{"title":"人工智能促进了聊天机器人的繁荣:一项评估临床麻醉学辅助的单中心观察研究。","authors":"Sowmya M Jois, Srinivasan Rangalakshmi, Sowmya Madihalli Janardhan Iyengar, Chethana Mahesh, Lairenjam Deepa Devi, Arun Kumar Namachivayam","doi":"10.4103/joacp.joacp_151_24","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and aims: </strong>The field of anaesthesiology and perioperative medicine has explored advancements in science and technology, ensuring precision and personalized anesthesia plans. The surge in the usage of chat-generative pretrained transformer (Chat GPT) in medicine has evoked interest among anesthesiologists to assess its performance in the operating room. However, there is concern about accuracy, patient privacy and ethics. Our objective in this study assess whether Chat GPT can provide assistance in clinical decisions and compare them with those of resident anesthesiologists.</p><p><strong>Material and methods: </strong>In this cross-sectional study conducted at a teaching hospital, a set of 30 hypothetical clinical scenarios in the operating room were presented to resident anesthesiologists and Chat-GPT 4. The first five scenarios out of 30 were typed with three additional prompts in the same chat to determine if there was any detailing of answers. The responses were labeled and assessed by three reviewers not involved in the study.</p><p><strong>Results: </strong>The interclass coefficient (ICC) values show variation in the level of agreement between Chat GPT and anesthesiologists. For instance, the ICC of 0.41 between A1 and Chat GPT indicates a moderate level of agreement, whereas the ICC of 0.06 between A2 and Chat GPT suggests a comparatively weaker level of agreement.</p><p><strong>Conclusions: </strong>In this study, it was found that there were variations in the level of agreement between Chat GPT and resident anesthesiologists' response in terms of accuracy and comprehensiveness of responses in solving intraoperative scenarios. The use of prompts improved the agreement of Chat GPT with anesthesiologists.</p>","PeriodicalId":14946,"journal":{"name":"Journal of Anaesthesiology, Clinical Pharmacology","volume":"41 2","pages":"351-356"},"PeriodicalIF":1.1000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12002681/pdf/","citationCount":"0","resultStr":"{\"title\":\"Artificial intelligence enhanced Chatbot boom: A single center observational study to evaluate assistance in clinical anesthesiology.\",\"authors\":\"Sowmya M Jois, Srinivasan Rangalakshmi, Sowmya Madihalli Janardhan Iyengar, Chethana Mahesh, Lairenjam Deepa Devi, Arun Kumar Namachivayam\",\"doi\":\"10.4103/joacp.joacp_151_24\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background and aims: </strong>The field of anaesthesiology and perioperative medicine has explored advancements in science and technology, ensuring precision and personalized anesthesia plans. The surge in the usage of chat-generative pretrained transformer (Chat GPT) in medicine has evoked interest among anesthesiologists to assess its performance in the operating room. However, there is concern about accuracy, patient privacy and ethics. Our objective in this study assess whether Chat GPT can provide assistance in clinical decisions and compare them with those of resident anesthesiologists.</p><p><strong>Material and methods: </strong>In this cross-sectional study conducted at a teaching hospital, a set of 30 hypothetical clinical scenarios in the operating room were presented to resident anesthesiologists and Chat-GPT 4. The first five scenarios out of 30 were typed with three additional prompts in the same chat to determine if there was any detailing of answers. The responses were labeled and assessed by three reviewers not involved in the study.</p><p><strong>Results: </strong>The interclass coefficient (ICC) values show variation in the level of agreement between Chat GPT and anesthesiologists. For instance, the ICC of 0.41 between A1 and Chat GPT indicates a moderate level of agreement, whereas the ICC of 0.06 between A2 and Chat GPT suggests a comparatively weaker level of agreement.</p><p><strong>Conclusions: </strong>In this study, it was found that there were variations in the level of agreement between Chat GPT and resident anesthesiologists' response in terms of accuracy and comprehensiveness of responses in solving intraoperative scenarios. The use of prompts improved the agreement of Chat GPT with anesthesiologists.</p>\",\"PeriodicalId\":14946,\"journal\":{\"name\":\"Journal of Anaesthesiology, Clinical Pharmacology\",\"volume\":\"41 2\",\"pages\":\"351-356\"},\"PeriodicalIF\":1.1000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12002681/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Anaesthesiology, Clinical Pharmacology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4103/joacp.joacp_151_24\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/3/24 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"PHARMACOLOGY & PHARMACY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Anaesthesiology, Clinical Pharmacology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4103/joacp.joacp_151_24","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/3/24 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
Artificial intelligence enhanced Chatbot boom: A single center observational study to evaluate assistance in clinical anesthesiology.
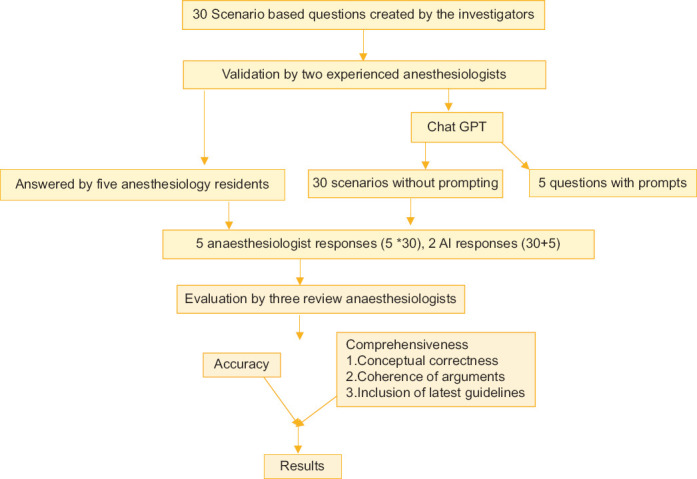
Background and aims: The field of anaesthesiology and perioperative medicine has explored advancements in science and technology, ensuring precision and personalized anesthesia plans. The surge in the usage of chat-generative pretrained transformer (Chat GPT) in medicine has evoked interest among anesthesiologists to assess its performance in the operating room. However, there is concern about accuracy, patient privacy and ethics. Our objective in this study assess whether Chat GPT can provide assistance in clinical decisions and compare them with those of resident anesthesiologists.
Material and methods: In this cross-sectional study conducted at a teaching hospital, a set of 30 hypothetical clinical scenarios in the operating room were presented to resident anesthesiologists and Chat-GPT 4. The first five scenarios out of 30 were typed with three additional prompts in the same chat to determine if there was any detailing of answers. The responses were labeled and assessed by three reviewers not involved in the study.
Results: The interclass coefficient (ICC) values show variation in the level of agreement between Chat GPT and anesthesiologists. For instance, the ICC of 0.41 between A1 and Chat GPT indicates a moderate level of agreement, whereas the ICC of 0.06 between A2 and Chat GPT suggests a comparatively weaker level of agreement.
Conclusions: In this study, it was found that there were variations in the level of agreement between Chat GPT and resident anesthesiologists' response in terms of accuracy and comprehensiveness of responses in solving intraoperative scenarios. The use of prompts improved the agreement of Chat GPT with anesthesiologists.
期刊介绍:
The JOACP publishes original peer-reviewed research and clinical work in all branches of anaesthesiology, pain, critical care and perioperative medicine including the application to basic sciences. In addition, the journal publishes review articles, special articles, brief communications/reports, case reports, and reports of new equipment, letters to editor, book reviews and obituaries. It is international in scope and comprehensive in coverage.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


