{"title":"论程序切片在代码检查过程中漏洞检测中的作用。","authors":"Aurora Papotti, Katja Tuma, Fabio Massacci","doi":"10.1007/s10664-025-10636-y","DOIUrl":null,"url":null,"abstract":"<p><p>Slicing is a fault localization technique that has been proposed to support debugging and program comprehension. Yet, its empirical effectiveness during code inspection by humans has received limited attention. The goal of our study is two-fold. First, we aim to define what it means for a code reviewer to identify the vulnerable lines correctly. Second, we investigate whether reducing the number of to-be-inspected lines by method-level slicing supports code reviewers in detecting security vulnerabilities. We propose a novel approach based on the notion of a <math><mi>δ</mi></math> -neighborhood (intuitively based on the idea of the context size of the command git diff) to define correctly identified lines. Then, we conducted a multi-year controlled experiment (2017-2023) in which MSc students attending security courses ( <math><mrow><mi>n</mi> <mo>=</mo> <mn>236</mn></mrow> </math> ) were tasked with identifying vulnerable lines in original or sliced Java files from Apache Tomcat. We provide perfect seed lines for a slicing algorithm to control for confounding factors. Each treatment differs in the pair (Vulnerability, Original/Sliced) with a balanced design with vulnerabilities from the OWASP Top 10 2017: A1 (Injection), A5 (Broken Access Control), A6 (Security Misconfiguration), and A7 (Cross-Site Scripting). To generate smaller slices for human consumption, we used a variant of intra-procedural thin slicing. We report the results for <math><mrow><mi>δ</mi> <mo>=</mo> <mn>0</mn></mrow> </math> which corresponds to exactly matching the vulnerable ground truth lines, and <math><mrow><mi>δ</mi> <mo>=</mo> <mn>3</mn></mrow> </math> which represents the scenario of identifying the vulnerable area. For both cases, we found that slicing helps in 'finding something' (the participant has found at least some vulnerable lines) as opposed to 'finding nothing'. For the case of <math><mrow><mi>δ</mi> <mo>=</mo> <mn>0</mn></mrow> </math> analyzing a slice and analyzing the original file are statistically equivalent from the perspective of lines found by those who found something. With <math><mrow><mi>δ</mi> <mo>=</mo> <mn>3</mn></mrow> </math> slicing helps to find more vulnerabilities compared to analyzing an original file, as we would normally expect. Given the type of population, additional experiments are necessary to be generalized to experienced developers.</p>","PeriodicalId":11525,"journal":{"name":"Empirical Software Engineering","volume":"30 3","pages":"93"},"PeriodicalIF":3.6000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11972194/pdf/","citationCount":"0","resultStr":"{\"title\":\"On the effects of program slicing for vulnerability detection during code inspection.\",\"authors\":\"Aurora Papotti, Katja Tuma, Fabio Massacci\",\"doi\":\"10.1007/s10664-025-10636-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Slicing is a fault localization technique that has been proposed to support debugging and program comprehension. Yet, its empirical effectiveness during code inspection by humans has received limited attention. The goal of our study is two-fold. First, we aim to define what it means for a code reviewer to identify the vulnerable lines correctly. Second, we investigate whether reducing the number of to-be-inspected lines by method-level slicing supports code reviewers in detecting security vulnerabilities. We propose a novel approach based on the notion of a <math><mi>δ</mi></math> -neighborhood (intuitively based on the idea of the context size of the command git diff) to define correctly identified lines. Then, we conducted a multi-year controlled experiment (2017-2023) in which MSc students attending security courses ( <math><mrow><mi>n</mi> <mo>=</mo> <mn>236</mn></mrow> </math> ) were tasked with identifying vulnerable lines in original or sliced Java files from Apache Tomcat. We provide perfect seed lines for a slicing algorithm to control for confounding factors. Each treatment differs in the pair (Vulnerability, Original/Sliced) with a balanced design with vulnerabilities from the OWASP Top 10 2017: A1 (Injection), A5 (Broken Access Control), A6 (Security Misconfiguration), and A7 (Cross-Site Scripting). To generate smaller slices for human consumption, we used a variant of intra-procedural thin slicing. We report the results for <math><mrow><mi>δ</mi> <mo>=</mo> <mn>0</mn></mrow> </math> which corresponds to exactly matching the vulnerable ground truth lines, and <math><mrow><mi>δ</mi> <mo>=</mo> <mn>3</mn></mrow> </math> which represents the scenario of identifying the vulnerable area. For both cases, we found that slicing helps in 'finding something' (the participant has found at least some vulnerable lines) as opposed to 'finding nothing'. For the case of <math><mrow><mi>δ</mi> <mo>=</mo> <mn>0</mn></mrow> </math> analyzing a slice and analyzing the original file are statistically equivalent from the perspective of lines found by those who found something. With <math><mrow><mi>δ</mi> <mo>=</mo> <mn>3</mn></mrow> </math> slicing helps to find more vulnerabilities compared to analyzing an original file, as we would normally expect. Given the type of population, additional experiments are necessary to be generalized to experienced developers.</p>\",\"PeriodicalId\":11525,\"journal\":{\"name\":\"Empirical Software Engineering\",\"volume\":\"30 3\",\"pages\":\"93\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11972194/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Empirical Software Engineering\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10664-025-10636-y\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Empirical Software Engineering","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10664-025-10636-y","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/5 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
On the effects of program slicing for vulnerability detection during code inspection.
