Hokun Kim, Bohyun Kim, Moon Hyung Choi, Joon-Il Choi, Soon Nam Oh, Sung Eun Rha
{"title":"使用GPT-4将胰腺癌混合语言自由文本CT报告转换为国家综合癌症网络结构化报告模板。","authors":"Hokun Kim, Bohyun Kim, Moon Hyung Choi, Joon-Il Choi, Soon Nam Oh, Sung Eun Rha","doi":"10.3348/kjr.2024.1228","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To evaluate the feasibility of generative pre-trained transformer-4 (GPT-4) in generating structured reports (SRs) from mixed-language (English and Korean) narrative-style CT reports for pancreatic ductal adenocarcinoma (PDAC) and to assess its accuracy in categorizing PDCA resectability.</p><p><strong>Materials and methods: </strong>This retrospective study included consecutive free-text reports of pancreas-protocol CT for staging PDAC, from two institutions, written in English or Korean from January 2021 to December 2023. Both the GPT-4 Turbo and GPT-4o models were provided prompts along with the free-text reports via an application programming interface and tasked with generating SRs and categorizing tumor resectability according to the National Comprehensive Cancer Network guidelines version 2.2024. Prompts were optimized using the GPT-4 Turbo model and 50 reports from Institution B. The performances of the GPT-4 Turbo and GPT-4o models in the two tasks were evaluated using 115 reports from Institution A. Results were compared with a reference standard that was manually derived by an abdominal radiologist. Each report was consecutively processed three times, with the most frequent response selected as the final output. Error analysis was guided by the decision rationale provided by the models.</p><p><strong>Results: </strong>Of the 115 narrative reports tested, 96 (83.5%) contained both English and Korean. For SR generation, GPT-4 Turbo and GPT-4o demonstrated comparable accuracies (92.3% [1592/1725] and 92.2% [1590/1725], respectively; <i>P</i> = 0.923). In the resectability categorization, GPT-4 Turbo showed higher accuracy than GPT-4o (81.7% [94/115] vs. 67.0% [77/115], respectively; <i>P</i> = 0.002). In the error analysis of GPT-4 Turbo, the SR generation error rate was 7.7% (133/1725 items), which was primarily attributed to inaccurate data extraction (54.1% [72/133]). The resectability categorization error rate was 18.3% (21/115), with the main cause being violation of the resectability criteria (61.9% [13/21]).</p><p><strong>Conclusion: </strong>Both GPT-4 Turbo and GPT-4o demonstrated acceptable accuracy in generating NCCN-based SRs on PDACs from mixed-language narrative reports. However, oversight by human radiologists is essential for determining resectability based on CT findings.</p>","PeriodicalId":17881,"journal":{"name":"Korean Journal of Radiology","volume":" ","pages":"557-568"},"PeriodicalIF":5.3000,"publicationDate":"2025-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12123081/pdf/","citationCount":"0","resultStr":"{\"title\":\"Conversion of Mixed-Language Free-Text CT Reports of Pancreatic Cancer to National Comprehensive Cancer Network Structured Reporting Templates by Using GPT-4.\",\"authors\":\"Hokun Kim, Bohyun Kim, Moon Hyung Choi, Joon-Il Choi, Soon Nam Oh, Sung Eun Rha\",\"doi\":\"10.3348/kjr.2024.1228\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>To evaluate the feasibility of generative pre-trained transformer-4 (GPT-4) in generating structured reports (SRs) from mixed-language (English and Korean) narrative-style CT reports for pancreatic ductal adenocarcinoma (PDAC) and to assess its accuracy in categorizing PDCA resectability.