{"title":"使用大型语言模型生成患者教育材料:范围审查。","authors":"Alhasan AlSammarraie, Mowafa Househ","doi":"10.5455/aim.2024.33.4-10","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Patient Education is a healthcare concept that involves educating the public with evidence-based medical information. This information surges their capabilities to promote a healthier life and better manage their conditions. LLM platforms have recently been introduced as powerful NLPs capable of producing human-sounding text and by extension patient education materials.</p><p><strong>Objective: </strong>This study aims to conduct a scoping review to systematically map the existing literature on the use of LLMs for generating patient education materials.</p><p><strong>Methods: </strong>The study followed JBI guidelines, searching five databases using set inclusion/exclusion criteria. A RAG-inspired framework was employed to extract the variables followed by a manual check to verify accuracy of extractions. In total, 21 variables were identified and grouped into five themes: Study Demographics, LLM Characteristics, Prompt-Related Variables, PEM Assessment, and Comparative Outcomes.</p><p><strong>Results: </strong>Results were reported from 69 studies. The United States contributed the largest number of studies. LLM models such as ChatGPT-4, ChatGPT-3.5, and Bard were the most investigated. Most studies evaluated the accuracy of LLM responses and the readability of LLM responses. Only 3 studies implemented external knowledge bases leveraging a RAG architecture. All studies except 3 conducted prompting in English. ChatGPT-4 was found to provide the most accurate responses in comparison with other models.</p><p><strong>Conclusion: </strong>This review examined studies comparing large language models for generating patient education materials. ChatGPT-3.5 and ChatGPT-4 were the most evaluated. Accuracy and readability of responses were the main metrics of evaluation, while few studies used assessment frameworks, retrieval-augmented methods, or explored non-English cases.</p>","PeriodicalId":7074,"journal":{"name":"Acta Informatica Medica","volume":"33 1","pages":"4-10"},"PeriodicalIF":0.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11986337/pdf/","citationCount":"0","resultStr":"{\"title\":\"The Use of Large Language Models in Generating Patient Education Materials: a Scoping Review.\",\"authors\":\"Alhasan AlSammarraie, Mowafa Househ\",\"doi\":\"10.5455/aim.2024.33.4-10\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Patient Education is a healthcare concept that involves educating the public with evidence-based medical information. This information surges their capabilities to promote a healthier life and better manage their conditions. LLM platforms have recently been introduced as powerful NLPs capable of producing human-sounding text and by extension patient education materials.</p><p><strong>Objective: </strong>This study aims to conduct a scoping review to systematically map the existing literature on the use of LLMs for generating patient education materials.</p><p><strong>Methods: </strong>The study followed JBI guidelines, searching five databases using set inclusion/exclusion criteria. A RAG-inspired framework was employed to extract the variables followed by a manual check to verify accuracy of extractions. In total, 21 variables were identified and grouped into five themes: Study Demographics, LLM Characteristics, Prompt-Related Variables, PEM Assessment, and Comparative Outcomes.</p><p><strong>Results: </strong>Results were reported from 69 studies. The United States contributed the largest number of studies. LLM models such as ChatGPT-4, ChatGPT-3.5, and Bard were the most investigated. Most studies evaluated the accuracy of LLM responses and the readability of LLM responses. Only 3 studies implemented external knowledge bases leveraging a RAG architecture. All studies except 3 conducted prompting in English. ChatGPT-4 was found to provide the most accurate responses in comparison with other models.</p><p><strong>Conclusion: </strong>This review examined studies comparing large language models for generating patient education materials. ChatGPT-3.5 and ChatGPT-4 were the most evaluated. Accuracy and readability of responses were the main metrics of evaluation, while few studies used assessment frameworks, retrieval-augmented methods, or explored non-English cases.</p>\",\"PeriodicalId\":7074,\"journal\":{\"name\":\"Acta Informatica Medica\",\"volume\":\"33 1\",\"pages\":\"4-10\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11986337/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Acta Informatica Medica\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.5455/aim.2024.33.4-10\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Acta Informatica Medica","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5455/aim.2024.33.4-10","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
The Use of Large Language Models in Generating Patient Education Materials: a Scoping Review.
Background: Patient Education is a healthcare concept that involves educating the public with evidence-based medical information. This information surges their capabilities to promote a healthier life and better manage their conditions. LLM platforms have recently been introduced as powerful NLPs capable of producing human-sounding text and by extension patient education materials.
Objective: This study aims to conduct a scoping review to systematically map the existing literature on the use of LLMs for generating patient education materials.