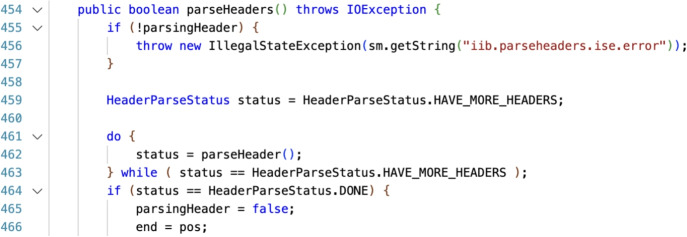
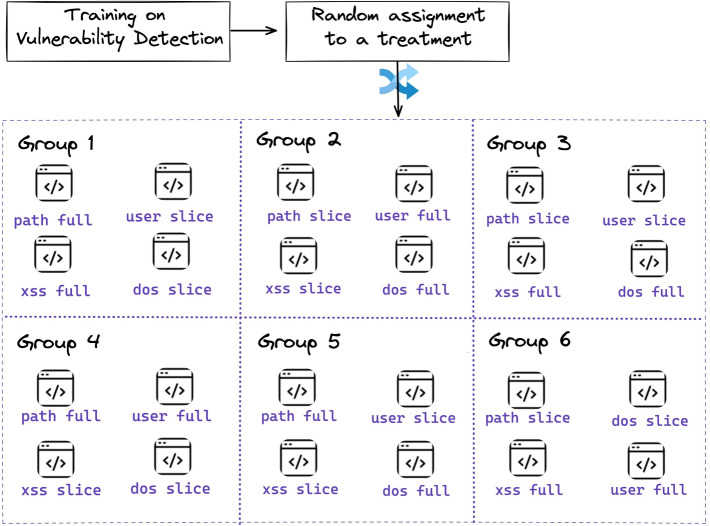
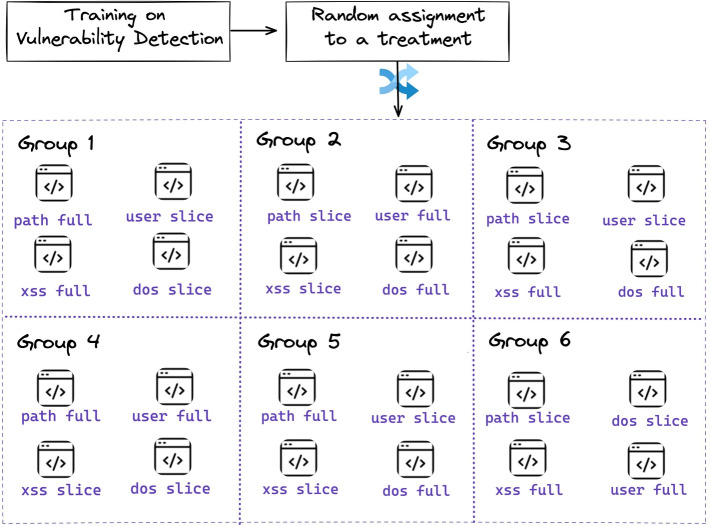
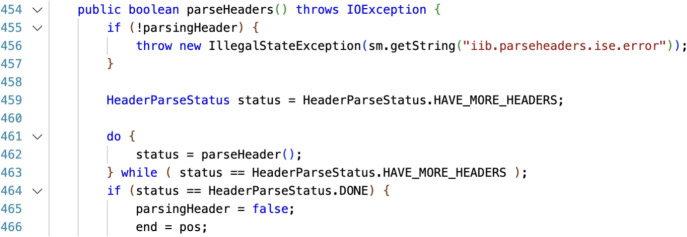
Slicing is a fault localization technique that has been proposed to support debugging and program comprehension. Yet, its empirical effectiveness during code inspection by humans has received limited attention. The goal of our study is two-fold. First, we aim to define what it means for a code reviewer to identify the vulnerable lines correctly. Second, we investigate whether reducing the number of to-be-inspected lines by method-level slicing supports code reviewers in detecting security vulnerabilities. We propose a novel approach based on the notion of a -neighborhood (intuitively based on the idea of the context size of the command git diff) to define correctly identified lines. Then, we conducted a multi-year controlled experiment (2017-2023) in which MSc students attending security courses ( ) were tasked with identifying vulnerable lines in original or sliced Java files from Apache Tomcat. We provide perfect seed lines for a slicing algorithm to control for confounding factors. Each treatment differs in the pair (Vulnerability, Original/Sliced) with a balanced design with vulnerabilities from the OWASP Top 10 2017: A1 (Injection), A5 (Broken Access Control), A6 (Security Misconfiguration), and A7 (Cross-Site Scripting). To generate smaller slices for human consumption, we used a variant of intra-procedural thin slicing. We report the results for which corresponds to exactly matching the vulnerable ground truth lines, and which represents the scenario of identifying the vulnerable area. For both cases, we found that slicing helps in 'finding something' (the participant has found at least some vulnerable lines) as opposed to 'finding nothing'. For the case of analyzing a slice and analyzing the original file are statistically equivalent from the perspective of lines found by those who found something. With slicing helps to find more vulnerabilities compared to analyzing an original file, as we would normally expect. Given the type of population, additional experiments are necessary to be generalized to experienced developers.
期刊介绍:
Empirical Software Engineering provides a forum for applied software engineering research with a strong empirical component, and a venue for publishing empirical results relevant to both researchers and practitioners. Empirical studies presented here usually involve the collection and analysis of data and experience that can be used to characterize, evaluate and reveal relationships between software development deliverables, practices, and technologies. Over time, it is expected that such empirical results will form a body of knowledge leading to widely accepted and well-formed theories.
The journal also offers industrial experience reports detailing the application of software technologies - processes, methods, or tools - and their effectiveness in industrial settings.
Empirical Software Engineering promotes the publication of industry-relevant research, to address the significant gap between research and practice.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


