Usman Iqbal, Afifa Tanweer, Annisa Ristya Rahmanti, David Greenfield, Leon Tsung-Ju Lee, Yu-Chuan Jack Li
{"title":"大语言模型(ChatGPT)在医疗保健中的影响:概括性回顾和证据综合。","authors":"Usman Iqbal, Afifa Tanweer, Annisa Ristya Rahmanti, David Greenfield, Leon Tsung-Ju Lee, Yu-Chuan Jack Li","doi":"10.1186/s12929-025-01131-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The emergence of Artificial Intelligence (AI), particularly Chat Generative Pre-Trained Transformer (ChatGPT), a Large Language Model (LLM), in healthcare promises to reshape patient care, clinical decision-making, and medical education. This review aims to synthesise research findings to consolidate the implications of ChatGPT integration in healthcare and identify research gaps.</p><p><strong>Main body: </strong>The umbrella review was conducted following Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. The Cochrane Library, PubMed, Scopus, Web of Science, and Google Scholar were searched from inception until February 2024. Due to the heterogeneity of the included studies, no quantitative analysis was performed. Instead, information was extracted, summarised, synthesised, and presented in a narrative form. Two reviewers undertook title, abstract, and full text screening independently. The methodological quality and overall rating of the included reviews were assessed using the A Measurement Tool to Assess systematic Reviews (AMSTAR-2) checklist. The review examined 17 studies, comprising 15 systematic reviews and 2 meta-analyses, on ChatGPT in healthcare, revealing diverse focuses. The AMSTAR-2 assessment identified 5 moderate and 12 low-quality reviews, with deficiencies like study design justification and funding source reporting. The most reported theme that emerged was ChatGPT's use in disease diagnosis or clinical decision-making. While 82.4% of studies focused on its general usage, 17.6% explored unique topics like its role in medical examinations and conducting systematic reviews. Among these, 52.9% targeted general healthcare, with 41.2% focusing on specific domains like radiology, neurosurgery, gastroenterology, public health dentistry, and ophthalmology. ChatGPT's use for manuscript review or writing was mentioned in 17.6% of reviews. Promising applications include enhancing patient care and clinical decision-making, though ethical, legal, and accuracy concerns require cautious integration.</p><p><strong>Conclusion: </strong>We summarise the identified areas in reviews regarding ChatGPT's transformative impact in healthcare, highlighting patient care, decision-making, and medical education. Emphasising the importance of ethical regulations and the involvement of policymakers, we urge further investigation to ensure the reliability of ChatGPT and to promote trust in healthcare and research.</p>","PeriodicalId":15365,"journal":{"name":"Journal of Biomedical Science","volume":"32 1","pages":"45"},"PeriodicalIF":12.1000,"publicationDate":"2025-05-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12057020/pdf/","citationCount":"0","resultStr":"{\"title\":\"Impact of large language model (ChatGPT) in healthcare: an umbrella review and evidence synthesis.\",\"authors\":\"Usman Iqbal, Afifa Tanweer, Annisa Ristya Rahmanti, David Greenfield, Leon Tsung-Ju Lee, Yu-Chuan Jack Li\",\"doi\":\"10.1186/s12929-025-01131-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The emergence of Artificial Intelligence (AI), particularly Chat Generative Pre-Trained Transformer (ChatGPT), a Large Language Model (LLM), in healthcare promises to reshape patient care, clinical decision-making, and medical education. This review aims to synthesise research findings to consolidate the implications of ChatGPT integration in healthcare and identify research gaps.