Mor Saban, Yaniv Alon, Osnat Luxenburg, Clara Singer, Monika Hierath, Alexandra Karoussou Schreiner, Boris Brkljačić, Jacob Sosna
{"title":"在一个大型欧洲队列中使用临床决策支持和大型语言模型的CT转诊论证比较。","authors":"Mor Saban, Yaniv Alon, Osnat Luxenburg, Clara Singer, Monika Hierath, Alexandra Karoussou Schreiner, Boris Brkljačić, Jacob Sosna","doi":"10.1007/s00330-025-11608-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Ensuring appropriate use of CT scans is critical for patient safety and resource optimization. Decision support tools and artificial intelligence (AI), such as large language models (LLMs), have the potential to improve CT referral justification, yet require rigorous evaluation against established standards and expert assessments.</p><p><strong>Aim: </strong>To evaluate the performance of LLMs (Generation Pre-trained Transformer 4 (GPT-4) and Claude-3 Haiku) and independent experts in justifying CT referrals compared to the ESR iGuide clinical decision support system as the reference standard.</p><p><strong>Methods: </strong>CT referral data from 6356 patients were retrospectively analyzed. Recommendations were generated by the ESR iGuide, LLMs, and independent experts, and evaluated for accuracy, precision, recall, F1 score, and Cohen's kappa across medical test, organ, and contrast predictions. Statistical analysis included demographic stratification, confidence intervals, and p-values to ensure robust comparisons.</p><p><strong>Results: </strong>Independent experts achieved the highest accuracy (92.4%) for medical test justification, surpassing GPT-4 (88.8%) and Claude-3 Haiku (85.2%). For organ predictions, LLMs performed comparably to experts, achieving accuracies of 75.3-77.8% versus 82.6%. For contrast predictions, GPT-4 showed the highest accuracy (57.4%) among models, while Claude demonstrated poor agreement with guidelines (kappa = 0.006).</p><p><strong>Conclusion: </strong>Independent experts remain the most reliable, but LLMs show potential for optimization, particularly in organ prediction. A hybrid human-AI approach could enhance CT referral appropriateness and utilization. Further research should focus on improving LLM performance and exploring their integration into clinical workflows.</p><p><strong>Key points: </strong>Question Can GPT-4 and Claude-3 Haiku justify CT referrals as accurately as independent experts, using the ESR iGuide as the gold standard? Findings Independent experts outperformed large language models in test justification. GPT-4 and Claude-3 showed comparable organ prediction but struggled with contrast selection, limiting full automation. Clinical relevance While independent experts remain most reliable, integrating AI with expert oversight may improve CT referral appropriateness, optimizing resource allocation and enhancing clinical decision-making.</p>","PeriodicalId":12076,"journal":{"name":"European Radiology","volume":" ","pages":"6150-6159"},"PeriodicalIF":4.7000,"publicationDate":"2025-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12417242/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparison of CT referral justification using clinical decision support and large language models in a large European cohort.\",\"authors\":\"Mor Saban, Yaniv Alon, Osnat Luxenburg, Clara Singer, Monika Hierath, Alexandra Karoussou Schreiner, Boris Brkljačić, Jacob Sosna\",\"doi\":\"10.1007/s00330-025-11608-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Ensuring appropriate use of CT scans is critical for patient safety and resource optimization. Decision support tools and artificial intelligence (AI), such as large language models (LLMs), have the potential to improve CT referral justification, yet require rigorous evaluation against established standards and expert assessments.</p><p><strong>Aim: </strong>To evaluate the performance of LLMs (Generation Pre-trained Transformer 4 (GPT-4) and Claude-3 Haiku) and independent experts in justifying CT referrals compared to the ESR iGuide clinical decision support system as the reference standard.</p><p><strong>Methods: </strong>CT referral data from 6356 patients were retrospectively analyzed. Recommendations were generated by the ESR iGuide, LLMs, and independent experts, and evaluated for accuracy, precision, recall, F1 score, and Cohen's kappa across medical test, organ, and contrast predictions. Statistical analysis included demographic stratification, confidence intervals, and p-values to ensure robust comparisons.</p><p><strong>Results: </strong>Independent experts achieved the highest accuracy (92.4%) for medical test justification, surpassing GPT-4 (88.8%) and Claude-3 Haiku (85.2%). For organ predictions, LLMs performed comparably to experts, achieving accuracies of 75.3-77.8% versus 82.6%. For contrast predictions, GPT-4 showed the highest accuracy (57.4%) among models, while Claude demonstrated poor agreement with guidelines (kappa = 0.006).</p><p><strong>Conclusion: </strong>Independent experts remain the most reliable, but LLMs show potential for optimization, particularly in organ prediction. A hybrid human-AI approach could enhance CT referral appropriateness and utilization. Further research should focus on improving LLM performance and exploring their integration into clinical workflows.</p><p><strong>Key points: </strong>Question Can GPT-4 and Claude-3 Haiku justify CT referrals as accurately as independent experts, using the ESR iGuide as the gold standard? Findings Independent experts outperformed large language models in test justification. GPT-4 and Claude-3 showed comparable organ prediction but struggled with contrast selection, limiting full automation. Clinical relevance While independent experts remain most reliable, integrating AI with expert oversight may improve CT referral appropriateness, optimizing resource allocation and enhancing clinical decision-making.</p>\",\"PeriodicalId\":12076,\"journal\":{\"name\":\"European Radiology\",\"volume\":\" \",\"pages\":\"6150-6159\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2025-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12417242/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"European Radiology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1007/s00330-025-11608-y\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/27 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00330-025-11608-y","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/27 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
Comparison of CT referral justification using clinical decision support and large language models in a large European cohort.
