36%). Pathology SBA questions were consistently the lowest-scoring topic across most metrics. ChatGPT demonstrated a nonsignificant tendency to select option 1 more frequently (<i>p</i> = 0.19). When answering SBAs, human candidates scored higher than ChatGPT in all metric areas measured.</p><p><strong>Conclusions: </strong>ChatGPT performed stronger for true/false questions, scoring a pass mark in most instances. Performance was poorer for SBA questions, suggesting that ChatGPT's ability in information retrieval is better than that in knowledge integration. ChatGPT could become a valuable tool in ophthalmic education, allowing exam boards to test their exam papers to ensure they are pitched at the right level, marking open-ended questions and providing detailed feedback.</p>","PeriodicalId":36586,"journal":{"name":"Vision (Switzerland)","volume":"9 2","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2025-04-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12015923/pdf/","citationCount":"0","resultStr":"{\"title\":\"Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination.\",\"authors\":\"Anna P Maino, Jakub Klikowski, Brendan Strong, Wahid Ghaffari, Michał Woźniak, Tristan Bourcier, Andrzej Grzybowski\",\"doi\":\"10.3390/vision9020031\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background/objectives: </strong>This paper aims to assess ChatGPT's performance in answering European Board of Ophthalmology Diploma (EBOD) examination papers and to compare these results to pass benchmarks and candidate results.</p><p><strong>Methods: </strong>This cross-sectional study used a sample of past exam papers from 2012, 2013, 2020-2023 EBOD examinations. This study analyzed ChatGPT's responses to 440 multiple choice questions (MCQs), each containing five true/false statements (2200 statements in total) and 48 single best answer (SBA) questions.</p><p><strong>Results: </strong>ChatGPT, for MCQs, scored on average 64.39%. ChatGPT's strongest metric performance for MCQs was precision (68.76%). ChatGPT performed best at answering pathology MCQs (Grubbs test <i>p</i> < 0.05). Optics and refraction had the lowest-scoring MCQ performance across all metrics. ChatGPT-3.5 Turbo performed worse than human candidates and ChatGPT-4o on easy questions (75% vs. 100% accuracy) but outperformed humans and ChatGPT-4o on challenging questions (50% vs. 28% accuracy). ChatGPT's SBA performance averaged 28.43%, with the highest score and strongest performance in precision (29.36%). Pathology SBA questions were consistently the lowest-scoring topic across most metrics. ChatGPT demonstrated a nonsignificant tendency to select option 1 more frequently (<i>p</i> = 0.19). When answering SBAs, human candidates scored higher than ChatGPT in all metric areas measured.</p><p><strong>Conclusions: </strong>ChatGPT performed stronger for true/false questions, scoring a pass mark in most instances. Performance was poorer for SBA questions, suggesting that ChatGPT's ability in information retrieval is better than that in knowledge integration. ChatGPT could become a valuable tool in ophthalmic education, allowing exam boards to test their exam papers to ensure they are pitched at the right level, marking open-ended questions and providing detailed feedback.</p>\",\"PeriodicalId\":36586,\"journal\":{\"name\":\"Vision (Switzerland)\",\"volume\":\"9 2\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2025-04-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12015923/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Vision (Switzerland)\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/vision9020031\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Vision (Switzerland)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/vision9020031","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination.
Background/objectives: This paper aims to assess ChatGPT's performance in answering European Board of Ophthalmology Diploma (EBOD) examination papers and to compare these results to pass benchmarks and candidate results.
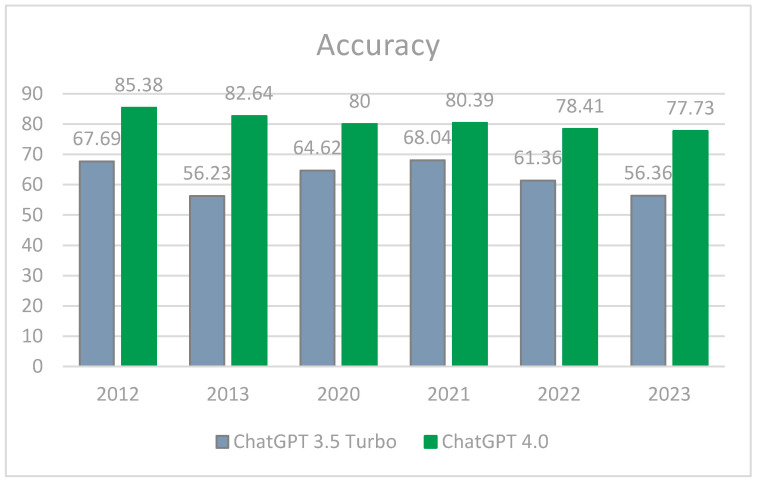
Methods: This cross-sectional study used a sample of past exam papers from 2012, 2013, 2020-2023 EBOD examinations. This study analyzed ChatGPT's responses to 440 multiple choice questions (MCQs), each containing five true/false statements (2200 statements in total) and 48 single best answer (SBA) questions.
