{"title":"评估中年健康问题回答的准确性和可读性:六个大型语言模型聊天机器人的比较分析。","authors":"Himel Mondal, Devendra Nath Tiu, Shaikat Mondal, Rajib Dutta, Avijit Naskar, Indrashis Podder","doi":"10.4103/jmh.jmh_182_24","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The use of large language model (LLM) chatbots in health-related queries is growing due to their convenience and accessibility. However, concerns about the accuracy and readability of their information persist. Many individuals, including patients and healthy adults, may rely on chatbots for midlife health queries instead of consulting a doctor. In this context, we evaluated the accuracy and readability of responses from six LLM chatbots to midlife health questions for men and women.</p><p><strong>Methods: </strong>Twenty questions on midlife health were asked to six different LLM chatbots - ChatGPT, Claude, Copilot, Gemini, Meta artificial intelligence (AI), and Perplexity. Each chatbot's responses were collected and evaluated for accuracy, relevancy, fluency, and coherence by three independent expert physicians. An overall score was also calculated by taking the average of four criteria. In addition, readability was analyzed using the Flesch-Kincaid Grade Level, to determine how easily the information could be understood by the general population.</p><p><strong>Results: </strong>In terms of fluency, Perplexity scored the highest (4.3 ± 1.78), coherence was highest for Meta AI (4.26 ± 0.16), accuracy of responses was highest for Meta AI, and relevancy score was highest for Meta AI (4.35 ± 0.24). Overall, Meta AI scored the highest (4.28 ± 0.16), followed by ChatGPT (4.22 ± 0.21), whereas Copilot had the lowest score (3.72 ± 0.19) (<i>P</i> < 0.0001). Perplexity showed the highest score of 41.24 ± 10.57 in readability and lowest in grade level (11.11 ± 1.93), meaning its text is the easiest to read and requires a lower level of education.</p><p><strong>Conclusion: </strong>LLM chatbots can answer midlife-related health questions with variable capabilities. Meta AI was found to be highest scoring chatbot for addressing men's and women's midlife health questions, whereas Perplexity offers high readability for accessible information. Hence, LLM chatbots can be used as educational tools for midlife health by selecting appropriate chatbots according to its capability.</p>","PeriodicalId":37717,"journal":{"name":"Journal of Mid-life Health","volume":"16 1","pages":"45-50"},"PeriodicalIF":1.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12052287/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating Accuracy and Readability of Responses to Midlife Health Questions: A Comparative Analysis of Six Large Language Model Chatbots.\",\"authors\":\"Himel Mondal, Devendra Nath Tiu, Shaikat Mondal, Rajib Dutta, Avijit Naskar, Indrashis Podder\",\"doi\":\"10.4103/jmh.jmh_182_24\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The use of large language model (LLM) chatbots in health-related queries is growing due to their convenience and accessibility. However, concerns about the accuracy and readability of their information persist. Many individuals, including patients and healthy adults, may rely on chatbots for midlife health queries instead of consulting a doctor. In this context, we evaluated the accuracy and readability of responses from six LLM chatbots to midlife health questions for men and women.</p><p><strong>Methods: </strong>Twenty questions on midlife health were asked to six different LLM chatbots - ChatGPT, Claude, Copilot, Gemini, Meta artificial intelligence (AI), and Perplexity. Each chatbot's responses were collected and evaluated for accuracy, relevancy, fluency, and coherence by three independent expert physicians. An overall score was also calculated by taking the average of four criteria. In addition, readability was analyzed using the Flesch-Kincaid Grade Level, to determine how easily the information could be understood by the general population.</p><p><strong>Results: </strong>In terms of fluency, Perplexity scored the highest (4.3 ± 1.78), coherence was highest for Meta AI (4.26 ± 0.16), accuracy of responses was highest for Meta AI, and relevancy score was highest for Meta AI (4.35 ± 0.24). Overall, Meta AI scored the highest (4.28 ± 0.16), followed by ChatGPT (4.22 ± 0.21), whereas Copilot had the lowest score (3.72 ± 0.19) (<i>P</i> < 0.0001). Perplexity showed the highest score of 41.24 ± 10.57 in readability and lowest in grade level (11.11 ± 1.93), meaning its text is the easiest to read and requires a lower level of education.</p><p><strong>Conclusion: </strong>LLM chatbots can answer midlife-related health questions with variable capabilities. Meta AI was found to be highest scoring chatbot for addressing men's and women's midlife health questions, whereas Perplexity offers high readability for accessible information. Hence, LLM chatbots can be used as educational tools for midlife health by selecting appropriate chatbots according to its capability.</p>\",\"PeriodicalId\":37717,\"journal\":{\"name\":\"Journal of Mid-life Health\",\"volume\":\"16 1\",\"pages\":\"45-50\"},\"PeriodicalIF\":1.0000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12052287/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Mid-life Health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4103/jmh.jmh_182_24\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"OBSTETRICS & GYNECOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Mid-life Health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4103/jmh.jmh_182_24","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/5 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"OBSTETRICS & GYNECOLOGY","Score":null,"Total":0}
Evaluating Accuracy and Readability of Responses to Midlife Health Questions: A Comparative Analysis of Six Large Language Model Chatbots.
Background: The use of large language model (LLM) chatbots in health-related queries is growing due to their convenience and accessibility. However, concerns about the accuracy and readability of their information persist. Many individuals, including patients and healthy adults, may rely on chatbots for midlife health queries instead of consulting a doctor. In this context, we evaluated the accuracy and readability of responses from six LLM chatbots to midlife health questions for men and women.