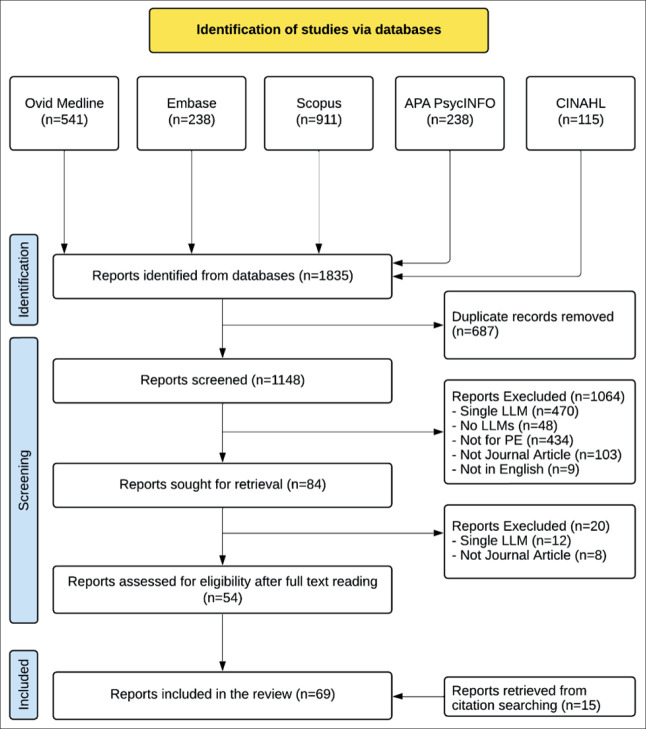
Methods: The study followed JBI guidelines, searching five databases using set inclusion/exclusion criteria. A RAG-inspired framework was employed to extract the variables followed by a manual check to verify accuracy of extractions. In total, 21 variables were identified and grouped into five themes: Study Demographics, LLM Characteristics, Prompt-Related Variables, PEM Assessment, and Comparative Outcomes.
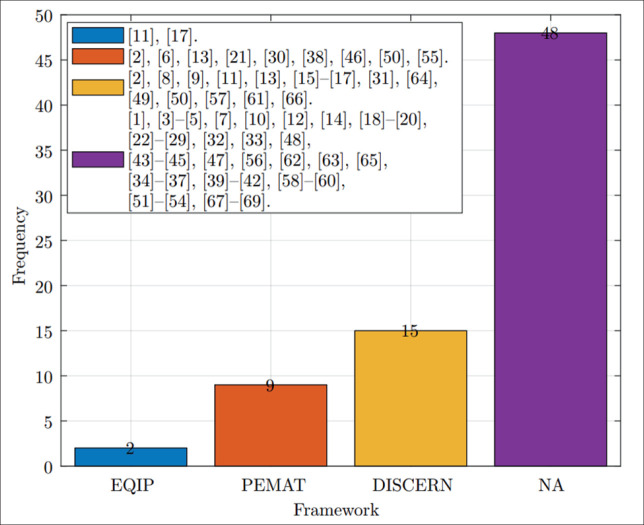
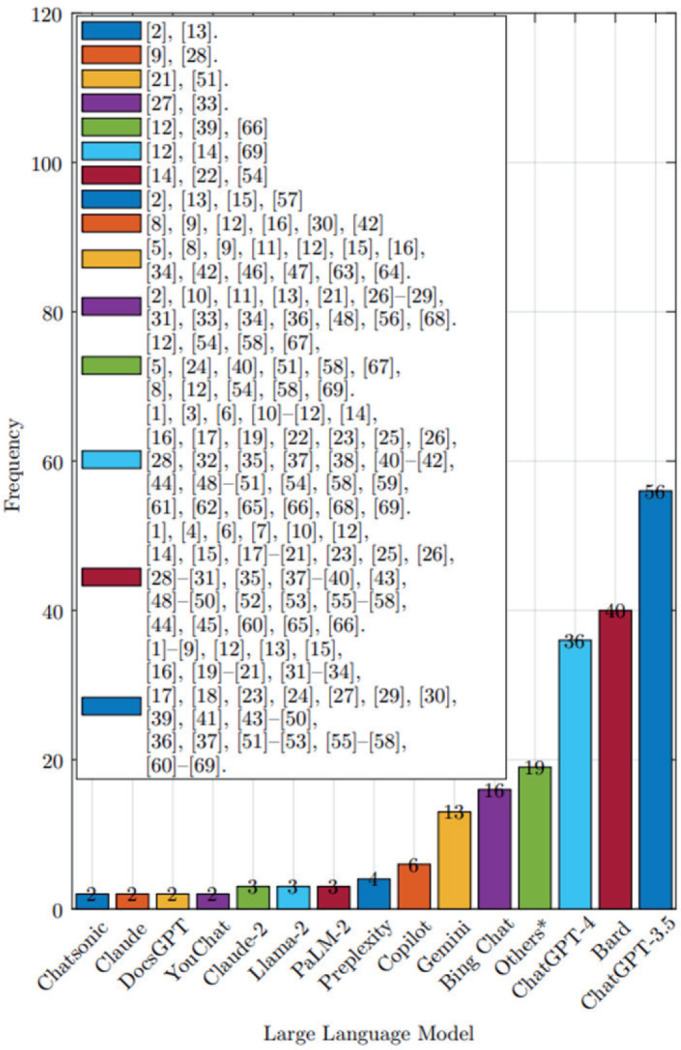
Results: Results were reported from 69 studies. The United States contributed the largest number of studies. LLM models such as ChatGPT-4, ChatGPT-3.5, and Bard were the most investigated. Most studies evaluated the accuracy of LLM responses and the readability of LLM responses. Only 3 studies implemented external knowledge bases leveraging a RAG architecture. All studies except 3 conducted prompting in English. ChatGPT-4 was found to provide the most accurate responses in comparison with other models.
Conclusion: This review examined studies comparing large language models for generating patient education materials. ChatGPT-3.5 and ChatGPT-4 were the most evaluated. Accuracy and readability of responses were the main metrics of evaluation, while few studies used assessment frameworks, retrieval-augmented methods, or explored non-English cases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


