Jun Mencius, Wenjun Chen, Youqi Zheng, Tingyi An, Yongguo Yu, Kun Sun, Huijuan Feng, Zhixing Feng
{"title":"从纳米孔测序数据的FASTQ文件中恢复流动池类型和基调用器配置","authors":"Jun Mencius, Wenjun Chen, Youqi Zheng, Tingyi An, Yongguo Yu, Kun Sun, Huijuan Feng, Zhixing Feng","doi":"10.1038/s41467-025-59378-x","DOIUrl":null,"url":null,"abstract":"<p>As nanopore sequencing has been widely adopted, data accumulation has surged, resulting in over 700,000 public datasets. While these data hold immense potential for advancing genomic research, their utility is compromised by the absence of flowcell type and basecaller configuration in about 85% of the data and associated publications. These parameters are essential for many analysis algorithms, and their misapplication can lead to significant drops in performance. To address this issue, we present LongBow, designed to infer flowcell type and basecaller configuration directly from the base quality value patterns of FASTQ files. LongBow has been tested on 66 in-house basecalled FAST5/POD5 datasets and 1989 public FASTQ datasets, achieving accuracies of 95.33% and 91.45%, respectively. We demonstrate its utility by reanalyzing nanopore sequencing data from the COVID-19 Genomics UK (COG-UK) project. The results show that LongBow is essential for reproducing reported genomic variants and, through a LongBow-based analysis pipeline, we discovered substantially more functionally important variants while improving accuracy in lineage assignment. Overall, LongBow is poised to play a critical role in maximizing the utility of public nanopore sequencing data, while significantly enhancing the reproducibility of related research.</p>","PeriodicalId":19066,"journal":{"name":"Nature Communications","volume":"96 1","pages":""},"PeriodicalIF":15.7000,"publicationDate":"2025-05-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Restoring flowcell type and basecaller configuration from FASTQ files of nanopore sequencing data\",\"authors\":\"Jun Mencius, Wenjun Chen, Youqi Zheng, Tingyi An, Yongguo Yu, Kun Sun, Huijuan Feng, Zhixing Feng\",\"doi\":\"10.1038/s41467-025-59378-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>As nanopore sequencing has been widely adopted, data accumulation has surged, resulting in over 700,000 public datasets. While these data hold immense potential for advancing genomic research, their utility is compromised by the absence of flowcell type and basecaller configuration in about 85% of the data and associated publications. These parameters are essential for many analysis algorithms, and their misapplication can lead to significant drops in performance. To address this issue, we present LongBow, designed to infer flowcell type and basecaller configuration directly from the base quality value patterns of FASTQ files. LongBow has been tested on 66 in-house basecalled FAST5/POD5 datasets and 1989 public FASTQ datasets, achieving accuracies of 95.33% and 91.45%, respectively. We demonstrate its utility by reanalyzing nanopore sequencing data from the COVID-19 Genomics UK (COG-UK) project. The results show that LongBow is essential for reproducing reported genomic variants and, through a LongBow-based analysis pipeline, we discovered substantially more functionally important variants while improving accuracy in lineage assignment. Overall, LongBow is poised to play a critical role in maximizing the utility of public nanopore sequencing data, while significantly enhancing the reproducibility of related research.