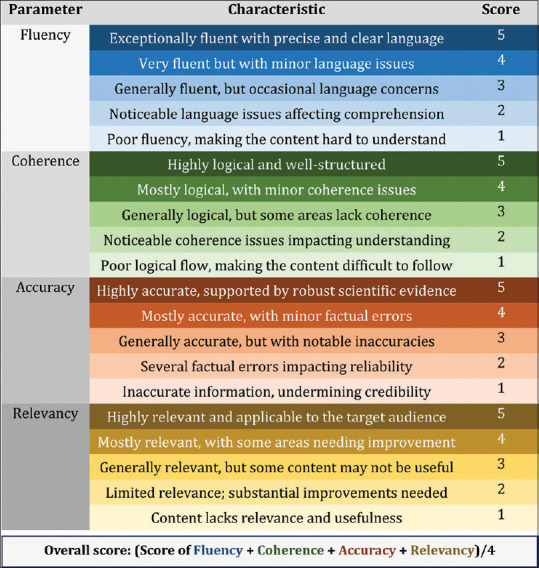
Methods: Twenty questions on midlife health were asked to six different LLM chatbots - ChatGPT, Claude, Copilot, Gemini, Meta artificial intelligence (AI), and Perplexity. Each chatbot's responses were collected and evaluated for accuracy, relevancy, fluency, and coherence by three independent expert physicians. An overall score was also calculated by taking the average of four criteria. In addition, readability was analyzed using the Flesch-Kincaid Grade Level, to determine how easily the information could be understood by the general population.
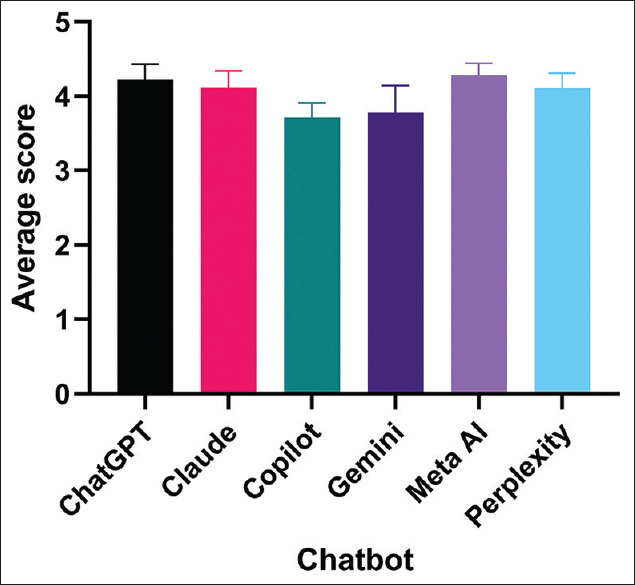
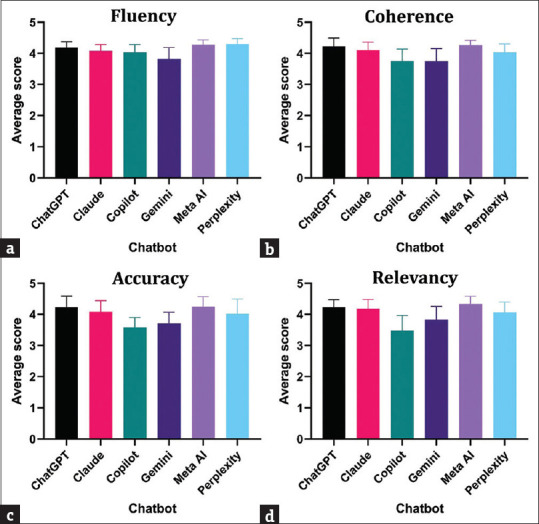
Results: In terms of fluency, Perplexity scored the highest (4.3 ± 1.78), coherence was highest for Meta AI (4.26 ± 0.16), accuracy of responses was highest for Meta AI, and relevancy score was highest for Meta AI (4.35 ± 0.24). Overall, Meta AI scored the highest (4.28 ± 0.16), followed by ChatGPT (4.22 ± 0.21), whereas Copilot had the lowest score (3.72 ± 0.19) (P < 0.0001). Perplexity showed the highest score of 41.24 ± 10.57 in readability and lowest in grade level (11.11 ± 1.93), meaning its text is the easiest to read and requires a lower level of education.
Conclusion: LLM chatbots can answer midlife-related health questions with variable capabilities. Meta AI was found to be highest scoring chatbot for addressing men's and women's midlife health questions, whereas Perplexity offers high readability for accessible information. Hence, LLM chatbots can be used as educational tools for midlife health by selecting appropriate chatbots according to its capability.
期刊介绍:
Journal of mid-life health is the official journal of the Indian Menopause society published Quarterly in January, April, July and October. It is peer reviewed, scientific journal of mid-life health and its problems. It includes all aspects of mid-life health, preventive as well as curative. The journal publishes on subjects such as gynecology, neurology, geriatrics, psychiatry, endocrinology, urology, andrology, psychology, healthy ageing, cardiovascular health, bone health, quality of life etc. as relevant of men and women in their midlife. The Journal provides a visible platform to the researchers as well as clinicians to publish their experiences in this area thereby helping in the promotion of mid-life health leading to healthy ageing, growing need due to increasing life expectancy. The Editorial team has maintained high standards and published original research papers, case reports and review articles from the best of the best contributors both national & international, consistently so that now, it has become a great tool in the hands of menopause practitioners.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