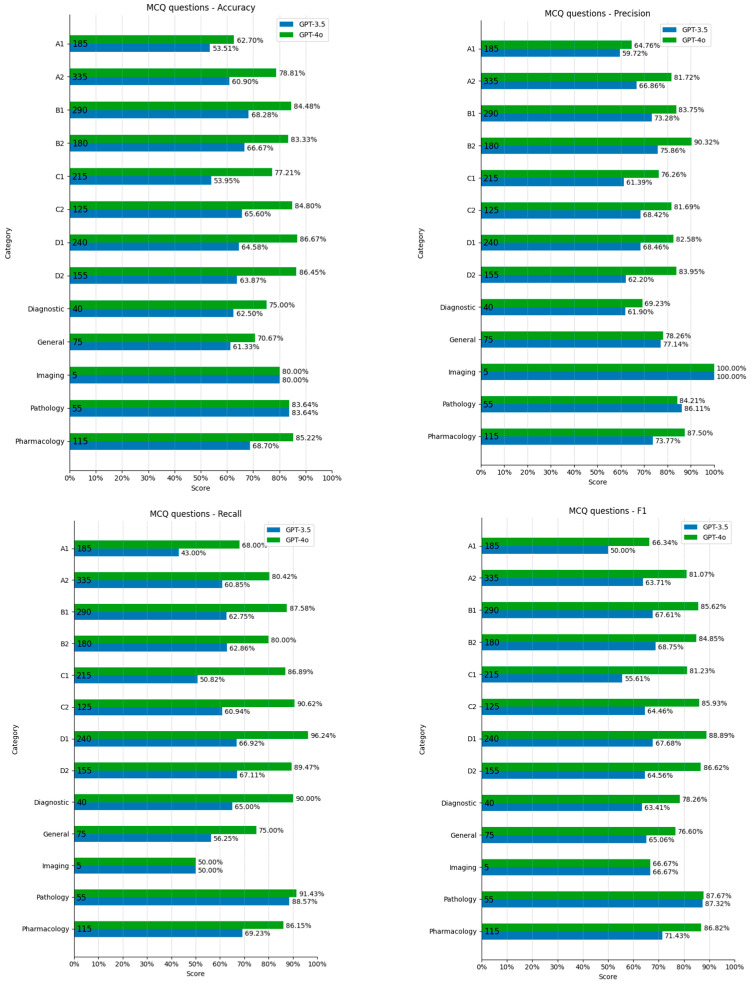
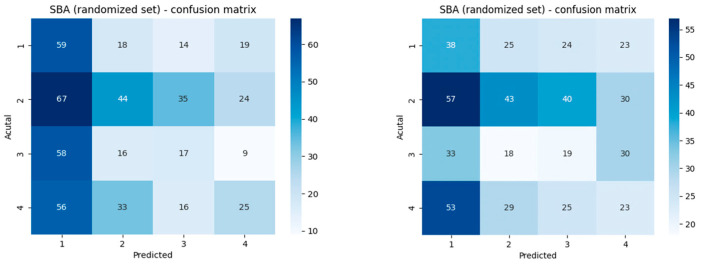
Results: ChatGPT, for MCQs, scored on average 64.39%. ChatGPT's strongest metric performance for MCQs was precision (68.76%). ChatGPT performed best at answering pathology MCQs (Grubbs test p < 0.05). Optics and refraction had the lowest-scoring MCQ performance across all metrics. ChatGPT-3.5 Turbo performed worse than human candidates and ChatGPT-4o on easy questions (75% vs. 100% accuracy) but outperformed humans and ChatGPT-4o on challenging questions (50% vs. 28% accuracy). ChatGPT's SBA performance averaged 28.43%, with the highest score and strongest performance in precision (29.36%). Pathology SBA questions were consistently the lowest-scoring topic across most metrics. ChatGPT demonstrated a nonsignificant tendency to select option 1 more frequently (p = 0.19). When answering SBAs, human candidates scored higher than ChatGPT in all metric areas measured.
Conclusions: ChatGPT performed stronger for true/false questions, scoring a pass mark in most instances. Performance was poorer for SBA questions, suggesting that ChatGPT's ability in information retrieval is better than that in knowledge integration. ChatGPT could become a valuable tool in ophthalmic education, allowing exam boards to test their exam papers to ensure they are pitched at the right level, marking open-ended questions and providing detailed feedback.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


