{"title":"分子性质预测的知识精馏:可扩展性分析。","authors":"Rahul Sheshanarayana, Fengqi You","doi":"10.1002/advs.202503271","DOIUrl":null,"url":null,"abstract":"<p>Knowledge distillation (KD) is a powerful model compression technique that transfers knowledge from complex teacher models to compact student models, reducing computational costs while preserving predictive accuracy. This study investigated KD's efficacy in molecular property prediction across domain-specific and cross-domain tasks, leveraging state-of-the-art graph neural networks (SchNet, DimeNet++, and TensorNet). In the domain-specific setting, KD improved regression performance across diverse quantum mechanical properties in the QM9 dataset, with DimeNet++ student models achieving up to an 90% improvement in <span></span><math>\n <semantics>\n <msup>\n <mi>R</mi>\n <mn>2</mn>\n </msup>\n <annotation>$R^{2}$</annotation>\n </semantics></math> compared to non-KD baselines. Notably, in certain cases, smaller student models achieved comparable or even superior <span></span><math>\n <semantics>\n <msup>\n <mi>R</mi>\n <mn>2</mn>\n </msup>\n <annotation>$R^{2}$</annotation>\n </semantics></math> improvements while being 2× smaller, highlighting KD's ability to enhance efficiency without sacrificing predictive performance. Cross-domain evaluations further demonstrated KD's adaptability, where embeddings from QM9-trained teacher models enhanced predictions for ESOL (log<i>S</i>) and FreeSolv (Δ<i>G<sub>hyd</sub></i>), with SchNet exhibiting the highest gains of ≈65% in log<i>S</i> predictions. Embedding analysis revealed substantial student-teacher alignment gains, with the relative shift in cosine similarity distribution peaks reaching up to 1.0 across student models. These findings highlighted KD as a robust strategy for enhancing molecular representation learning, with implications for cheminformatics, materials science, and drug discovery.</p>","PeriodicalId":117,"journal":{"name":"Advanced Science","volume":"12 22","pages":""},"PeriodicalIF":14.1000,"publicationDate":"2025-04-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/advs.202503271","citationCount":"0","resultStr":"{\"title\":\"Knowledge Distillation for Molecular Property Prediction: A Scalability Analysis\",\"authors\":\"Rahul Sheshanarayana, Fengqi You\",\"doi\":\"10.1002/advs.202503271\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Knowledge distillation (KD) is a powerful model compression technique that transfers knowledge from complex teacher models to compact student models, reducing computational costs while preserving predictive accuracy. This study investigated KD's efficacy in molecular property prediction across domain-specific and cross-domain tasks, leveraging state-of-the-art graph neural networks (SchNet, DimeNet++, and TensorNet). In the domain-specific setting, KD improved regression performance across diverse quantum mechanical properties in the QM9 dataset, with DimeNet++ student models achieving up to an 90% improvement in <span></span><math>\\n <semantics>\\n <msup>\\n <mi>R</mi>\\n <mn>2</mn>\\n </msup>\\n <annotation>$R^{2}$</annotation>\\n </semantics></math> compared to non-KD baselines. Notably, in certain cases, smaller student models achieved comparable or even superior <span></span><math>\\n <semantics>\\n <msup>\\n <mi>R</mi>\\n <mn>2</mn>\\n </msup>\\n <annotation>$R^{2}$</annotation>\\n </semantics></math> improvements while being 2× smaller, highlighting KD's ability to enhance efficiency without sacrificing predictive performance. Cross-domain evaluations further demonstrated KD's adaptability, where embeddings from QM9-trained teacher models enhanced predictions for ESOL (log<i>S</i>) and FreeSolv (Δ<i>G<sub>hyd</sub></i>), with SchNet exhibiting the highest gains of ≈65% in log<i>S</i> predictions. Embedding analysis revealed substantial student-teacher alignment gains, with the relative shift in cosine similarity distribution peaks reaching up to 1.0 across student models. These findings highlighted KD as a robust strategy for enhancing molecular representation learning, with implications for cheminformatics, materials science, and drug discovery.</p>\",\"PeriodicalId\":117,\"journal\":{\"name\":\"Advanced Science\",\"volume\":\"12 22\",\"pages\":\"\"},\"PeriodicalIF\":14.1000,\"publicationDate\":\"2025-04-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/advs.202503271\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advanced Science\",\"FirstCategoryId\":\"88\",\"ListUrlMain\":\"https://advanced.onlinelibrary.wiley.com/doi/10.1002/advs.202503271\",\"RegionNum\":1,\"RegionCategory\":\"材料科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advanced Science","FirstCategoryId":"88","ListUrlMain":"https://advanced.onlinelibrary.wiley.com/doi/10.1002/advs.202503271","RegionNum":1,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
Knowledge Distillation for Molecular Property Prediction: A Scalability Analysis
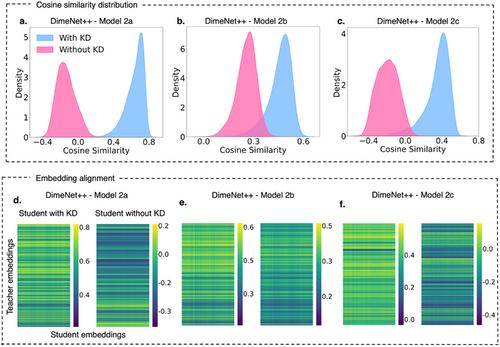
Knowledge distillation (KD) is a powerful model compression technique that transfers knowledge from complex teacher models to compact student models, reducing computational costs while preserving predictive accuracy. This study investigated KD's efficacy in molecular property prediction across domain-specific and cross-domain tasks, leveraging state-of-the-art graph neural networks (SchNet, DimeNet++, and TensorNet). In the domain-specific setting, KD improved regression performance across diverse quantum mechanical properties in the QM9 dataset, with DimeNet++ student models achieving up to an 90% improvement in compared to non-KD baselines. Notably, in certain cases, smaller student models achieved comparable or even superior improvements while being 2× smaller, highlighting KD's ability to enhance efficiency without sacrificing predictive performance. Cross-domain evaluations further demonstrated KD's adaptability, where embeddings from QM9-trained teacher models enhanced predictions for ESOL (logS) and FreeSolv (ΔGhyd), with SchNet exhibiting the highest gains of ≈65% in logS predictions. Embedding analysis revealed substantial student-teacher alignment gains, with the relative shift in cosine similarity distribution peaks reaching up to 1.0 across student models. These findings highlighted KD as a robust strategy for enhancing molecular representation learning, with implications for cheminformatics, materials science, and drug discovery.
期刊介绍:
Advanced Science is a prestigious open access journal that focuses on interdisciplinary research in materials science, physics, chemistry, medical and life sciences, and engineering. The journal aims to promote cutting-edge research by employing a rigorous and impartial review process. It is committed to presenting research articles with the highest quality production standards, ensuring maximum accessibility of top scientific findings. With its vibrant and innovative publication platform, Advanced Science seeks to revolutionize the dissemination and organization of scientific knowledge.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