</p><p><strong>Main body: </strong>The umbrella review was conducted following Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. The Cochrane Library, PubMed, Scopus, Web of Science, and Google Scholar were searched from inception until February 2024. Due to the heterogeneity of the included studies, no quantitative analysis was performed. Instead, information was extracted, summarised, synthesised, and presented in a narrative form. Two reviewers undertook title, abstract, and full text screening independently. The methodological quality and overall rating of the included reviews were assessed using the A Measurement Tool to Assess systematic Reviews (AMSTAR-2) checklist. The review examined 17 studies, comprising 15 systematic reviews and 2 meta-analyses, on ChatGPT in healthcare, revealing diverse focuses. The AMSTAR-2 assessment identified 5 moderate and 12 low-quality reviews, with deficiencies like study design justification and funding source reporting. The most reported theme that emerged was ChatGPT's use in disease diagnosis or clinical decision-making. While 82.4% of studies focused on its general usage, 17.6% explored unique topics like its role in medical examinations and conducting systematic reviews. Among these, 52.9% targeted general healthcare, with 41.2% focusing on specific domains like radiology, neurosurgery, gastroenterology, public health dentistry, and ophthalmology. ChatGPT's use for manuscript review or writing was mentioned in 17.6% of reviews. Promising applications include enhancing patient care and clinical decision-making, though ethical, legal, and accuracy concerns require cautious integration.</p><p><strong>Conclusion: </strong>We summarise the identified areas in reviews regarding ChatGPT's transformative impact in healthcare, highlighting patient care, decision-making, and medical education. Emphasising the importance of ethical regulations and the involvement of policymakers, we urge further investigation to ensure the reliability of ChatGPT and to promote trust in healthcare and research.</p>\",\"PeriodicalId\":15365,\"journal\":{\"name\":\"Journal of Biomedical Science\",\"volume\":\"32 1\",\"pages\":\"45\"},\"PeriodicalIF\":12.1000,\"publicationDate\":\"2025-05-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12057020/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Science\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1186/s12929-025-01131-z\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CELL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Science","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12929-025-01131-z","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CELL BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
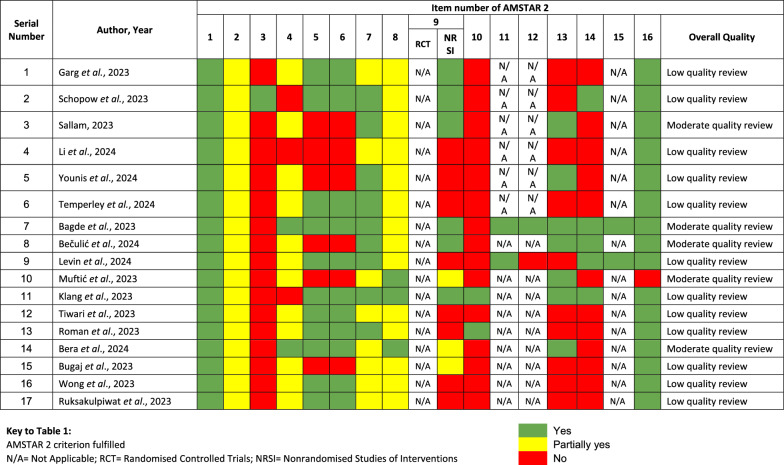
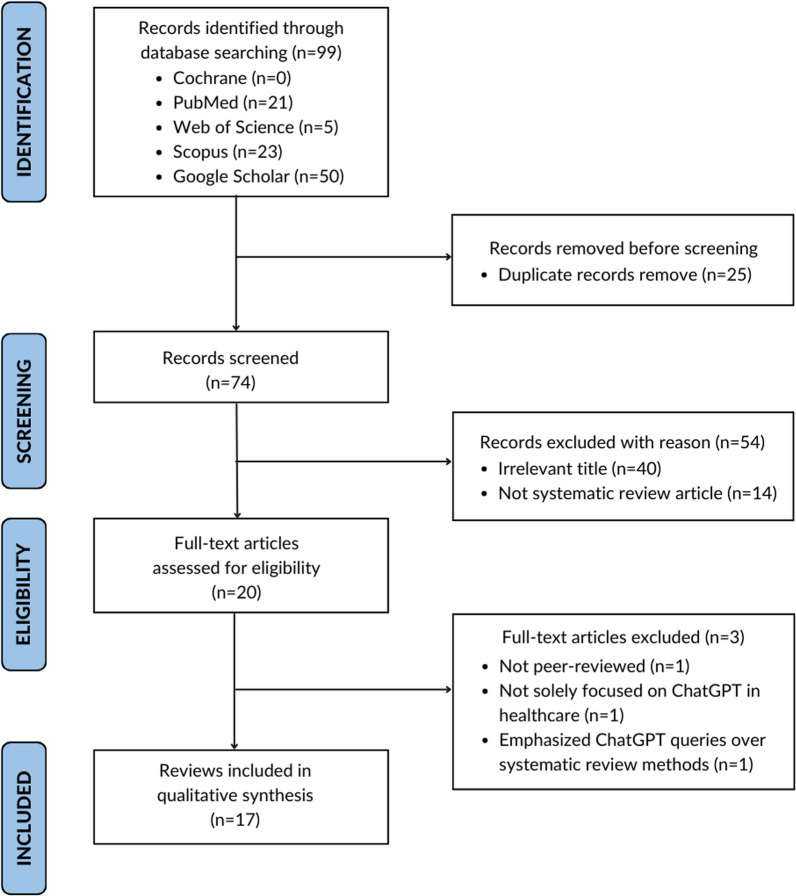
背景:人工智能(AI)的出现,特别是聊天生成预训练变压器(ChatGPT),一种大型语言模型(LLM),在医疗保健领域有望重塑患者护理,临床决策和医学教育。本综述旨在综合研究成果,以巩固ChatGPT整合在医疗保健中的意义,并确定研究差距。主体:总括性评价是按照系统评价和荟萃分析(PRISMA)指南的首选报告项目进行的。Cochrane Library, PubMed, Scopus, Web of Science和谷歌Scholar从成立到2024年2月进行了搜索。由于纳入研究的异质性,未进行定量分析。相反,信息被提取、总结、综合,并以叙述的形式呈现。两位审稿人独立进行了标题、摘要和全文筛选。使用评估系统评价的测量工具(AMSTAR-2)检查表对纳入的评价的方法学质量和总体评级进行评估。该综述审查了17项研究,包括15项系统综述和2项荟萃分析,揭示了ChatGPT在医疗保健中的不同关注点。AMSTAR-2评估确定了5个中等质量评价和12个低质量评价,存在研究设计论证和资金来源报告等缺陷。报道最多的主题是ChatGPT在疾病诊断或临床决策中的应用。82.4%的研究集中在它的一般用法上,17.6%的研究探讨了它在医学检查和进行系统评价中的作用等独特主题。其中,52.9%针对普通医疗保健,41.2%关注特定领域,如放射学、神经外科、胃肠病学、公共卫生牙科和眼科。在17.6%的评论中提到了ChatGPT用于手稿审查或写作。有前景的应用包括加强病人护理和临床决策,尽管伦理、法律和准确性方面的考虑需要谨慎整合。结论:我们总结了ChatGPT在医疗保健领域的变革性影响,重点是患者护理、决策和医学教育。强调道德规范和政策制定者参与的重要性,我们敦促进一步调查,以确保ChatGPT的可靠性,并促进对医疗保健和研究的信任。
