Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, Hany Awadalla, Julia Gong, Houdong Hu, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Yu Gu, Cliff Wong, Mu Wei, Tristan Naumann, Muhao Chen, Matthew P. Lungren, Akshay Chaudhari, Serena Yeung-Levy, Curtis P. Langlotz, Sheng Wang, Hoifung Poon
{"title":"临床可及的小型多模态放射学模型和胸部x线表现的评价指标","authors":"Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, Hany Awadalla, Julia Gong, Houdong Hu, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Yu Gu, Cliff Wong, Mu Wei, Tristan Naumann, Muhao Chen, Matthew P. Lungren, Akshay Chaudhari, Serena Yeung-Levy, Curtis P. Langlotz, Sheng Wang, Hoifung Poon","doi":"10.1038/s41467-025-58344-x","DOIUrl":null,"url":null,"abstract":"<p>Large foundation models show promise in biomedicine but face challenges in clinical use due to performance gaps, accessibility, cost, and lack of scalable evaluation. Here we show that open-source small multimodal models can bridge these gaps in radiology by generating free-text findings from chest X-ray images. Our data-centric approach leverages 697K curated radiology image-text pairs to train a specialized, domain-adapted chest X-ray encoder. We integrate this encoder with pre-trained language models via a lightweight adapter that aligns image and text modalities. To enable robust, clinically relevant evaluation, we develop and validate CheXprompt, a GPT-4-based metric for assessing factual accuracy aligned with radiologists’ evaluations. Benchmarked with CheXprompt and other standard factuality metrics, LLaVA-Rad (7B) achieves state-of-the-art performance, outperforming much larger models like GPT-4V and Med-PaLM M (84B). While not immediately ready for real-time clinical deployment, LLaVA-Rad is a scalable, privacy-preserving and cost-effective step towards clinically adaptable multimodal AI for radiology.</p>","PeriodicalId":19066,"journal":{"name":"Nature Communications","volume":"9 1","pages":""},"PeriodicalIF":15.7000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A clinically accessible small multimodal radiology model and evaluation metric for chest X-ray findings\",\"authors\":\"Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, Hany Awadalla, Julia Gong, Houdong Hu, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Yu Gu, Cliff Wong, Mu Wei, Tristan Naumann, Muhao Chen, Matthew P. Lungren, Akshay Chaudhari, Serena Yeung-Levy, Curtis P. Langlotz, Sheng Wang, Hoifung Poon\",\"doi\":\"10.1038/s41467-025-58344-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Large foundation models show promise in biomedicine but face challenges in clinical use due to performance gaps, accessibility, cost, and lack of scalable evaluation. Here we show that open-source small multimodal models can bridge these gaps in radiology by generating free-text findings from chest X-ray images. Our data-centric approach leverages 697K curated radiology image-text pairs to train a specialized, domain-adapted chest X-ray encoder. We integrate this encoder with pre-trained language models via a lightweight adapter that aligns image and text modalities. To enable robust, clinically relevant evaluation, we develop and validate CheXprompt, a GPT-4-based metric for assessing factual accuracy aligned with radiologists’ evaluations. Benchmarked with CheXprompt and other standard factuality metrics, LLaVA-Rad (7B) achieves state-of-the-art performance, outperforming much larger models like GPT-4V and Med-PaLM M (84B). While not immediately ready for real-time clinical deployment, LLaVA-Rad is a scalable, privacy-preserving and cost-effective step towards clinically adaptable multimodal AI for radiology.</p>\",\"PeriodicalId\":19066,\"journal\":{\"name\":\"Nature Communications\",\"volume\":\"9 1\",\"pages\":\"\"},\"PeriodicalIF\":15.7000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Communications\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41467-025-58344-x\",\"RegionNum\":1,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Communications","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41467-025-58344-x","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
摘要
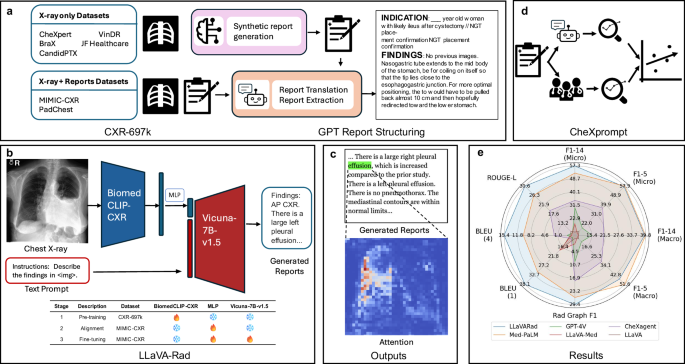
大型基础模型在生物医学领域显示出前景,但由于性能差距、可及性、成本和缺乏可扩展的评估,在临床应用中面临挑战。在这里,我们展示了开源的小型多模态模型可以通过从胸部x射线图像中生成自由文本结果来弥补放射学中的这些空白。我们以数据为中心的方法利用697K编排的放射学图像-文本对来训练一个专门的、适应领域的胸部x射线编码器。我们通过一个轻量级适配器将这个编码器与预训练的语言模型集成在一起,该适配器可以对齐图像和文本模式。为了实现可靠的临床相关评估,我们开发并验证了CheXprompt,这是一种基于gpt -4的指标,用于评估与放射科医生评估一致的事实准确性。通过对CheXprompt和其他标准性能指标进行基准测试,LLaVA-Rad (7B)达到了最先进的性能,优于GPT-4V和Med-PaLM M (84B)等更大的型号。虽然不能立即为实时临床部署做好准备,但LLaVA-Rad是一种可扩展、隐私保护和经济高效的放射学临床适应性多模式人工智能。
A clinically accessible small multimodal radiology model and evaluation metric for chest X-ray findings
Large foundation models show promise in biomedicine but face challenges in clinical use due to performance gaps, accessibility, cost, and lack of scalable evaluation. Here we show that open-source small multimodal models can bridge these gaps in radiology by generating free-text findings from chest X-ray images. Our data-centric approach leverages 697K curated radiology image-text pairs to train a specialized, domain-adapted chest X-ray encoder. We integrate this encoder with pre-trained language models via a lightweight adapter that aligns image and text modalities. To enable robust, clinically relevant evaluation, we develop and validate CheXprompt, a GPT-4-based metric for assessing factual accuracy aligned with radiologists’ evaluations. Benchmarked with CheXprompt and other standard factuality metrics, LLaVA-Rad (7B) achieves state-of-the-art performance, outperforming much larger models like GPT-4V and Med-PaLM M (84B). While not immediately ready for real-time clinical deployment, LLaVA-Rad is a scalable, privacy-preserving and cost-effective step towards clinically adaptable multimodal AI for radiology.
期刊介绍:
Nature Communications, an open-access journal, publishes high-quality research spanning all areas of the natural sciences. Papers featured in the journal showcase significant advances relevant to specialists in each respective field. With a 2-year impact factor of 16.6 (2022) and a median time of 8 days from submission to the first editorial decision, Nature Communications is committed to rapid dissemination of research findings. As a multidisciplinary journal, it welcomes contributions from biological, health, physical, chemical, Earth, social, mathematical, applied, and engineering sciences, aiming to highlight important breakthroughs within each domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