Background: Ensuring appropriate use of CT scans is critical for patient safety and resource optimization. Decision support tools and artificial intelligence (AI), such as large language models (LLMs), have the potential to improve CT referral justification, yet require rigorous evaluation against established standards and expert assessments.
Aim: To evaluate the performance of LLMs (Generation Pre-trained Transformer 4 (GPT-4) and Claude-3 Haiku) and independent experts in justifying CT referrals compared to the ESR iGuide clinical decision support system as the reference standard.
Methods: CT referral data from 6356 patients were retrospectively analyzed. Recommendations were generated by the ESR iGuide, LLMs, and independent experts, and evaluated for accuracy, precision, recall, F1 score, and Cohen's kappa across medical test, organ, and contrast predictions. Statistical analysis included demographic stratification, confidence intervals, and p-values to ensure robust comparisons.
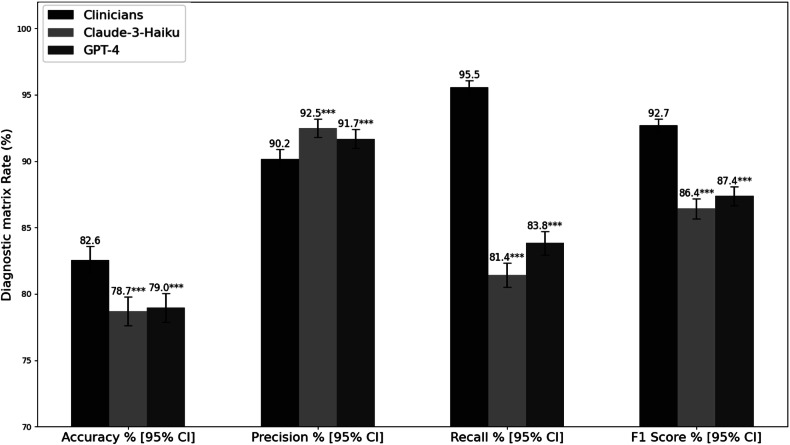
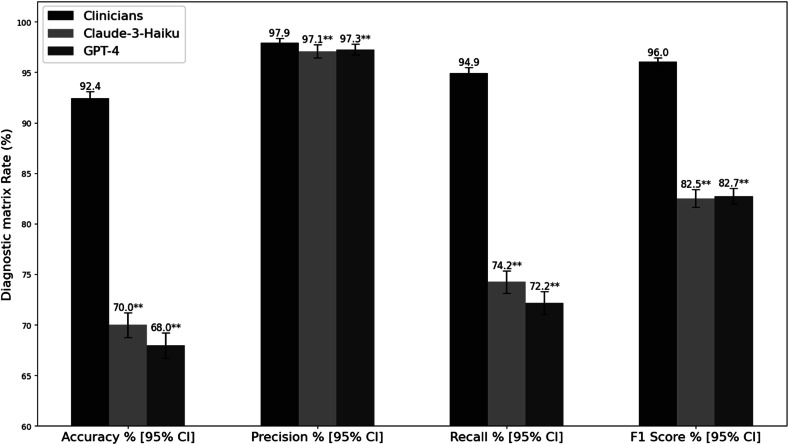
Results: Independent experts achieved the highest accuracy (92.4%) for medical test justification, surpassing GPT-4 (88.8%) and Claude-3 Haiku (85.2%). For organ predictions, LLMs performed comparably to experts, achieving accuracies of 75.3-77.8% versus 82.6%. For contrast predictions, GPT-4 showed the highest accuracy (57.4%) among models, while Claude demonstrated poor agreement with guidelines (kappa = 0.006).
Conclusion: Independent experts remain the most reliable, but LLMs show potential for optimization, particularly in organ prediction. A hybrid human-AI approach could enhance CT referral appropriateness and utilization. Further research should focus on improving LLM performance and exploring their integration into clinical workflows.
Key points: Question Can GPT-4 and Claude-3 Haiku justify CT referrals as accurately as independent experts, using the ESR iGuide as the gold standard? Findings Independent experts outperformed large language models in test justification. GPT-4 and Claude-3 showed comparable organ prediction but struggled with contrast selection, limiting full automation. Clinical relevance While independent experts remain most reliable, integrating AI with expert oversight may improve CT referral appropriateness, optimizing resource allocation and enhancing clinical decision-making.
期刊介绍:
European Radiology (ER) continuously updates scientific knowledge in radiology by publication of strong original articles and state-of-the-art reviews written by leading radiologists. A well balanced combination of review articles, original papers, short communications from European radiological congresses and information on society matters makes ER an indispensable source for current information in this field.
This is the Journal of the European Society of Radiology, and the official journal of a number of societies.
From 2004-2008 supplements to European Radiology were published under its companion, European Radiology Supplements, ISSN 1613-3749.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