Impact of large language model (ChatGPT) in healthcare: an umbrella review and evidence synthesis.
Background: The emergence of Artificial Intelligence (AI), particularly Chat Generative Pre-Trained Transformer (ChatGPT), a Large Language Model (LLM), in healthcare promises to reshape patient care, clinical decision-making, and medical education. This review aims to synthesise research findings to consolidate the implications of ChatGPT integration in healthcare and identify research gaps.
Main body: The umbrella review was conducted following Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. The Cochrane Library, PubMed, Scopus, Web of Science, and Google Scholar were searched from inception until February 2024. Due to the heterogeneity of the included studies, no quantitative analysis was performed. Instead, information was extracted, summarised, synthesised, and presented in a narrative form. Two reviewers undertook title, abstract, and full text screening independently. The methodological quality and overall rating of the included reviews were assessed using the A Measurement Tool to Assess systematic Reviews (AMSTAR-2) checklist. The review examined 17 studies, comprising 15 systematic reviews and 2 meta-analyses, on ChatGPT in healthcare, revealing diverse focuses. The AMSTAR-2 assessment identified 5 moderate and 12 low-quality reviews, with deficiencies like study design justification and funding source reporting. The most reported theme that emerged was ChatGPT's use in disease diagnosis or clinical decision-making. While 82.4% of studies focused on its general usage, 17.6% explored unique topics like its role in medical examinations and conducting systematic reviews. Among these, 52.9% targeted general healthcare, with 41.2% focusing on specific domains like radiology, neurosurgery, gastroenterology, public health dentistry, and ophthalmology. ChatGPT's use for manuscript review or writing was mentioned in 17.6% of reviews. Promising applications include enhancing patient care and clinical decision-making, though ethical, legal, and accuracy concerns require cautious integration.
Conclusion: We summarise the identified areas in reviews regarding ChatGPT's transformative impact in healthcare, highlighting patient care, decision-making, and medical education. Emphasising the importance of ethical regulations and the involvement of policymakers, we urge further investigation to ensure the reliability of ChatGPT and to promote trust in healthcare and research.
期刊介绍:
The Journal of Biomedical Science is an open access, peer-reviewed journal that focuses on fundamental and molecular aspects of basic medical sciences. It emphasizes molecular studies of biomedical problems and mechanisms. The National Science and Technology Council (NSTC), Taiwan supports the journal and covers the publication costs for accepted articles. The journal aims to provide an international platform for interdisciplinary discussions and contribute to the advancement of medicine. It benefits both readers and authors by accelerating the dissemination of research information and providing maximum access to scholarly communication. All articles published in the Journal of Biomedical Science are included in various databases such as Biological Abstracts, BIOSIS, CABI, CAS, Citebase, Current contents, DOAJ, Embase, EmBiology, and Global Health, among others.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