</p><p><strong>Materials and methods: </strong>This retrospective study included consecutive free-text reports of pancreas-protocol CT for staging PDAC, from two institutions, written in English or Korean from January 2021 to December 2023. Both the GPT-4 Turbo and GPT-4o models were provided prompts along with the free-text reports via an application programming interface and tasked with generating SRs and categorizing tumor resectability according to the National Comprehensive Cancer Network guidelines version 2.2024. Prompts were optimized using the GPT-4 Turbo model and 50 reports from Institution B. The performances of the GPT-4 Turbo and GPT-4o models in the two tasks were evaluated using 115 reports from Institution A. Results were compared with a reference standard that was manually derived by an abdominal radiologist. Each report was consecutively processed three times, with the most frequent response selected as the final output. Error analysis was guided by the decision rationale provided by the models.</p><p><strong>Results: </strong>Of the 115 narrative reports tested, 96 (83.5%) contained both English and Korean. For SR generation, GPT-4 Turbo and GPT-4o demonstrated comparable accuracies (92.3% [1592/1725] and 92.2% [1590/1725], respectively; <i>P</i> = 0.923). In the resectability categorization, GPT-4 Turbo showed higher accuracy than GPT-4o (81.7% [94/115] vs. 67.0% [77/115], respectively; <i>P</i> = 0.002). In the error analysis of GPT-4 Turbo, the SR generation error rate was 7.7% (133/1725 items), which was primarily attributed to inaccurate data extraction (54.1% [72/133]). The resectability categorization error rate was 18.3% (21/115), with the main cause being violation of the resectability criteria (61.9% [13/21]).</p><p><strong>Conclusion: </strong>Both GPT-4 Turbo and GPT-4o demonstrated acceptable accuracy in generating NCCN-based SRs on PDACs from mixed-language narrative reports. However, oversight by human radiologists is essential for determining resectability based on CT findings.</p>\",\"PeriodicalId\":17881,\"journal\":{\"name\":\"Korean Journal of Radiology\",\"volume\":\" \",\"pages\":\"557-568\"},\"PeriodicalIF\":5.3000,\"publicationDate\":\"2025-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12123081/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Korean Journal of Radiology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3348/kjr.2024.1228\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/17 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Korean Journal of Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3348/kjr.2024.1228","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/17 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
Conversion of Mixed-Language Free-Text CT Reports of Pancreatic Cancer to National Comprehensive Cancer Network Structured Reporting Templates by Using GPT-4.
Objective: To evaluate the feasibility of generative pre-trained transformer-4 (GPT-4) in generating structured reports (SRs) from mixed-language (English and Korean) narrative-style CT reports for pancreatic ductal adenocarcinoma (PDAC) and to assess its accuracy in categorizing PDCA resectability.
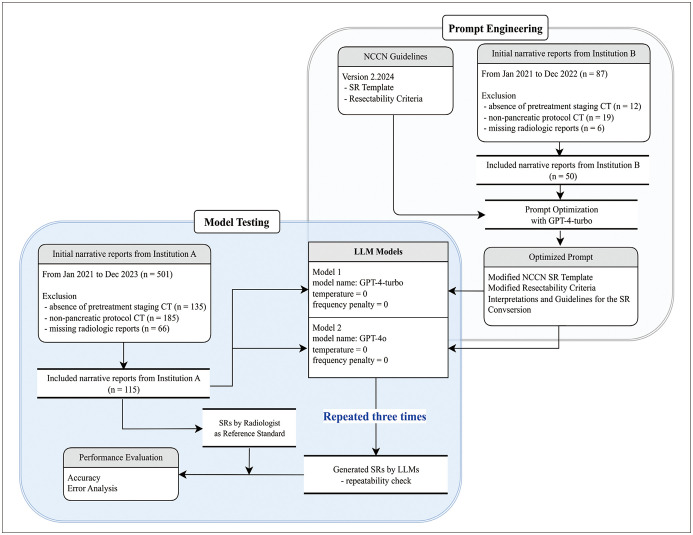
Materials and methods: This retrospective study included consecutive free-text reports of pancreas-protocol CT for staging PDAC, from two institutions, written in English or Korean from January 2021 to December 2023. Both the GPT-4 Turbo and GPT-4o models were provided prompts along with the free-text reports via an application programming interface and tasked with generating SRs and categorizing tumor resectability according to the National Comprehensive Cancer Network guidelines version 2.2024. Prompts were optimized using the GPT-4 Turbo model and 50 reports from Institution B. The performances of the GPT-4 Turbo and GPT-4o models in the two tasks were evaluated using 115 reports from Institution A. Results were compared with a reference standard that was manually derived by an abdominal radiologist. Each report was consecutively processed three times, with the most frequent response selected as the final output. Error analysis was guided by the decision rationale provided by the models.