</p>\",\"PeriodicalId\":19066,\"journal\":{\"name\":\"Nature Communications\",\"volume\":\"96 1\",\"pages\":\"\"},\"PeriodicalIF\":15.7000,\"publicationDate\":\"2025-05-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Communications\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41467-025-59378-x\",\"RegionNum\":1,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Communications","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41467-025-59378-x","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
摘要
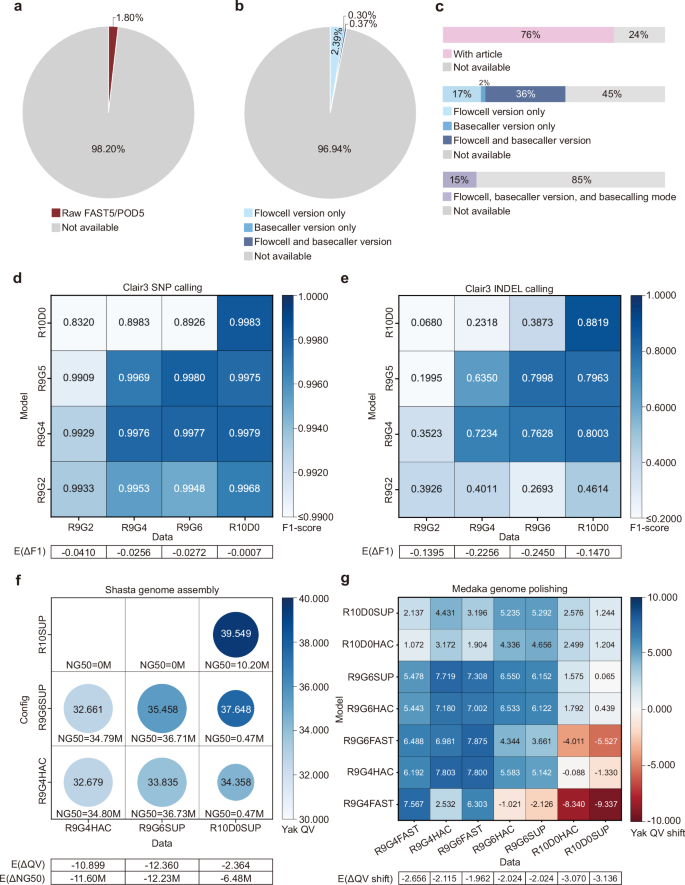
随着纳米孔测序的广泛应用,数据积累激增,公共数据集超过70万。虽然这些数据在推进基因组研究方面具有巨大的潜力,但由于在85%的数据和相关出版物中缺乏流动细胞类型和基召唤器配置,它们的效用受到了影响。这些参数对于许多分析算法都是必不可少的,它们的误用会导致性能的显著下降。为了解决这个问题,我们提出了LongBow,旨在直接从FASTQ文件的基本质量值模式推断出流动单元类型和基本调用器配置。LongBow在66个内部FAST5/POD5数据集和1989个公共FASTQ数据集上进行了测试,准确率分别达到95.33%和91.45%。我们通过重新分析来自COVID-19 Genomics UK (COG-UK)项目的纳米孔测序数据来证明其实用性。结果表明,LongBow对于再现已报道的基因组变异至关重要,通过基于LongBow的分析管道,我们发现了更多功能重要的变异,同时提高了谱系分配的准确性。总的来说,LongBow将在最大限度地利用公共纳米孔测序数据方面发挥关键作用,同时显著提高相关研究的可重复性。
Restoring flowcell type and basecaller configuration from FASTQ files of nanopore sequencing data
As nanopore sequencing has been widely adopted, data accumulation has surged, resulting in over 700,000 public datasets. While these data hold immense potential for advancing genomic research, their utility is compromised by the absence of flowcell type and basecaller configuration in about 85% of the data and associated publications. These parameters are essential for many analysis algorithms, and their misapplication can lead to significant drops in performance. To address this issue, we present LongBow, designed to infer flowcell type and basecaller configuration directly from the base quality value patterns of FASTQ files. LongBow has been tested on 66 in-house basecalled FAST5/POD5 datasets and 1989 public FASTQ datasets, achieving accuracies of 95.33% and 91.45%, respectively. We demonstrate its utility by reanalyzing nanopore sequencing data from the COVID-19 Genomics UK (COG-UK) project. The results show that LongBow is essential for reproducing reported genomic variants and, through a LongBow-based analysis pipeline, we discovered substantially more functionally important variants while improving accuracy in lineage assignment. Overall, LongBow is poised to play a critical role in maximizing the utility of public nanopore sequencing data, while significantly enhancing the reproducibility of related research.
期刊介绍:
Nature Communications, an open-access journal, publishes high-quality research spanning all areas of the natural sciences. Papers featured in the journal showcase significant advances relevant to specialists in each respective field. With a 2-year impact factor of 16.6 (2022) and a median time of 8 days from submission to the first editorial decision, Nature Communications is committed to rapid dissemination of research findings. As a multidisciplinary journal, it welcomes contributions from biological, health, physical, chemical, Earth, social, mathematical, applied, and engineering sciences, aiming to highlight important breakthroughs within each domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