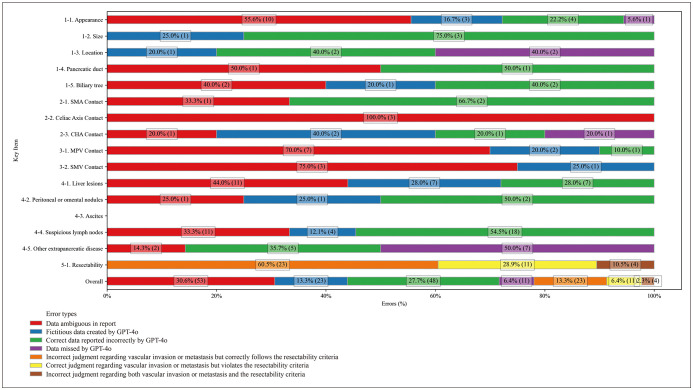
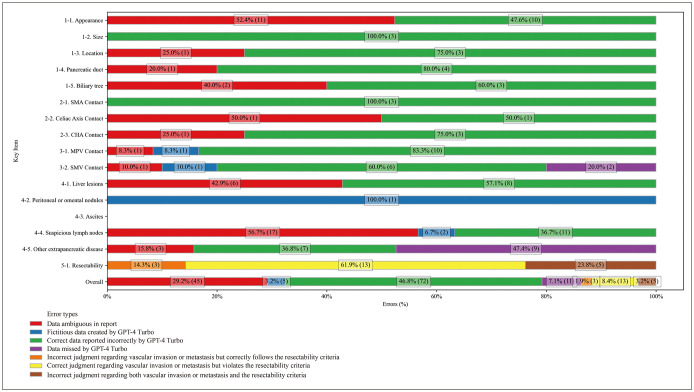
Results: Of the 115 narrative reports tested, 96 (83.5%) contained both English and Korean. For SR generation, GPT-4 Turbo and GPT-4o demonstrated comparable accuracies (92.3% [1592/1725] and 92.2% [1590/1725], respectively; P = 0.923). In the resectability categorization, GPT-4 Turbo showed higher accuracy than GPT-4o (81.7% [94/115] vs. 67.0% [77/115], respectively; P = 0.002). In the error analysis of GPT-4 Turbo, the SR generation error rate was 7.7% (133/1725 items), which was primarily attributed to inaccurate data extraction (54.1% [72/133]). The resectability categorization error rate was 18.3% (21/115), with the main cause being violation of the resectability criteria (61.9% [13/21]).
Conclusion: Both GPT-4 Turbo and GPT-4o demonstrated acceptable accuracy in generating NCCN-based SRs on PDACs from mixed-language narrative reports. However, oversight by human radiologists is essential for determining resectability based on CT findings.
期刊介绍:
The inaugural issue of the Korean J Radiol came out in March 2000. Our journal aims to produce and propagate knowledge on radiologic imaging and related sciences.
A unique feature of the articles published in the Journal will be their reflection of global trends in radiology combined with an East-Asian perspective. Geographic differences in disease prevalence will be reflected in the contents of papers, and this will serve to enrich our body of knowledge.
World''s outstanding radiologists from many countries are serving as editorial board of our journal.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


